目录
在之前了解了面板数据在因果识别方面的优势。也就是说,你不仅可以比较单位之间的关系,还可以比较单位的前世今生,这样你就可以用更可信的假设来估计反事实 。您还了解了差分法(DID)及其多种变体,它是利用面板数据进行因果推理的众多工具之一。通过依赖干预对象和对照对象之间相似(平行)的增长轨迹,即使干预对象和对照对象之间的
水平不同,差分法也能识别治疗效果。在本文中,您将学习另一种流行的面板数据集技术:合成控制(SC)。
如果与时间段 T 相比,单位数 N 相对较多,那么 DID 的效果会很好,但如果情况相反,DID 的效果就会大打折扣。与此相反,合成控制的设计目的是在只有极少数甚至只有一个干预单位的情况下发挥作用。它背后的理念非常简单:将控制单元结合起来,以制作一个合成控制,使其近似于没有干预时受治疗单元的行为。这样做可以避免做出平行趋势假设,因为合成控制如果设计得好,就不仅仅是平行趋势,而是与反事实 完全重合。
在本文最后,您还将学习如何将 DID 和 SC 结合起来。这种组合估算器不仅功能强大,最重要的是,它将让你对差分和合成控制,特别是面板数据方法有一个全新的认识。
Online Marketing Dataset
作为合成控制的一个用例,您将使用一个在线营销数据集。与离线营销相比,在线营销可以进行更好的跟踪,但这并不意味着它对因果推理没有挑战。例如,在线营销的确可以更好地进行归因:您可以知道客户是否通过某个付费营销链接接触到您的产品。但这并不意味着你知道,如果顾客没有看到你的在线广告,他们会发生什么。也许客户只是因为看到了广告才来的,在这种情况下,广告会带来额外的客户。但也有可能,无论哪种方式,客户都会来,而他们通过付费链接来,只是因为该链接位于页面顶部。
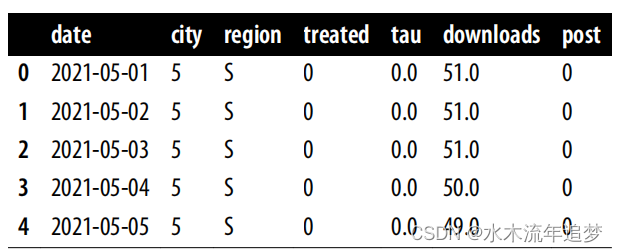
由于归因与增量不同,而且您无法随机化谁会看到您的广告,因此对整个地域进行处理并进行某种面板数据分析,就像上一章所说的那样,也是网络营销的一个好主意。因此,这里的数据与上一章中的数据并无太大区别。同样,城市是单位,日期是时间维度,治疗列标记城市是否最终接受了治疗,治疗后列标记干预后时期。此外,还有一些辅助列,如该城市的人口(记录于 2013 年,因此在时间上是固定的)和州:
import pandas as pd
import numpy as np
df = (pd.read_csv("./data/online_mkt.csv")
.astype({"date":"datetime64[ns]"}))
df.head()
在这里,干预变量是应用程序的日下载量,处理方
tr_period = df_norm.query("post==1")["date"].min()
tr_period
Timestamp('2022-05-01 00:00:00')法是在该城市开启营销活动。干预同时在接受干预的城市实施,这意味着您采用了简单的区组设计。这里的问题是,处理单位的数量要少得多,只有三个城市:
treated = list(df.query("treated==1")["city"].unique())
treated
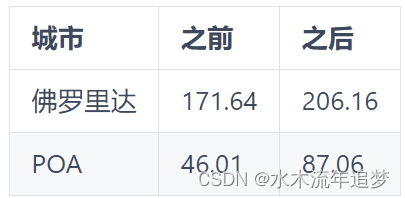
['sao_paulo', 'porto_alegre', 'joao_pessoa']如果您留意了数据框中的人口一栏,您可能会注意到,其中一个城市圣保罗拥有超过 1200 万的庞大人口。事实上,它是世界上最大的城市之一!这也意味着圣保罗的应用程序下载量将远远大于其他城市,这就带来了一些挑战。我们很难将其他城市的下载量与圣保罗的下载量结合起来进行合成控制。这个问题在这里更加严重,但一般来说,整个市场的规模都会不同,因此很难进行跨市场比较。因此,常用的方法是根据市场规模对结果进行归一化处理。这意味着将应用程序下载量除以城市人口数量,以创建一个归一化版本的结果。这个新的结果,即 app_download_pct,表示每日下载量占市场规模的百分比:
df_norm = df.assign(
app_download_pct = 100*df["app_download"]/df["population"]
)
df_norm.head() 
继续进行探索性分析,您会发现在 2022-05-01 年为这些城市发起了在线营销活动。在分析时间窗口的剩余时间内,该活动也一直在进行:
tr_period = df_norm.query("post==1")["date"].min()
tr_period
Timestamp('2022-05-01 00:00:00')现在是回顾一下您将要使用的一些面板符号的好时机。请记住,为避免混淆,我将用 D 表示干预变量,用 t 表示时间。T 将是期间数, 是干预前的期间数,
是干预后的期间数。因此,当 D = 1 且 t >
时,干预就开始了。为了简化,我有时会使用后虚拟变量来表示 t >
。干预和干预后的组合将用
表示。
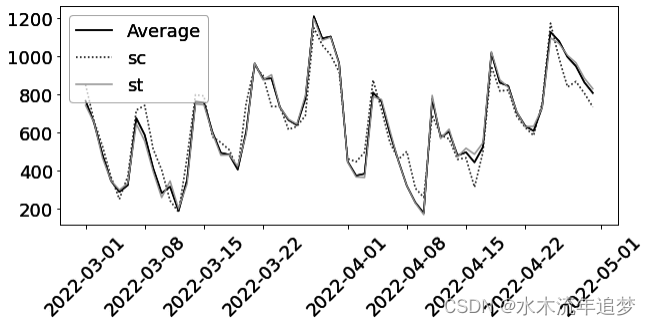
为了让您了解这些数据的情况,下图以浅灰色显示了三个接受治疗城市的平均结果的变化情况,背景则是对照城市的样本。水平虚线标出了干预后的起始时间:

从图中可以看出,干预后受治疗单位的结果有所上升,但并不是 100% 清晰。为了更精确,您必须对反事实进行估计,并将其与观察到的干预结果进行比较,从而得到对受干预者的平均治疗效果(ATT)的估计值:
这就是合成控制的作用所在。这是一种非常巧妙的方法,它利用(但不以)过去的结果来估计 。