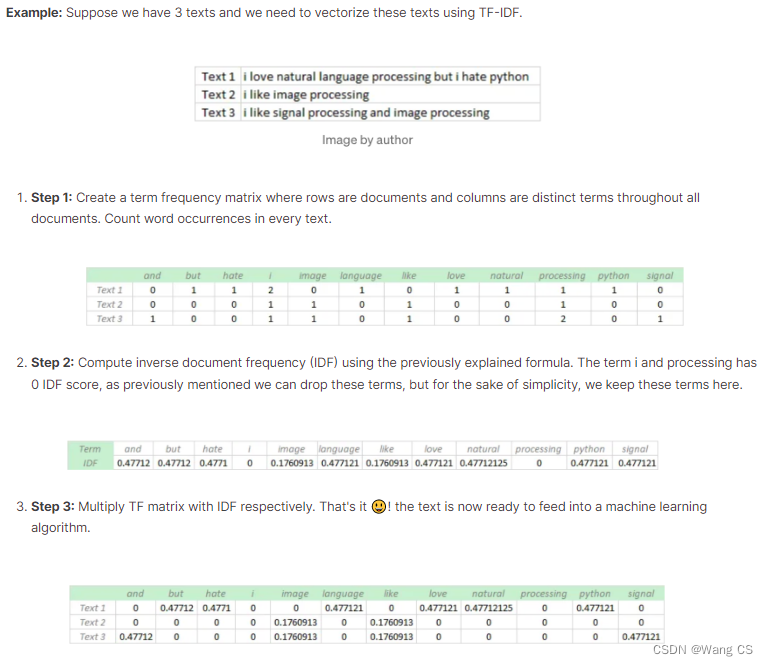
TF-IDF 表征了某个词对于一段文本的重要性和独特性
假设我们有以下三段简短的文本数据:
文本1: 这个苹果很新鲜很甜
文本2: 我买了一个苹果非常喜欢
文本3: 这个苹果皮非常光滑
首先,我们构建这个小文本集合的词典(vocabulary),去掉一些常见的无意义词语(如"的"、"一个"等),词典为:
{‘这个’, ‘苹果’, ‘新鲜’, ‘甜’, ‘我’, ‘买了’, ‘非常’, ‘喜欢’, ‘皮’, ‘光滑’} 共10个词条。
接下来,计算每个词条在每个文本中的TF(词频)值,以及在整个文本集合中的IDF(逆向文档频率)值。
例如对于"苹果"这个词条:
TF(文本1) = 1/4 = 0.25 (在文本1中出现1次,文本长度4)
TF(文本2) = 1/5 = 0.2
TF(文本3) = 1/4 = 0.25
IDF = log(3/3) = 0 (在所有3个文件中都出现过)
将每个词条的TF*IDF值作为该词条在该文本的特征值,那么文本1可以用一个10维的特征向量表示为:
[0.27, 0.25, 0.27, 0.27, 0, 0, 0, 0, 0, 0]
文本2的特征向量为:
[0, 0.2, 0, 0, 0.4, 0.4, 0.4, 0.4, 0, 0]
文本3的特征向量为:
[0.27, 0.25, 0, 0, 0, 0, 0, 0, 0.27, 0.27]
这样,我们就根据TF-IDF的值,将原始的文本数据转化为了数值型的向量形式,方便被机器学习模型使用。可以看出,在这个例子中,"苹果"对1和3更为重要,“新鲜”"甜"等对1更重要,“非常”"喜欢"对2更重要,“皮”"光滑"对3更重要。这些重要特征被很好地保留下来,而常见无意义的词组被过滤掉。
通过这个例子,我们可以看到TF-IDF如何高效地根据词条在不同文本中的重要性赋予权重,将文本表示为向量形式的特征,以输入机器学习任务中。
TF-IDF通过以下两个方面来凸显文档中的重要词语
1.词频(TF)部分
TF指的是单词在当前文档中出现的频率。一个词语在文档中出现的频率越高,说明它对该文档越重要,应当赋予更高的权重。
TF通常通过以下公式计算:
TF(t,d) = freq(t,d) / sum(freq(w,d) for w in d)
其中, freq(t,d)表示词语t在文档d中出现的频率,sum表示文档d中所有单词频率之和。这样可以归一化词频,避免受文档长度的影响。
2.逆向文档频率(IDF)部分
IDF的作用是降低那些在整个文档集中过于常见的词语的权重,提高那些较为独特、稀有的词语的权重。
IDF通过以下公式计算:
IDF(t,D) = log(N / freq(d in D contains t))
其中,N是语料库中文档的总数,freq(d in D contains t)是含有单词t的文档数量。
可以看到,如果一个单词在很多文档中都出现过,它的IDF值会较小;反之,如果一个词语在很少文档中出现,它的IDF值会较大。
最终,TF-IDF是TF和IDF的乘积:
TF-IDF(t,d,D) = TF(t,d) * IDF(t,D)
通过这种交叉计算,TF-IDF使得:
- 文档中出现频率高的词语获得较高权重(高TF)
- 在整个语料库中罕见的词语获得较高权重(高IDF)
- 普通常见词语的权重被削减(高TF低IDF或低TF低IDF)
因此,对于文档来说,它的特征词语(如专有名词、术语等)会获得很高的TF-IDF分数,而那些像"的"、"一个"这样的常见词语则会被降低权重,从而凸显了文档的重要词语特征。
这就是TF-IDF能突出重要词语、消除噪音的根本原因,使其成为自然语言处理中一种广泛使用的词语重要性加权方法。
附录:举一个计算的例子