目录
Inference
我说 "可能错了 "是因为,老实说,用面板数据进行推断非常棘手。最近有很多关于这个话题的研究,这当然很好,但也凸显出我们这个领域仍在学习如何做这件事。这里的问题是,你有 N - T 个数据点,但它们并不是独立和同分布的,因为同一个单位会出现多次。事实上,干预是分配给单位的,而不是分配给时间段的,所以你可以说你的样本量实际上只是 N,而不是 N - T,尽管这最后一个是你的回归在计算标准误差时要考虑的。
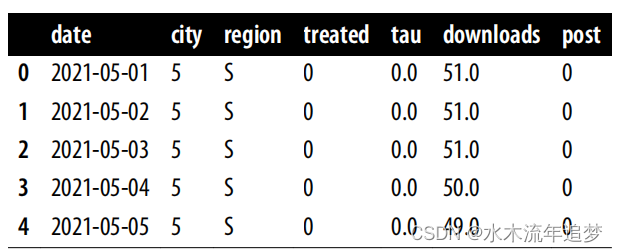
为了纠正回归中过于乐观的标准误差,您可以按单位(在我们的例子中是城市)对标准误差进行分组:
m = smf.ols(
'downloads ~ treated:post + C(city) + C(date)', data=mkt_data
).fit(cov_type='cluster', cov_kwds={'groups': mkt_data['city']})
print("ATT:", m.params["treated:post"])
m.conf_int().loc["treated:post"]
ATT: 0.6917359536407017
0 0.296101
1 1.087370
Name: treated:post, dtype: float64对误差进行聚类会比不进行聚类得到更宽的置信区间:
m = smf.ols('downloads ~ treated:post + C(city) + C(date)',
data=mkt_data).fit()
print("ATT:", m.params["treated:post"])
m.conf_int().loc["treated:post"]
ATT: 0.6917359536407017
0 0.478014
1 0.905457
Name: treated:post, dtype: float64此外,看看如果把每日数据帧 mkt_data 从按单位和干预前后时段汇总的数据帧中替换出来会发生什么:
m = smf.ols(
'downloads ~ treated:post + C(city) + C(date)', data=did_data
).fit(cov_type='cluster', cov_kwds={'groups': did_data['city']})
print("ATT:", m.params["treated:post"])
m.conf_int().loc["treated:post"]
ATT: 0.6917359536407091
0 0.138188
1 1.245284
Name: treated:post, dtype: float64置信区间变得更宽了!这恰恰说明,尽管样本量应该来自单位而不是时间段,但每个单位群组拥有更多的时间段可以减小方差。
正如你在后面将看到的,一些非规范的 DID 没有计算置信区间的标准方法。在这种情况下,您可以选择对整个估计过程进行引导。这里您需要注意一点。由于存在重复单位,同一单位的模型误差将是相关的。因此,您需要对整个单位进行抽样(替换)。这个过程称为块引导。要实现它,首先需要编写一个以替换方式对单位进行采样的函数:
def block_sample(df, unit_col):
units = df[unit_col].unique()
sample = np.random.choice(units, size=len(units), replace=True)
return (df
.set_index(unit_col)
.loc[sample]
.reset_index(level=[unit_col]))有了这个函数后,就可以调整引导代码来实现块引导:
from joblib import Parallel, delayed
def block_bootstrap(data, est_fn, unit_col,
rounds=200, seed=123, pcts=[2.5, 97.5]):
np.random.seed(seed)
stats = Parallel(n_jobs=4)(
delayed(est_fn)(block_sample(data, unit_col=unit_col))
for _ in range(rounds))
return np.percentile(stats, pcts)最后,为了检查一切是否按预期运行,您可以使用该函数计算应用于营销数据的 DID 估计器的 95% CI。得出的 CI 与您之前得到的非常相似,标准误差按单位聚类。这是一个很好的指标,说明您的分块引导功能在起作用:
def est_fn(df):
m = smf.ols('downloads ~ treated:post + C(city) + C(date)',
data=df).fit()
return m.params["treated:post"]
block_bootstrap(mkt_data, est_fn, "city")
array([0.23162214, 1.14002646])在结束本节之前,我想提醒大家,虽然块引导法非常方便,但也存在一些问题。例如,如果处理单位的数量较少,最终可能会出现没有处理单位的样本。同样,面板数据推断是一个复杂的课题,我觉得我们还没有明确的答案。