目录
Synthetic Control as Horizontal Regression
Matrix Representation
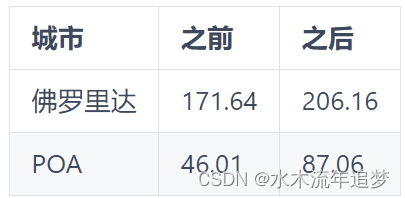
在上文中,我向大家展示了一个用矩阵表示面板数据的图像,其中一个维度是时间段,另一个维度表示单位。合成控制明确使用了该矩阵,因此值得复习一下。假设矩阵的行是时间段,列是城市(单位)。您可以用四个区块来表示干预分配:
矩阵中的第一个区块(左上角)对应的是干预期之前的对照单位;第二个区块(右上角)对应的是干预期之前的被干预单位;第三个区块(左下角)包含干预期之后的对照单位;第四个区块(右下角)是干预期之后的被干预单位。除了治疗期后的干预单位块(右下角)外,其他地方的干预指标 均为零。
该赋值矩阵将导致以下观察到的潜在结果矩阵:
请再次注意,干预后的时间段在下方,而干预后的单位在右侧。您的目标是估算 。为此,您需要以某种方式估算缺失的潜在结果
, tr,即未观察到的结果。换句话说,您需要知道,如果没有接受干预,接受干预的单位在干预后会发生什么情况。要做到这一点,理想情况下,你可以利用你所掌握的所有其他三个区块,即
,
。在向您展示合成控件如何做到这一点之前,让我们先创建一个函数,以这种矩阵格式表示数据。
下面的代码使用 .pivot() 方法重塑数据框,这样最终每个时间段(日期)一行,每个城市一列,而结果则成为矩阵的值。然后,它将矩阵划分为治疗单元和对照单元。再将其分为干预前和干预后两个阶段:
def reshape_sc_data(df: pd.DataFrame,
geo_col: str,
time_col: str,
y_col: str,
tr_geos: str,
tr_start: str):
df_pivot = df.pivot(time_col, geo_col, y_col)
y_co = df_pivot.drop(columns=tr_geos)
y_tr = df_pivot[tr_geos]
y_pre_co = y_co[df_pivot.index < tr_start]
y_pre_tr = y_tr[df_pivot.index < tr_start]
y_post_co = y_co[df_pivot.index >= tr_start]
y_post_tr = y_tr[df_pivot.index >= tr_start]
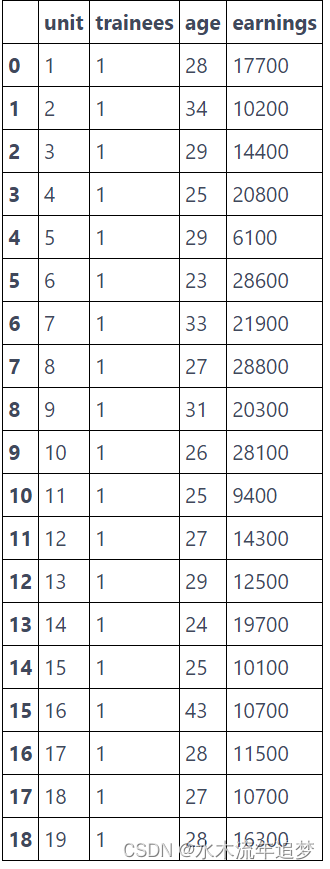
return y_pre_co, y_pre_tr, y_post_co, y_post_tr本文中将一直使用这种四块矩阵表示法。如果你忘记了正在使用什么,只要回到这个函数就可以了。为了了解它是如何工作的,将 df_norm 传递给 reshape_sc_data,就会返回矩阵格式的 Y 值。下面是 y_pre_tr 的前五行:
y_pre_co, y_pre_tr, y_post_co, y_post_tr = reshape_sc_data(
df_norm,
geo_col="city",
time_col="date",
y_col="app_download_pct",
tr_geos=treated,
tr_start=str(tr_period)
)
y_pre_tr.head()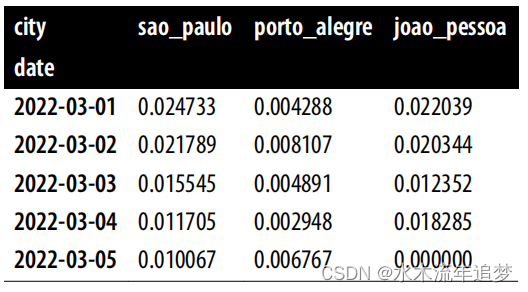
Synthetic Control as Horizontal Regression
合成控制的主要理念非常简单。利用前干预期,您将找到一种方法来组合控制单元,以接近干预单元的平均干预结果。用数学术语来说,这可以理解为一个优化问题,即寻找单位权重 ωi(不要与 混淆),这样当你用每个权重乘以其单位的结果
时,就能得到类似于被处理单位的结果:
然后,为了估计 并得到 ATT 估计值,可以使用合成控制
。
如果这看起来有点晦涩难懂,那么将合成控制与我们更熟悉的工具--线性回归--进行比较,或许是一个很好的替代解释。回想一下,回归也可以用一个优化问题来表示,其目标是最小化结果与协变量线性组合 X 之间的(平方)差:
可以看出,这两个目标是一致的!这意味着,合成对照不过是一种回归,它以对照的结果为特征,试图预测受治疗单位的平均结果。其中的诀窍在于,它只使用干预前的时间段,因此回归估计值 。
事实上,为了证明我的观点,让我们现在就使用 OLS 建立一个合成对照。你所要做的就是把 y_pre_co 当作协变量矩阵 X,把 y_pre_tr 的列平均值当做结果 y。一旦拟合了这个模型,就可以用 .coef_ 提取权重:
from sklearn.linear_model import LinearRegression
model = LinearRegression(fit_intercept=False)
model.fit(y_pre_co, y_pre_tr.mean(axis=1))
# extract the weights
weights_lr = model.coef_
weights_lr.round(3)
array([-0.65 , -0.058, -0.239, 0.971, 0.03 , -0.204, 0.007, 0.095,
0.102, 0.106, 0.074, 0.079, 0.032, -0.5 , -0.041, -0.154,
-0.014, 0.132, 0.115, 0.094, 0.151, -0.058, -0.353, 0.049,
-0.476, -0.11 , 0.158, -0.002, 0.036, -0.129, -0.066, 0.024,
-0.047, 0.089, -0.057, 0.429, 0.23 , -0.086, 0.098, 0.351,
-0.128, 0.128, -0.205, 0.088, 0.147, 0.555, 0.229])
可以看到,每个控制城市都有一个权重。通常,回归法是在有大量单位(大 N)的情况下使用的,这样就可以把单位作为行,协变量作为列。但合成控制的设计是为了在单位相对较少,但时间跨度 Tpre 较大的情况下使用。为此,SC 实际上是将数据翻转过来,把单位当作协变量来使用。这就是合成控制也被称为水平回归的原因。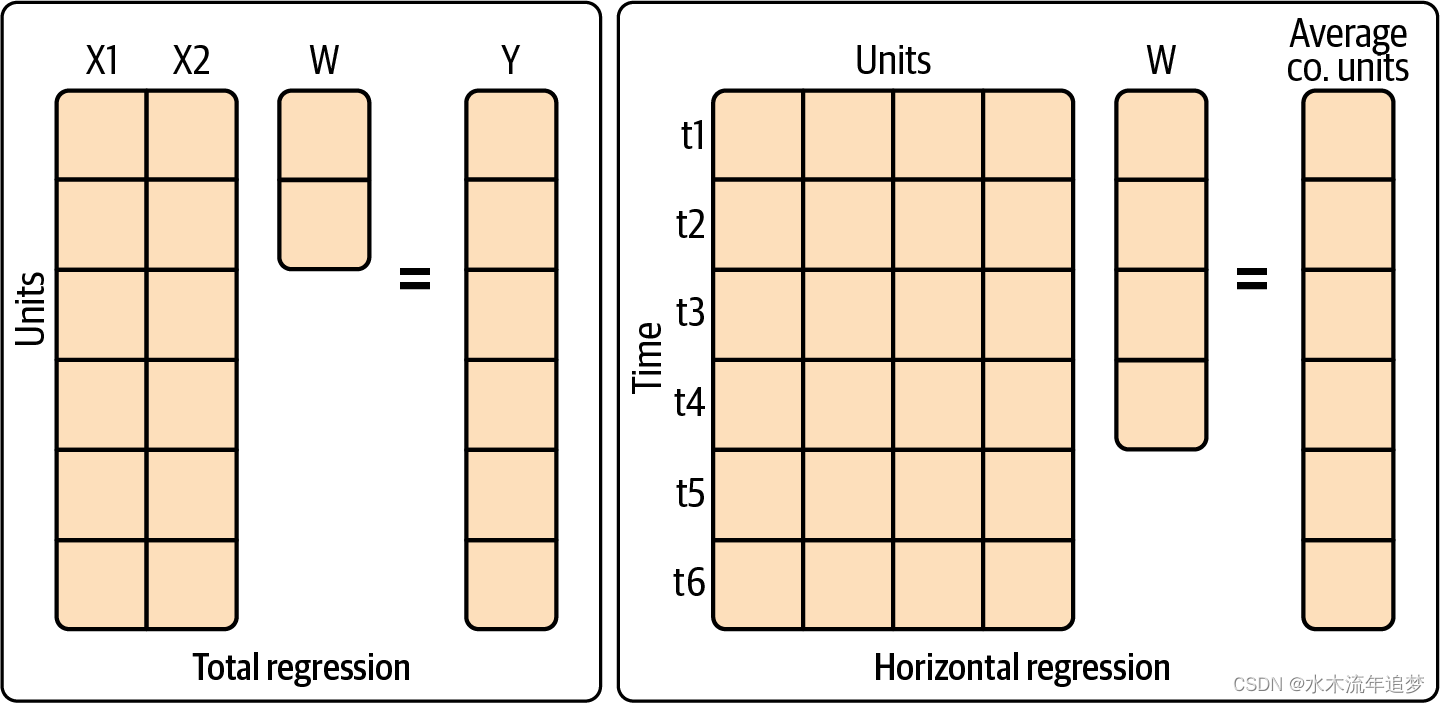
一旦估算出回归参数(或权重),就可以用它们来预测 的情况,不仅是干预前的情况,而且是整个时间范围内的情况:
# same as y0_tr_hat = model.predict(y_post_co)
y0_tr_hat = y_post_co.dot(weights_lr)在这里,y0_tr_hat 可以看作是一种合成控制:是控制单元的组合,它们在没有接受治疗的情况下,接近于接受治疗单元的平均行为。
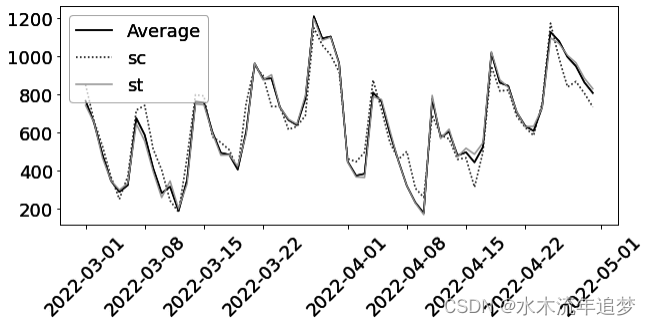
如果你把这个合成控制与观察结果相结合,你会得到这个: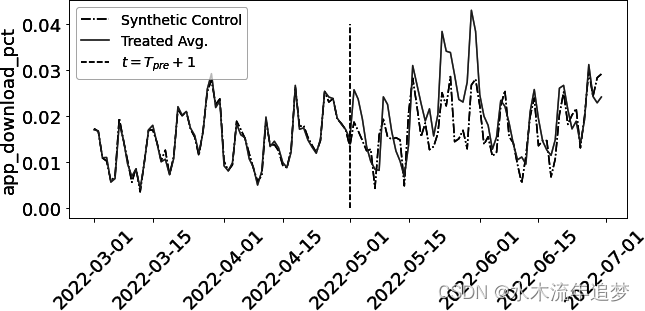
请注意预测值(合成对照)是如何低于被处理单位的实际结果的。这意味着,如果不进行干预,观察到的结果要高于您估计的结果。这表明在线营销活动产生了积极的营销效果。您可以通过对比观察结果和合成对照来计算 ATT 估计值:
att = y_post_tr.mean(axis=1) - y0_tr_hat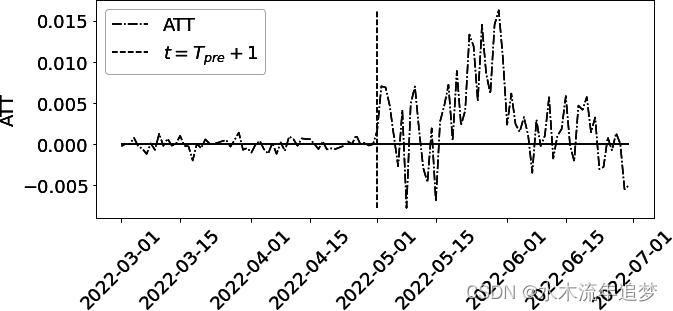
这一情节呈现出几个耐人寻味的方面。首先,它表明效果需要一段时间才能达到顶峰,然后逐渐下降。在市场营销中经常可以看到这种逐渐上升的现象,因为人们在看到广告后通常需要一段时间才能采取行动。此外,效果消失通常可归因于随着时间推移逐渐消失的新奇感效应。
第二个有趣之处在于干预前的 ATT 大小。在这一时期,ATT 可以简单地解释为 OLS 模型的残差(样本误差)。你可能会认为,它接近于零是件好事;毕竟,你不希望在干预(预期)之前看到效应。但事实并非如此。干预前误差低得令人难以置信,这也意味着 OLS 模型可能过度拟合。因此,样本外预测的估计值 可能会出现偏差。
这就是为什么简单回归不常用于建立合成控制的原因。由于列数(控制城市)相对较多,简单回归往往会出现过拟合,无法概括干预后时期的情况。因此,最初的合成控制方法并不是简单回归,而是施加了一些合理、直观的限制条件。