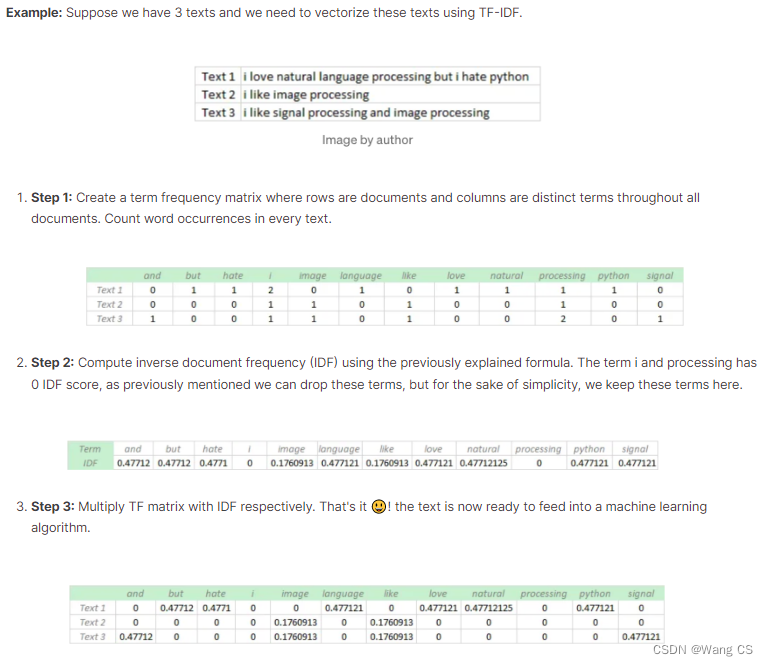
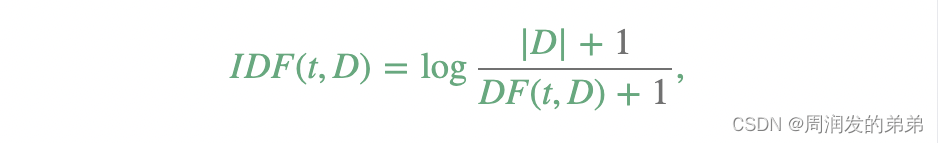TF(Term Frequency)和TF-IDF(Term Frequency-Inverse Document Frequency)都是用于文本挖掘和信息检索的统计方法,用于评估一个词在文档或文档集合中的重要性。
一.TF(Term Frequency)
1.定义
- 词频(Term Frequency,TF):衡量一个词在一个文档中出现的频率。通常,TF值越高,表示该词在文档中越重要。
2.计算公式
TF ( t , d ) = 词t在文档d中出现的次数 文档d中所有词的总数 \text{TF}(t, d) = \frac{\text{词t在文档d中出现的次数}}{\text{文档d中所有词的总数}} TF(t,d)=文档d中所有词的总数词t在文档d中出现的次数
3.特点
局部性:TF只考虑单个文档,不考虑该词在整个文档集合中的分布情况。
简单性:TF计算简单,只需统计词在文档中的出现次数。
二.TF-IDF(Term Frequency-Inverse Document Frequency)
1.定义
- 词频-逆文档频率(Term Frequency-Inverse Document Frequency,TF-IDF):是一种衡量词重要性的方法,综合考虑了词在单个文档中的频率和词在整个文档集合中的稀有程度。
2.计算公式
TF-IDF ( t , d , D ) = TF ( t , d ) × IDF ( t , D ) \text{TF-IDF}(t, d, D) = \text{TF}(t, d) \times \text{IDF}(t, D) TF-IDF(t,d,D)=TF(t,d)×IDF(t,D)
其中,
IDF ( t , D ) = log ( 1 + N 1 + 包含词t的文档数 ) \text{IDF}(t, D) = \log \left( \frac{1+N}{1 + \text{包含词t的文档数}} \right) IDF(t,D)=log(1+包含词t的文档数1+N)
N N N是文档集合中的文档总数。
包含词t的文档数 \text{包含词t的文档数} 包含词t的文档数是词 t \text{t} t在文档集合 D D D中出现的文档数。
3.特点
全局性:TF-IDF考虑了词在整个文档集合中的分布情况,通过IDF降低那些在很多文档中都出现的常见词的重要性。
准确性:TF-IDF在衡量词的权重时更为准确,因为它既考虑了词在单个文档中的频率(TF),也考虑了词在整个文档集合中的稀有程度(IDF)。
三.异同点
1.相同点
目的:两者都用于衡量词在文档中的重要性。
应用场景:广泛应用于信息检索、文本挖掘、文本分类等领域。
2.不同点
计算方式:
TF:只计算词在单个文档中的频率。
TF-IDF:计算词在单个文档中的频率并结合整个文档集合中的稀有程度。
结果影响:
TF:高频词会有较高的权重,但无法区分常见词和重要词。
TF-IDF:通过IDF调整,高频但常见的词(如的、是)会被赋予较低的权重,而那些在少数文档中出现的词会有较高的权重。
四.例子说明
1.文档集合例子
文档1:这是一篇关于自然语言处理的文章。
文档2:自然语言处理是人工智能的一个分支。
文档3:机器学习也是人工智能的一个重要领域。
2.TF的计算过程
文档1中出现1次,文档总词数为7,故TF(自然, 文档1) = 1 7 ≈ 0.14 \frac{1}{7} \approx 0.14 71≈0.14
文档2中出现1次,文档总词数为8,故TF(自然, 文档2) = 1 8 = 0.125 \frac{1}{8} = 0.125 81=0.125
文档3中未出现,故TF(自然, 文档3) = 0
3.IDF的计算过程
包含词"自然"的文档数为2,总文档数为3。使用平滑IDF公式:
IDF ( 自然 , { 文档 1 , 文档 2 , 文档 3 } ) = log ( 3 + 1 2 + 1 ) = log ( 4 3 ) ≈ 0.124 \text{IDF}(自然, \{文档1, 文档2, 文档3\}) = \log \left( \frac{3 + 1}{2 + 1} \right) = \log \left( \frac{4}{3} \right) \approx 0.124 IDF(自然,{文档1,文档2,文档3})=log(2+13+1)=log(34)≈0.124
4.TF-IDF的计算过程
对于文档1,TF-IDF(自然, 文档1, {文档1, 文档2, 文档3}) = 0.14 * 0.124 ≈ 0.017
对于文档2,TF-IDF(自然, 文档2, {文档1, 文档2, 文档3}) = 0.125 * 0.124 ≈ 0.016
对于文档3,TF-IDF(自然, 文档3, {文档1, 文档2, 文档3}) = 0 * 0.124 = 0
TF和TF-IDF在衡量词在文档中的重要性时,TF简单直观,但未考虑词在整个文档集合中的分布;TF-IDF则综合考虑了词在单个文档中的频率和整个文档集合中的稀有程度,因而更为准确和有效。