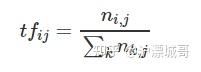TF-IDF
TF-IDF全称为“Term Frequency-Inverse Document Frequency”,是一种用于信息检索与文本挖掘的常用加权技术。该方法用于评估一个词语(word)对于一个文件集(document)或一个语料库中的其中一份文件的重要程度。它是一种计算单词在文档集合中的分布情况的统计方法。
TF(Term Frequency,词频)
TF指的是某一个给定的词语在该文件中出现的频率。这个数字是对词数(term count)进行归一化(通常是文档中单词总数),以防止它偏向长的文件。(即某个单词在文章中出现次数越多,其TF值也就越大)
TF的公式如下:
T F ( t , d ) = 在文档 d 中 t 出现的次数 文档 d 中所有字词数量 TF(t, d) = \frac{在文档d中t出现的次数}{文档d中所有字词数量} TF(t,d)=文档d中所有字词数量在文档d中t出现的次数
IDF(Inverse Document Frequency,逆向文件频率)
IDF指的是一个特定单词有多少重要性。这需要通过整个语料库来评估每个单词提供多少信息:如果只有少数几篇文章使用了它,则认为它提供了很多信息。(即包含某个单纯越少,IDF值就越大)
IDF的公式如下:
I D F ( t , D ) = log 总文档数量 包含 t ( 且不为 0 ) 的文档数量 IDF(t, D) = \log\frac{总文档数量}{包含t(且不为0) 的文档数量} IDF(t,D)=log包含t(且不为0)的文档数量总文档数量
然后将TF和IDF相乘得到一个单词在某一特定文件里面相对其他所有文件更加独特重要性评分:
T F I D F ( t , d , D ) = T F ( t , d ) × I D F ( t , D ) TFIDF(t, d, D) = TF(t, d) × IDF(t, D) TFIDF(t,d,D)=TF(t,d)×IDF(t,D)
其中:
- ( t ): 单次(term)
- ( d ): 文档(document)
- ( D ): 语料库(corpus)
最终结果称为TF-IDF权重,高权重表示该术语对当前文章非常具有代表性。
举例来说,在搜索引擎优化(SEO)领域内,可以利用TF-IDF来确定哪些关键字对网页内容更加重要,并据此调整网页以便获得更好地搜索排名。
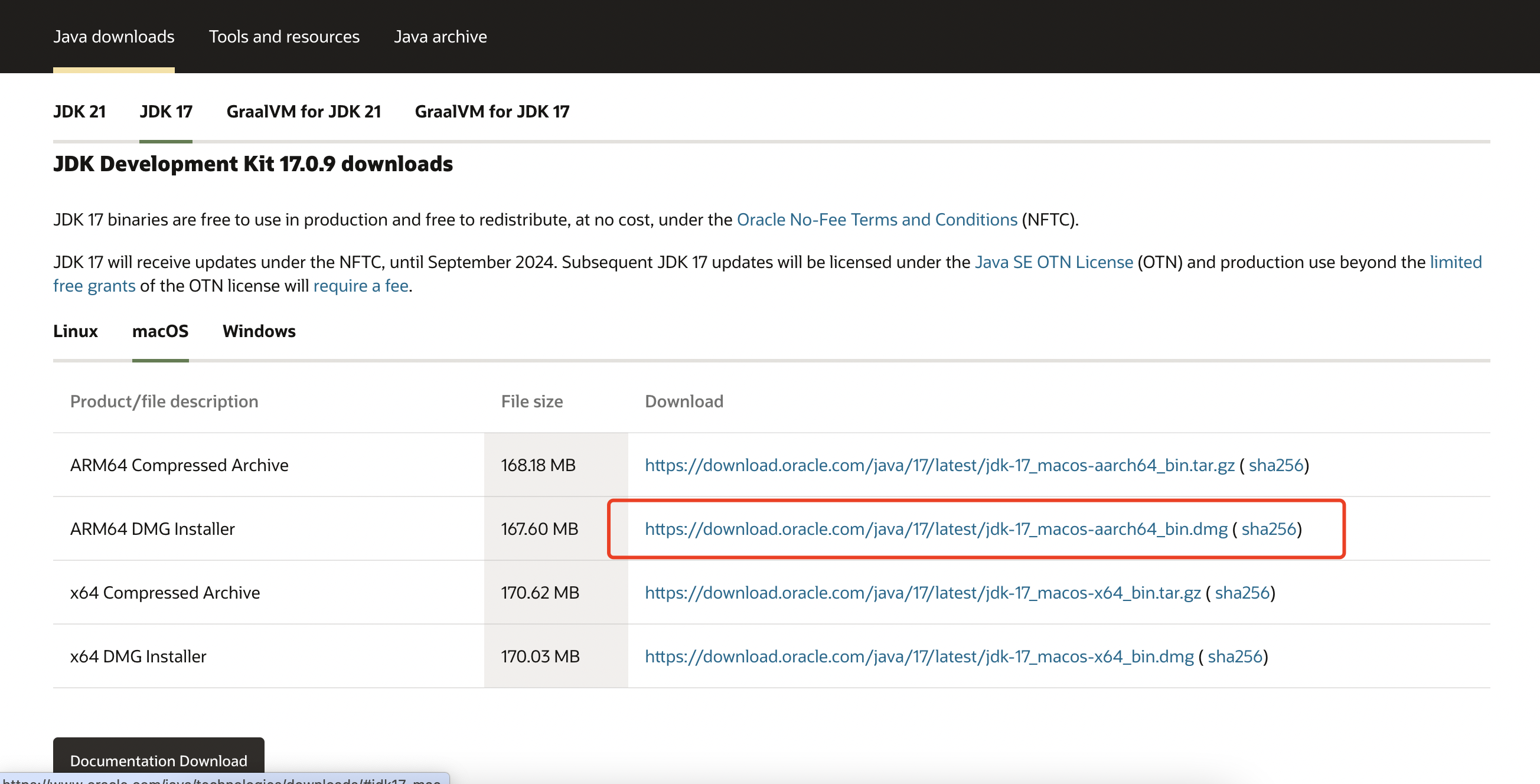
Python实现-sklearn
在Python中,可以使用scikit-learn库来实现TF-IDF的计算。以下是一个简单的示例:
from sklearn.feature_extraction.text import TfidfVectorizer
# 示例文档集合
documents = [
'The sky is blue.',
'The sun is bright.',
'The sun in the sky is bright.',
'We can see the shining sun, the bright sun.'
]
# 初始化一个TFIDF Vectorizer对象
tfidf_vectorizer = TfidfVectorizer()
# 对文档进行拟合并转换成特征向量
tfidf_matrix = tfidf_vectorizer.fit_transform(documents)
# 获取每个词汇在语料库中的词频-IDF权重值
feature_names = tfidf_vectorizer.get_feature_names_out()
# 打印出每个词汇及其对应的IDF值(按照递增顺序)
for word in feature_names:
print(f"{
word}: {
tfidf_vectorizer.idf_[tfidf_vectorizer.vocabulary_[word]]}")
# 查看结果:第一个文档与所有特征名字对应的TF-IDF分数(稀疏矩阵表示)
print(tfidf_matrix[0])
# 如果需要查看非稀疏版本,则需要转换为数组形式:
print(tfidf_matrix.toarray()[0])
这段代码首先导入了必要的类 TfidfVectorizer 并创建了一个实例。之后用这个实例去“学习”传入文本数据集合中所有单词的IDF值,并将每篇文章转换为TF-IDF特征向量。
最后两句打印输出了第一篇文章与全部特征(即单词)之间对应关系上各自的TF-IDF分数。由于大多数单词在大部分文件中并不会出现,因此 TfidfVectorizer 返回一个稀疏矩阵。
Python实现
不用依赖包,用math实现,代码如下:
import math
# 示例文档集合
documents = [
'The sky is blue.',
'The sun is bright.',
'The sun in the sky is bright.',
'We can see the shining sun, the bright sun.'
]
# 用于分词和预处理文本(例如:转小写、去除标点)
def preprocess(document):
return document.lower().replace('.', '').split()
# 计算某个词在文档中出现的次数
def term_frequency(term, tokenized_document):
return tokenized_document.count(term)
# 计算包含某个词的文档数目
def document_containing_word(word, tokenized_documents):
count = 0
for document in tokenized_documents:
if word in document:
count += 1
return count
# 计算逆向文件频率(Inverse Document Frequency)
def inverse_document_frequency(word, tokenized_documents):
num_docs_with_word = document_containing_word(word, tokenized_documents)
# 加1防止分母为0,对结果取对数以平滑数据。
# 使用len(tokenized_documents)而不是实际文档数量以避免除以零。
# 这里使用了log10,但也可以使用自然对数ln(即log e)。
if num_docs_with_word > 0:
return math.log10(len(tokenized_documents) / num_docs_with_word)
else:
return 0
tokenized_documents = [preprocess(doc) for doc in documents]
vocabulary = set(sum(tokenized_documents, []))
tfidf_matrix = []
for doc in tokenized_documents:
tfidf_vector = []
for term in vocabulary:
tf_idf_score=term_frequency(term, doc)*inverse_document_frequency(term,tokenized_documents)
tfidf_vector.append(tf_idf_score)
tfidf_matrix.append(tfidf_vector)
print("TF-IDF Matrix:")
for row in tfidf_matrix:
print(row)