目录
Staggered Adoption
在此之前,您一直在研究的数据类型采用的是区组设计,只有两个时期:干预前和干预后。尽管每个阶段都有多个日期,但归根结底,重要的是有一组单位在同一时间点接受了治疗,还有一组单位从未接受过治疗。这种区组设计是差分分析的典范,因为它使问题变得非常简单,允许您以非参数方式估算基线和趋势,也就是说,只需计算大量样本平均值并进行比较即可。但这种方法也有一定的局限性。如果干预在不同的时间点推广到不同的单位怎么办?
面板数据中更常见的情况是交错采用设计,即有多组单位(我称之为 G),每组单位在不同的时间点(或从未在不同的时间点)接受治疗。由于干预的时间决定了组别,因此通常将其称为队列:在时间 t 得到干预的 G 组就是队列 。
把这带到您一直在看的营销数据中,您有两个队列:一个是从未干预过的队列,即 ,另一个是在 2021-05-15 得到干预的组,即
。但这只是因为我隐藏了 2021-06-01 之后的情况。现在,您已经准备好应对更复杂的情况了,请看 mkt_data_cohorts 数据框,其中也包含了所有地区城市的数据,但现在是截至 2021-07-31 的数据:
mkt_data_cohorts = (pd.read_csv("./data/offline_mkt_staggered.csv")
.astype({
"date":"datetime64[ns]",
"cohort":"datetime64[ns]"}))
mkt_data_cohorts.head()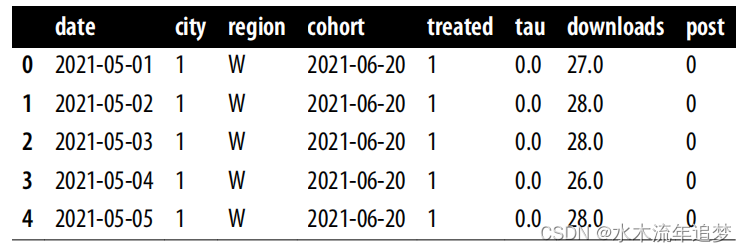
仅仅通过查看最上面的几行,很难看到所有的数据,但是图显示了跨时间的处理状态。在那里,你可以看到交错采用的设计是什么样子的。
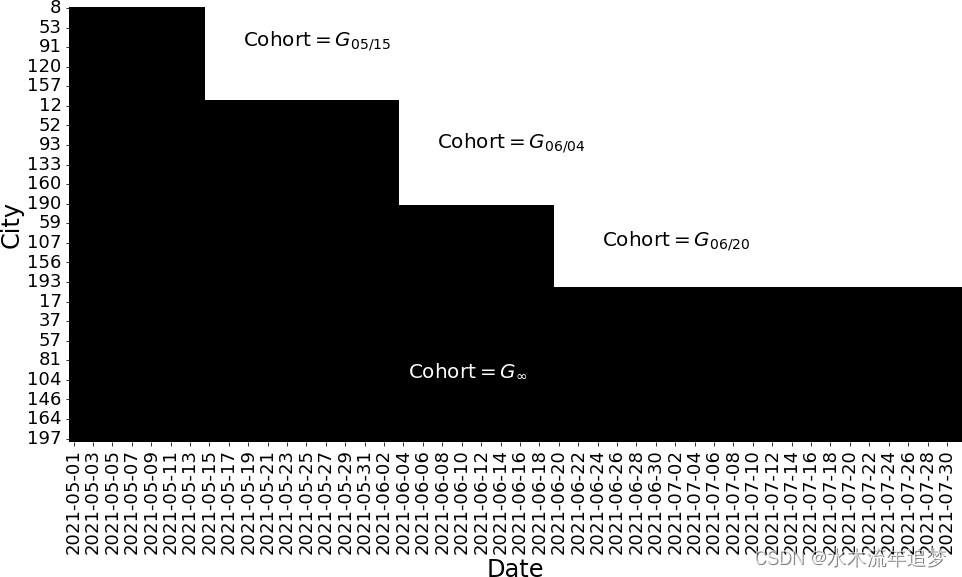 之前,您的数据截止到 2021-06-01,所以看起来您有一个小的干预组和一个巨大的从未干预组。但一旦扩展数据,就会发现线下营销活动后来扩展到了其他城市。现在,您有四个不同的队列,其中三个是治疗组,一个是从未治疗组(在此数据集中,队列为 2100-01-01)。
之前,您的数据截止到 2021-06-01,所以看起来您有一个小的干预组和一个巨大的从未干预组。但一旦扩展数据,就会发现线下营销活动后来扩展到了其他城市。现在,您有四个不同的队列,其中三个是治疗组,一个是从未治疗组(在此数据集中,队列为 2100-01-01)。
我们暂时不考虑协变量,只关注西部地区。稍后我会介绍如何处理协变量。现在,只关注问题中的交错采用部分:
mkt_data_cohorts_w = mkt_data_cohorts.query("region=='W'")
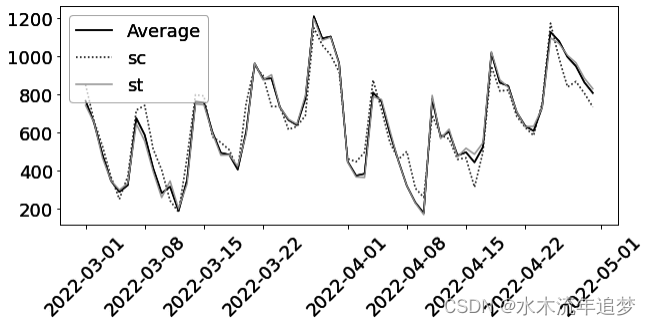
mkt_data_cohorts_w.head() 如果绘制出每个组群随着时间推移的平均下载量,就可以看到一幅清晰的图画。G = 05/15 的结果显示,在 2021-15-05 日之后,下载量立即增加。G = 06/04 和 G = 06/20 组的情况也是如此。与此同时,从未接受干预的组别在干预前似乎与接受干预的组别呈漂亮的平行趋势。另一个需要注意的问题是,这种效应需要一段时间才能成熟,这一点大家以前也见过。如果您绘制对齐队列后的结果,这一点会变得更加清晰,您可以在第二张图片中看到这一点:
如果绘制出每个组群随着时间推移的平均下载量,就可以看到一幅清晰的图画。G = 05/15 的结果显示,在 2021-15-05 日之后,下载量立即增加。G = 06/04 和 G = 06/20 组的情况也是如此。与此同时,从未接受干预的组别在干预前似乎与接受干预的组别呈漂亮的平行趋势。另一个需要注意的问题是,这种效应需要一段时间才能成熟,这一点大家以前也见过。如果您绘制对齐队列后的结果,这一点会变得更加清晰,您可以在第二张图片中看到这一点: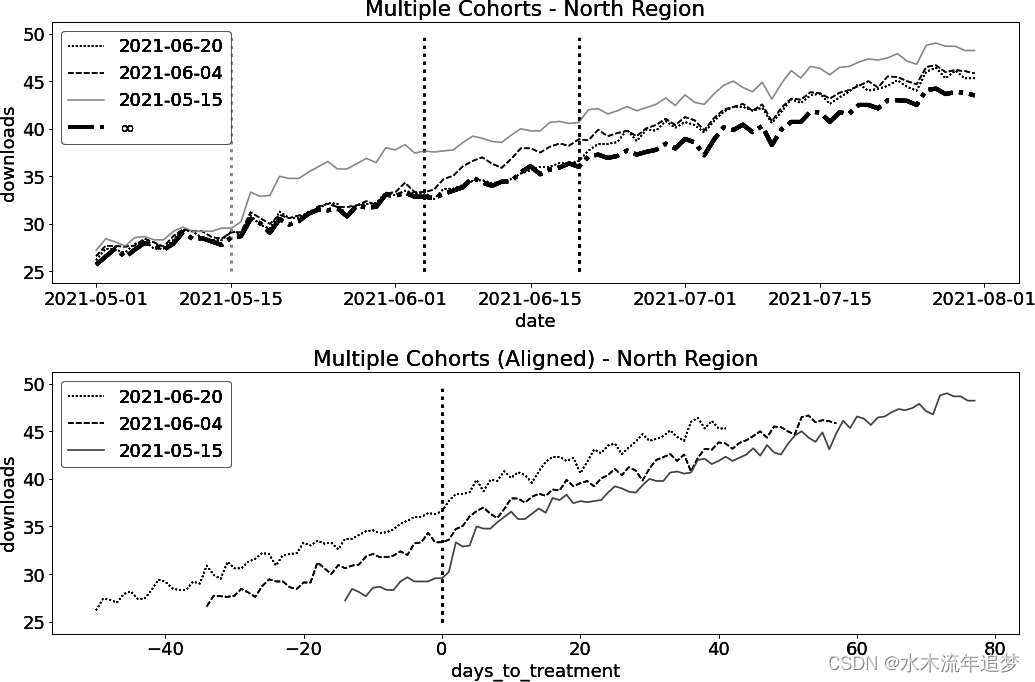
你可能会说,前面的数据表现得特别好,很明显是模拟出来的。你甚至可能会得出结论:"差异中的差异 "将毫无问题地恢复出真实的 ATT。好吧,让我们来试试:
twfe_model = smf.ols(
"downloads ~ treated:post + C(date) + C(city)",
data=mkt_data_cohorts_w
).fit()
true_tau = mkt_data_cohorts_w.query("post==1&treated==1")["tau"].mean()
print("True Effect: ", true_tau)
print("Estimated ATT:", twfe_model.params["treated:post"])
True Effect: 2.2625252108176266
Estimated ATT: 1.7599504780633743如你所见,有些不对劲。效果似乎向下偏移!这到底是怎么回事?
这个问题一直是最近关于面板数据的文献的中心。遗憾的是,如果我试图给你一个完整的解释,本章就太长了。我所能做的只是给你一瞥,如果你感兴趣,我还会为你指出更多的资源。这个问题的根源在于,当采用交错方法时,除了前面提到的传统 DID 假设外,还需要假定不同时间的影响是同质的。如前所述,本数据的情况并非如此。效应需要一段时间才能成熟,也就是说,干预刚开始时,效应较低,之后逐渐攀升。这种随时间变化的效应会导致 ATT 估计值出现偏差。
让我们研究两组城市来了解原因。第一组,我称之为早期干预组群,于 2004 年 6 月接受干预。第二组,我称之为后期干预组,他们在 06/20 日接受了干预。您刚才估计的双向固定效应模型实际上使用了一系列 2 × 2 差异运行,并将它们合并为最终估计值。在其中一次运行中,模型以晚期干预组为对照,估计了治疗对早期干预组的影响。这是有道理的,因为晚期治疗组可视为尚未治疗组。然而,该模型也是以早期治疗组作为对照来估计晚期治疗组的效果。这种方法是可以接受的,但前提是干预效果不随时间变化。您可以从下图中看出原因。图中显示了两种比较结果以及估计的反事实 Y0。值得注意的是,每个队列所扮演的角色在不同的图中是相反的:
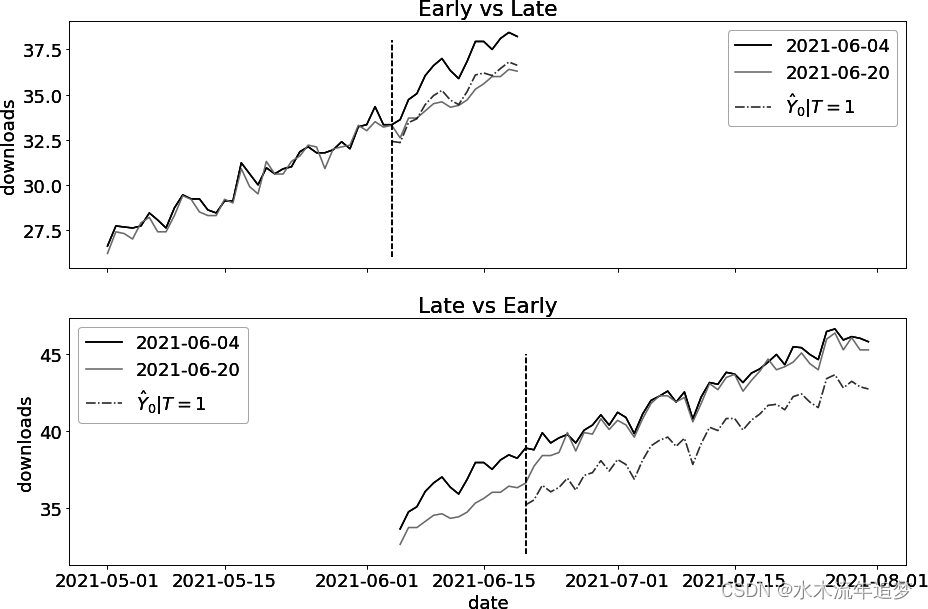
正如您所看到的,早期与晚期的比较似乎没有问题。问题在于晚期与早期的比较。对照组(06/04 组)已经接受了治疗,尽管它在这里起到了对照组的作用。此外,由于效应是异质性的,是逐渐攀升的,因此对照组(早期治疗组)的趋势要比尚未治疗组的趋势陡峭。这种逐渐增加的效应所带来的额外陡峭度会导致对对照组趋势的高估,进而导致对 ATT 估计值的向下偏差。这就是为什么如果治疗效果在不同时期是异质的,那么使用已经干预过的人群作为对照会使结果产生偏差。
既然知道了问题所在,就该看看解决办法了。既然问题出在效果的异质性上,那么解决方法就是使用一个更灵活的模型,一个能充分考虑到这些异质性的模型。