目录
Random Search
让我们来看看如何改进刚才的结果。既然你有办法计算出城市数量带来的总损失,那么你就可以设计出许多花哨的方法来尽量减少损失。不过,由于我非常喜欢简单,所以我的建议是随机搜索许多组合,然后选出一个表现还不错的。下面的代码就是这么做的。它首先生成 1000 组 5 个城市的数据,并将所有数据存储在 geo_samples 列表中。然后,将 get_sc_st_combination 部分应用于数据和平均市场结果参数。最后,将该函数应用于 1000 个城市集,所有这一切都是并行进行的:
from joblib import Parallel, delayed
from toolz import partial
np.random.seed(1)
geo_samples = [np.random.choice(geos, n_tr, replace=False)
for _ in range(1000)]
est_combination = partial(get_sc_st_combination,
df_sc=df_piv,
y_mean_pre=y_avg)
results = Parallel(n_jobs=4)(delayed(est_combination)(geos)
for geos in geo_samples)值得一提的是,这种方法并不是最优的,但它确实倾向于产生合理的治疗城市集。
检查所选的治疗城市,你会发现模型只选择了四个城市。毫不意外,最大的城市圣保罗就在其中。这种情况的发生通常是因为大城市占据了市场总量的很大一部分,因此将它们纳入治疗组往往能大幅度减少损失。如果你希望避免这种情况,可以总是将最大的城市排除在可能的对照组之外:
resulting_geos = min(results, key=lambda x: x.get("loss"))
resulting_geos.get("st_geos")
array(['sao_paulo', 'florianopolis', 'recife', 'belem', 'sorocaba'],
dtype='<U23')再次绘制合成控制组和处理组的趋势图,你可以看到,尽管这种方法极其简单,但它能给出一个工作得相当不错的结果。在这种情况下,合成处理组和控制组都能非常紧密地追踪市场平均水平: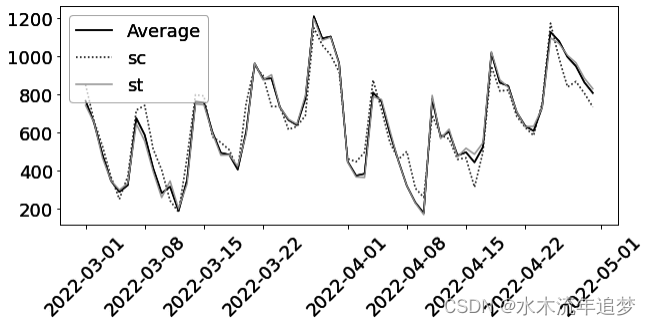
最后值得一提的是,虽然你设计了一个使用合成控制法的实验,但解读实验结果时并不一定非要用合成控制法,尽管这样做确实是个合理的想法。例如,你可以采用合成差分法(synthetic diff-in-diff),因为这种方法通常能减小估计量的方差。不过,在估计所得估计量的方差时,你必须谨慎行事。由于所选城市群体并非随机选取,因此基于将处理重新分配给不同单位的推断程序是不适用的。幸运的是,你学到的t检验并没有对单位如何被选择做出假设,所以在这里可以使用t检验。
Switchback Experiment
合成控制实验设计非常适合单位数量较少的情况,当你想要从中选出最优的一组作为处理组。然而,为了做到这一点,你仍然需要有一定数量的单位。但如果仅有四个单位甚至只有一个单位呢?举个例子,假设你是一个仅在一个城市运营的小型食品配送平台。这家企业使用动态定价来调节食品配送市场的供需关系,它想了解提高配送费如何通过吸引更多的司机加入车队同时抑制或推迟客户需求,从而影响配送时间。请注意,传统A/B测试在此处不适用。因为如果仅对50%的客户提高价格,实际上也会间接惠及对照组的客户,因为整体需求下降会增加可用司机的数量。同时,合成控制实验也不适用,因为公司只在一个城市运营。但在这种情况下,有一种实验设计或许能派上用场。
如果价格上涨的影响在价格回归正常水平后迅速消散,公司就可以多次开关涨价,进行一系列事前事后对比。这种做法被称为切换回实验(switchback experiments),当只有极少数或仅有一个单位时,它是十分有效的。但是要使这种方法奏效,滞后效应的顺序必须很小。也就是说,处理的效果不能在处理后持续很多期。比如在食品配送的例子中,提高价格会在短时间内引起供应量的增加;当价格恢复常态,过量的供应会在几小时内逐渐消失。因此,滞后效应的顺序较小,使得切换回实验成为一个有趣的选择。
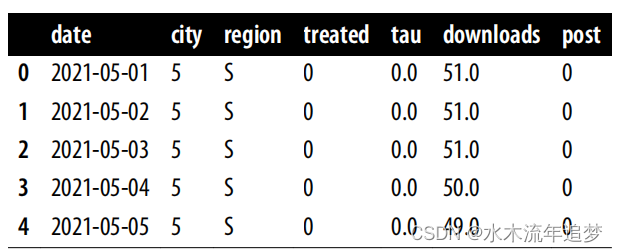
在讨论如何设计切换回实验之前,因为这是本书首次提及这种实验,我认为有必要先为你展示一个实例,以便你理解其运作机制。以下数据框包含了来自一个共120个周期(每个周期为1小时)的切换回实验的数据。在这个实验中,每个时间点都随机决定是否进行处理(提高价格),处理组和对照组的选择概率各为50%。d列告诉你在那一小时价格提高(处理)是否开启,而delivery_time是我们关心的输出结果。此外,我还添加了三个在现实中不会观察到但有助于你理解情况的列。delivery_time_1表示如果处理始终开启时的配送时间,delivery_time_0则是在处理始终关闭时的配送时间。它们之间的差值tau是处理的总效应,通常这也是切换回实验中感兴趣的因果量。由于处理减少了配送时间,因此效应是负数。另外,由于存在滞后效应,前两个周期的影响较小:
df = pd.read_csv("./data/sb_exp_every.csv")
df.head()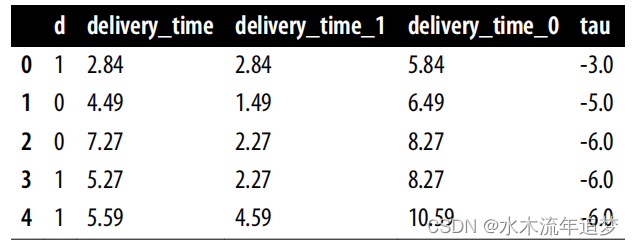
图显示,实际观测到的配送时间在处理始终开启和始终关闭时的配送时间之间波动。而且,在连续三次相同处理之后,观测到的结果与处理始终开启或始终关闭时的结果相匹配。
以T=20至T=23为例,在这些时间点,由于随机因素,处理状态连续开启了三个或更多周期,此时的配送时间与处理状态始终开启时的配送时间相符。相反,在大约T=32时,你可以看到一个处理状态(即控制状态)连续关闭了三个或更多周期的序列。在那个时间点,结果与处理状态始终关闭时的结果相匹配。如果处理状态开启或关闭的时间少于三个连续周期,那么观测到的结果则介于两者之间。这表明,在本例中,结果取决于过去三个周期的处理状态:即时处理状态以及前两个周期的处理状态:
换句话说,滞后效应的阶数是2。
当然,在现实情况下,你并不会知道这一点,因为你只能看到实际观测到的结果。但对此不必过于担心,接下来我会向你展示如何估计滞后效应的持续期长度。目前,我只想让你对切换回实验有一个直观的理解。除此之外,你还将能够发展出一套更正式的语言来描述正在发生的事情。