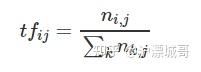TF-IDF(Term Frequency-Inverse Document Frequency)是一种用于信息检索和文本挖掘的统计方法,用来评估一个词语对于一个文档集或一个语料库的重要程度。TF-IDF的基本思想是:如果一个词语在某个文档中出现的次数多,并且在其他文档中很少出现,那么该词语具有很好的区分能力,适合作为关键词。
### 一、算法概述
TF-IDF由两部分组成:词频(TF)和逆文档频率(IDF)。
1. **词频(TF)**:衡量一个词语在文档中出现的频率。
- 公式:\[ TF(t, d) = \frac{f_{t,d}}{N_d} \]
- 其中,\( f_{t,d} \) 是词语 \( t \) 在文档 \( d \) 中出现的次数,\( N_d \) 是文档 \( d \) 中词语的总数。
2. **逆文档频率(IDF)**:衡量一个词语在整个语料库中出现的频率。
- 公式:\[ IDF(t, D) = \log \frac{N}{1 + n_t} \]
- 其中,\( N \) 是语料库中文档的总数,\( n_t \) 是包含词语 \( t \) 的文档数量。
3. **TF-IDF**:词语 \( t \) 在文档 \( d \) 中的TF-IDF值。
- 公式:\[ TF\text{-}IDF(t, d, D) = TF(t, d) \times IDF(t, D) \]
### 二、算法步骤
1. **计算词频(TF)**:
对于每个文档,计算每个词语的词频。
2. **计算逆文档频率(IDF)**:
对于每个词语,计算其在整个语料库中的逆文档频率。
3. **计算TF-IDF**:
将词频和逆文档频率相乘,得到每个词语的TF-IDF值。
### 三、示例
假设我们有以下三个文档:
- 文档1:`"this is a sample"`
- 文档2:`"this is another example example"`
- 文档3:`"this example is different"`
#### 1. 计算词频(TF)
| 词语 | 文档1 (TF) | 文档2 (TF) | 文档3 (TF) |
|---------|------------|------------|------------|
| this | 1/4 | 1/5 | 1/4 |
| is | 1/4 | 1/5 | 1/4 |
| a | 1/4 | 0 | 0 |
| sample | 1/4 | 0 | 0 |
| another | 0 | 1/5 | 0 |
| example | 0 | 2/5 | 1/4 |
| different | 0 | 0 | 1/4 |
#### 2. 计算逆文档频率(IDF)
| 词语 | 出现的文档数 (nt) | IDF (log(3/(1 + nt))) |
|---------|-------------------|------------------------|
| this | 3 | log(3/4) = -0.125 |
| is | 3 | log(3/4) = -0.125 |
| a | 1 | log(3/2) = 0.405 |
| sample | 1 | log(3/2) = 0.405 |
| another | 1 | log(3/2) = 0.405 |
| example | 2 | log(3/3) = 0 |
| different | 1 | log(3/2) = 0.405 |
#### 3. 计算TF-IDF
| 词语 | 文档1 (TF-IDF) | 文档2 (TF-IDF) | 文档3 (TF-IDF) |
|---------|----------------------------|----------------------------|----------------------------|
| this | (1/4) * (-0.125) = -0.031 | (1/5) * (-0.125) = -0.025 | (1/4) * (-0.125) = -0.031 |
| is | (1/4) * (-0.125) = -0.031 | (1/5) * (-0.125) = -0.025 | (1/4) * (-0.125) = -0.031 |
| a | (1/4) * 0.405 = 0.101 | 0 | 0 |
| sample | (1/4) * 0.405 = 0.101 | 0 | 0 |
| another | 0 | (1/5) * 0.405 = 0.081 | 0 |
| example | 0 | (2/5) * 0 = 0 | (1/4) * 0 = 0 |
| different | 0 | 0 | (1/4) * 0.405 = 0.101 |
### 四、Python实现
以下是使用Python实现TF-IDF算法的代码示例:
```python
import math
from collections import Counter
# 文档集
documents = [
"this is a sample",
"this is another example example",
"this example is different"
]
# 计算TF
def compute_tf(text):
tf_text = Counter(text.split())
for i in tf_text:
tf_text[i] = tf_text[i]/float(len(text.split()))
return tf_text
# 计算IDF
def compute_idf(word, corpus):
return math.log(len(corpus)/(1 + sum([1 for doc in corpus if word in doc])))
# 计算TF-IDF
def compute_tfidf(corpus):
documents_list = [doc.split() for doc in corpus]
tfidf_docs = []
for text in documents_list:
tfidf = {}
computed_tf = compute_tf(" ".join(text))
for word in computed_tf:
tfidf[word] = computed_tf[word] * compute_idf(word, corpus)
tfidf_docs.append(tfidf)
return tfidf_docs
# 计算并打印TF-IDF
tfidf_docs = compute_tfidf(documents)
for i, doc in enumerate(tfidf_docs):
print(f"文档 {i+1} 的 TF-IDF 值:")
for word in doc:
print(f"{word}: {doc[word]}")
print("\n")
```
### 五、应用场景
TF-IDF广泛应用于以下领域:
1. **信息检索**:评估文档与查询词语的相关性。
2. **文本分类**:用于特征提取,作为分类器的输入。
3. **关键词提取**:自动从文本中提取关键词。
4. **推荐系统**:分析用户评论或内容,提供个性化推荐。
通过TF-IDF算法,能够有效地识别出文本中的重要词语,从而在信息检索、文本分析和自然语言处理等领域发挥重要作用。

![[机器学习]<span style='color:red;'>TF</span>-<span style='color:red;'>IDF</span><span style='color:red;'>算法</span>](https://img-blog.csdnimg.cn/direct/ffccf517768f4be1bd9ecb766eb80ee8.png)