在信息检索、文本挖掘和搜索引擎优化(SEO)的领域内,TF-IDF算法是最常用的一种统计方法,用于评估一个词语对于一个文档集或一个语料库中的一份文档的重要性。该算法是在1988年由Salton提出的。本文将详细介绍TF-IDF算法的基本概念、数学原理、应用实例以及使用注意事项。

一、简介
1. 什么是TF-IDF?
TF-IDF代表词频-逆文档频率。它是一种统计方法,用以反映一个词对于文档集或语料库中某文档的重要程度。基本思想是:字词的重要性随着它在文档中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。
2. 主要作用
- 关键词提取:提取文档中的关键性词汇。
- 文本相似度分析:比较不同文档的主题相似性。
- 信息检索:快速找出相关的信息文档。
二、理论基础
1. 词频(Term Frequency, TF)
表示词条(术语)t在文档d中出现的频率。一般来说,词频越高,则该词条在文档中越重要。
2. 逆文档频率(Inverse Document Frequency, IDF)
表示一个词条普遍重要性的度量。如果包含词条t的文档越少,则IDF越大,t的权重也就越大。
三、计算方法
1. 词频(TF)计算
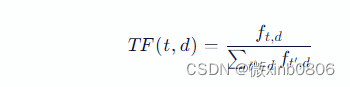
其中,��,�ft,d 表示词t在文档d中的出现次数,分母则是文档d中所有字词的出现次数之和。
2. 逆文档频率(IDF)计算

其中,N表示总文档数,∣{�∈�:�∈�}∣∣{d∈D:t∈d}∣ 表示包含词t的文档数量。
3. TF-IDF值计算

四、使用方法
1. 数据预处理
- 分词:将文本分解成词语。
- 停用词处理:去除常见但无实际意义的词,如“和”、“是”等。
2. 构建文档集合
将所有需要分析的文档整合为一个集合。
3. 计算TF-IDF值
对每个文档计算其中每个词的TF-IDF值。
4. 分析与应用
根据计算得到的TF-IDF值进行关键词提取、文本相似度分析或信息检索等。
五、注意事项
- 数据清洗:确保输入的数据干净、准确,避免噪音数据影响结果。
- 中文处理:中文需特别注意分词的准确性,考虑使用合适的分词工具。
- 归一化处理:在不同文档间比较TF-IDF值时,注意长度归一化。
- 语境理解:TF-IDF仅从统计角度分析,不考虑词语的实际含义和语境。
六、总结
TF-IDF算法是一种有效的信息检索和文本分析工具,它通过衡量词语在特定文档中以及在整个文档集中的重要性,帮助提取关键词、分析文本相似度或改进信息检索系统。尽管它不能理解语义,但在许多应用场景下,TF-IDF仍然是一个强大且不可或缺的工具。在使用TF-IDF时,应注意数据预处理的准确性,并结合实际需求进行调整和优化。
最后插播下,码字不易。更多工作上的技巧和问题,可以直接关注宫中号【追梦好彩头】,每天只需3分钟,为你深入解读不一样的职场视角信息差,帮你在职场道路上加速前进、让你在工作中游刃有余。关注我不迷路,一起见证奇迹时刻