目录
1. 双向链表的结构
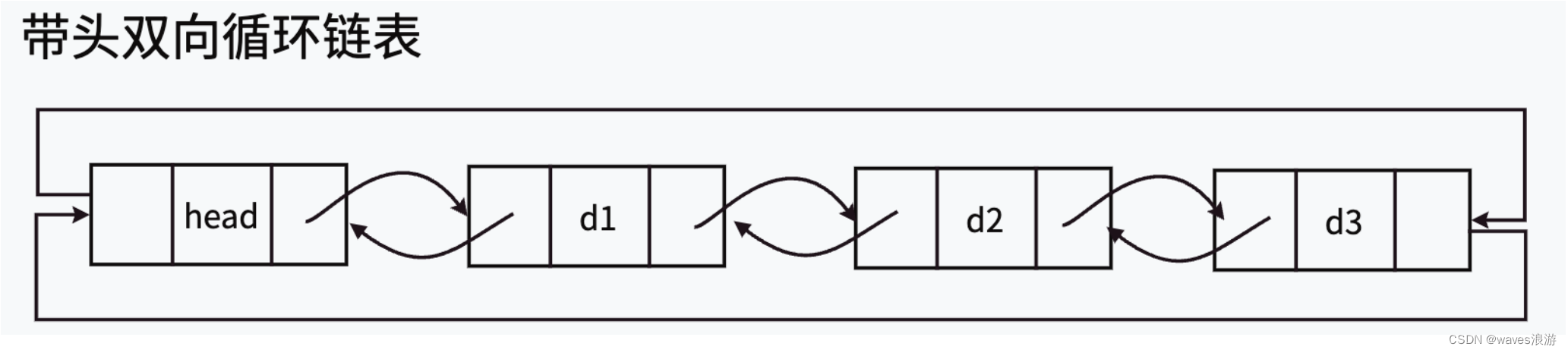
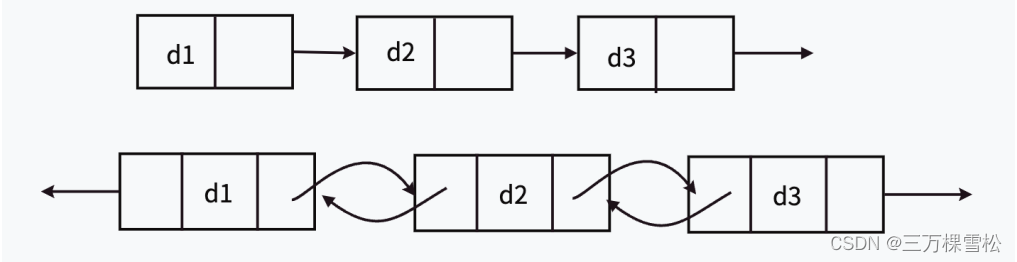
带头双向循环链表 - 简称双向链表

注意:这里的“带头”跟前面我们说的“头节点”是两个概念,实际前面的在单链表阶段称呼不严谨,但是为了更好的理解就直接称为单链表的头节点。
带头链表里的头节点,实际为“哨兵位”,哨兵位节点不存储任何有效元素,只是站在这里“放哨的”“哨兵位”存在的意义:遍历循环链表避免死循环。
2. 双向链表的实现
2.1 双向链表的初始化
代码:
//申请节点
//申请节点的代码后续插入数据还要用,所以这里封装一个函数
LTNode* LTBuyNode(LTDataType x)
{
//malloc申请节点
LTNode* newnode = (LTNode*)malloc(sizeof(LTNode));
//判断malloc的返回值
if (newnode == NULL)
{
//打印错误信息并且退出
perror("malloc fail!!!\n");
exit(1);
}
//设置data,next指针以及prev指针
newnode->data = x;
newnode->next = newnode->prev = newnode;
return newnode;
}
//初始化
//要想改变头节点,就必须传一级指针的地址,所以这里用二级指针接收
void LTInit(LTNode** pphead)
{
//参数不能传NULL
assert(pphead);
//创建一个头节点(哨兵位置)
*pphead = LTBuyNode(-1);
}双向链表初始化问题:

双向链表哨兵位指针指向问题:
 如果后续想要插入新的节点往后面直接插入就可以了,在插入节点时也不需要判断节点是否为空了,因为有哨兵位。
如果后续想要插入新的节点往后面直接插入就可以了,在插入节点时也不需要判断节点是否为空了,因为有哨兵位。
调式:

prev指针和next指针都指向自己。
双向链表为空的情况:只有一个哨兵位,因为它不存储任何效数据,如果哨兵位都没有,那就是一个单链表。
2.2 双向链表的打印
代码:
//打印
void LTPrint(LTNode* phead)
{
//不能传空指针,因为就算双向链表为空,哨兵位是有的
assert(phead);
//哨兵位的下一个节点才是双向链表的第一个有效节点
LTNode* pcur = phead->next;
//pcur遍历双向链表,当遍历的节点是哨兵位的时候跳出循环
while (pcur != phead)
{
//打印当前节点的data值
printf("%d->", pcur->data);
//走向下一个节点
pcur = pcur->next;
}
//双向链表中没有NULL,只需要换行就行
//printf("NULL\n");
printf("\n");
}
2.3 双向链表的尾插
代码:
//尾插
void LTPushBack(LTNode* phead, LTDataType x)
{
//不能传空指针
assert(phead);
//申请节点
LTNode* newnode = LTBuyNode(x);
/*
注意:在修改节点指针指向的时候一定要注意顺序
如果先修改哨兵位节点的prev指针的指向,那么最后一个节点就会找不到
如果先修改原来的节点都有可能会影响原链表,所以我们先修改newnode
节点的next指针和prev指针的指向才不会影响原链表
*/
//新节点的next指针指向哨兵位
newnode->next = phead;
//新节点的prev指针指向哨兵位的prev指针指向的节点,也就是原链表的尾节点
newnode->prev = phead->prev;
//新节点的前节点的next指针指向新节点自己
newnode->prev->next = newnode;
//哨兵为的prev节点指向newnode节点
phead->prev = newnode;
}函数传参问题:

指针指向:
 测试:
测试:

2.4 双向链表的头插
代码:
//头插
void LTPushFront(LTNode* phead, LTDataType x)
{
//不能传空指针
assert(phead);
//申请节点
LTNode* newnode = LTBuyNode(x);
//将newnode的next指针指向phead->next
newnode->next = phead->next;
//将newnode的prev指针指向哨兵位
newnode->prev = phead;
//将哨兵位的next指针指向newnode
phead->next = newnode;
//将newnode的next指针指向的节点的prev指针指向newnode自己
newnode->next->prev = newnode;
}指针指向:

测试:

2.5 双向链表的判空函数
代码:
//双向链表的判空
//该函数的返回值是布尔类型,所以得包含头文件,#include <stdbool.h>
bool LTEmpty(LTNode* phead)
{
//不能传空指针
assert(phead);
//当哨兵位的next指针指向的不是哨兵位节点自己的时候,返回false
//否则返回true
return phead->next == phead;
}2.6 双向链表的尾删
代码:
//尾删
//哨兵位不能删除,所以这里传一级指针就可以了
void LTPopBack(LTNode* phead)
{
//不能传空指针以及双向链表为空不能删除
/*
双向链表为空指的是该链表只有一个哨兵位节点
该哨兵位节点的next指针和prev指针指向自己
所以当phead的next指针和prev指针指向自己的
时候就不能指向删除操作(判断一个即可),因为
next指针指向自己的时候prev指针也就指向自己了
*/
assert(phead );
//assert直接断言链表是否为空和函数判断链表是否为空,任意选择一种即可
//assert(phead->next != phead);
assert(!LTEmpty(phead));
//phead phead->prev->prev phead->prev
//将phead->prev->prev的节点的next指针指向哨兵位
phead->prev->prev->next = phead;
//保存尾节点(要释放的节点)
LTNode* del = phead->prev;
//保存尾节点的前一个节点
LTNode* prev = del->prev;
//将prev的next指针不再指向尾节点,要指向哨兵位
prev->next = phead;
//将哨兵位的前一个节点不再指向尾节点,要指向prev节点
phead->prev = prev;
//释放尾节点
free(del);
//将del指针置为空,防止变成野指针
del = NULL;
}指针的指向

测试:

如果再删除,链表就会变成空链表,空链表继续删除,断言就会报错。

2.7 双向链表的头删
代码:
//头删
void LTPopFront(LTNode* phead)
{
//不能传空指针以及空链表不能删除
assert(phead && !LTEmpty(phead));
//phead phead->next phead->next->next
//保存要删除的节点
LTNode* del = phead->next;
//将哨兵位的next节点指向要删除节点的后一个节点
phead->next = del->next;
//将要删除节点的后一个节点的prev指针指向哨兵位
del->next->prev = phead;
//释放del节点
free(del);
//将del置为空指针,防止变为野指针
del = NULL;
}指针的指向:

测试:

如果再删除,链表就会变成空链表,空链表继续删除,断言就会报错。

2.8 双向链表的查找
代码:
//查找
LTNode* LTFind(LTNode* phead, LTDataType x)
{
//不能传空指针
assert(phead);
//从有效节点开始查找,也就是哨兵位的下一个节点
LTNode* pcur = phead->next;
//当变量节点的指针指向哨兵位的时候跳出循环
while (pcur != phead)
{
//判断当前节点的data值是不是等于x
if (pcur->data == x)
{
//如果等于x就返回当前节点的地址
return pcur;
}
//走向下一个节点
pcur = pcur->next;
}
//查找失败返回NULL
return NULL;
}测试:

注意该函数的返回值以及返回值的类型。
2.9 在pos位置之后插入节点
代码:
//在pos位置之后插入数据
void LTInsert(LTNode* pos, LTDataType x)
{
//pos不能位空
assert(pos);
//申请节点
LTNode* newnode = LTBuyNode(x);
//pos newnode pos->next
//修改newnode节点不会影响原链表,所以我们先修改newnode节点
//将newnode的next指针指向pos之后的节点
newnode->next = pos->next;
//将newnode节点的prev指针指向pos节点
newnode->prev = pos;
//将pos节点的next指针指向newnode
pos->next = newnode;
//将原链表pos节点后的节点的prev指针指向newnode
newnode->next->prev = newnode;
}指针指向:

测试:

2.10 删除指定位置节点
代码:
//删除指定位置数据
void LTErase(LTNode* pos)
{
//pos不能为空
assert(pos);
//pos->prev pos pos->next
//将pos节点的前一个节点的next指针pos指向下一个节点
pos->prev->next = pos->next;
//将pos节点的下一个节点的prev指针指向pos前一个节点
pos->next->prev = pos->prev;
//释放pos节点
free(pos);
//将pos指针置为空指针,防止变为野指针
pos = NULL;
}指针指向:

测试:

2.11 双向链表的销毁
代码:
//销毁双向链表
//链表是整个都销毁,包括哨兵位,所以这里传二级
void LTDesTroy(LTNode** pphead)
{
//不能传空指针以及链表不能为空
assert(pphead && *pphead);
//创建临时指针,用来遍历节点,初始指向第一个有效位(哨兵位后面的节点)
LTNode* pcur = (*pphead)->next;
//节点要一个一个销毁,所以要遍历链表,当遍历的指针指向哨兵位的时候跳出循环
while (pcur != *pphead)
{
//创建临时变量,将当前节点的下一个节点保存起来,要不然下面free就找不到了
LTNode* Next = pcur->next;
//销毁当前节点
free(pcur);
//走下一个节点
pcur = Next;
}
//将pcur置为空,防止变成野指针
pcur = NULL;
//销毁哨兵位 - 哨兵位在循环中没被释放,所以要单独释放
free(*pphead);
//指向哨兵位的指针也置为空,防止变为野指针
*pphead = NULL;
}
调试:
 当断点打在销毁函数之前,此时所以的节点都在,包括哨兵位,还是一个完整的双向链表。
当断点打在销毁函数之前,此时所以的节点都在,包括哨兵位,还是一个完整的双向链表。

当我按下F10,销毁代码执行完成,此时plist链表直接位NULL。
2.12 双向链表的优化
双向链表的很多函数都是传的一级指针,因为双向链表有哨兵位,有哨兵位的话就不会去修改哨兵位。但是我们会发现,初始化和销毁又是二级指针,不统一,对使用者不友好。
2.12.1 销毁的函数优化
代码:
void LTDesTroyPro(LTNode* phead)
{
assert(phead);
LTNode* pcur = phead->next;
while (pcur != phead)
{
LTNode* Next = pcur->next;
free(pcur);
pcur = Next;
}
free(phead);
//这里的phead销毁不会影响plist,但是plist指向的地址已经被销毁
phead = pcur = NULL;
}代码和优化前的代码只是形参的二级指针变为了一级指针,其它没变化。
调试:

断点打在销毁函数之前,链表还是完整的。
 当代码free完哨兵位之后,我们的链表中的节点以及被操作系统回收,指针也置为空,哨兵位也被回收,只不过还没置空,我们还可以看到phead和plist指向的是同一块地址空间。
当代码free完哨兵位之后,我们的链表中的节点以及被操作系统回收,指针也置为空,哨兵位也被回收,只不过还没置空,我们还可以看到phead和plist指向的是同一块地址空间。

代码在往下执行一步,phead被置空。

当跳出循环我们还可以看到plist指针还是指向那块空间,可是那块空间以及在销毁函数中被free掉了,被操作系统回收掉了,这是因为我们是值传递,形参的修改并不会影响实参,所以即使phead在函数中被置空,plist也不会被置空,此时plist变成了野指针,所以我们要在函数结束之后手动置空。
我们把销毁函数的形参改为了一级指针之后我们得在函数外手动置空,这就是我们的优化操作。但是传一级,需要手动将plist置为空,这就是统一接口之后带来的问题。
2.12.2 初始化函数的优化
代码:
//初始化函数的优化
LTNode* LTInitPro()
{
LTNode* phead = LTBuyNode(-1);
return phead;
}直接调用该函数接收返回值即可。
初始化函数优化前和优化后的区别:

优化前就是通过形参传递,优化后是通过返回值传递。
3.顺序表和链表的优缺点分析
顺序表和链表哪一个更好?
| 不同点 | 顺序表 | 链表(单链表) |
| 存储空间上 | 物理上一定连续 | 逻辑上连续,但物理上不一定连续 |
| 随机访问 | 支持O(1),因为地址是连续的 | 不支持,O(N) |
| 任意位置插入或删除元素 | 可能需要搬移元素,效率低O(N) | 只需修改指针指向O(1) |
| 插入 | 动态顺序表,空间不够时需要扩容,有一定的空间浪费 | 没有容量的概念 |
| 应用场景 | 元素高效存储+频繁访问 | 任意位置插入和删除频繁 |
所以顺序表和链表哪个好就得取决于应用场景了,没有绝对的更好,存在即合理,要根据不同的场景选择对应的数据结构。