目录
Generalized Propensity Score for Continuous Treatment
Outcome Is Easy to Model
在下一个简单而又能说明问题的例子中,复杂性在于 而不是
。注意
中的非线性,而结果函数是简单的线性。在这里,真正的 ATE 是-1:
np.random.seed(123)
n = 10000
x = np.random.beta(1,1, n).round(2)*2
e = 1/(1+np.exp(-(2*x - x**3)))
t = np.random.binomial(1, e)
y1 = x
y0 = y1 + 1 # ate of -1
y = t*(y1) + (1-t)*y0 + np.random.normal(0, 1, n)
df_easy_y = pd.DataFrame(dict(y=y, x=x, t=t))
print("True ATE:", np.mean(y1-y0))
True ATE: -1.0 可以用之前的同类曲线图来表示 的复杂函数形式和
的简单函数形式:
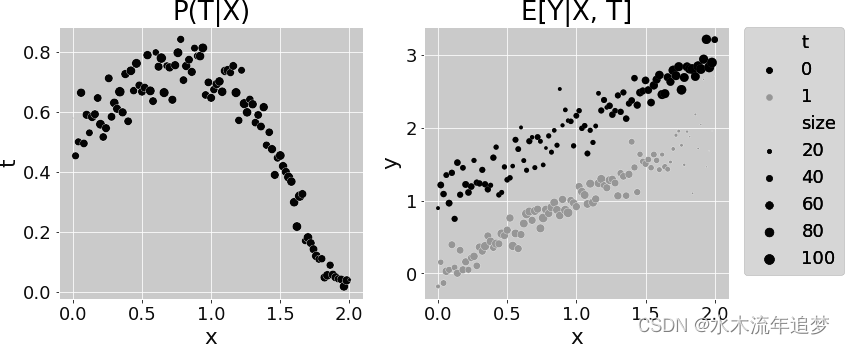
有了这些数据,由于倾向评分相对复杂,IPW无法恢复真正的ATE:
est_fn = partial(est_ate_with_ps, ps_formula="x", T="t", Y="y")
print("Propensity Score ATE:", est_fn(df_easy_y))
print("95% CI", bootstrap(df_easy_y, est_fn))
Propensity Score ATE: -1.1042900278680896
95% CI [-1.14326893 -1.06576358]但回归却设法准确地纠正了它:
m0 = smf.ols("y~x", data=df_easy_y.query("t==0")).fit()
m1 = smf.ols("y~x", data=df_easy_y.query("t==1")).fit()
regr_ate = (m1.predict(df_easy_y) - m0.predict(df_easy_y)).mean()
print("Regression ATE:", regr_ate)
Regression ATE: -1.0008783612504342同样,因为DR只需要正确指定一个模型,它还在这里恢复真正的ATE:
est_fn = partial(doubly_robust, formula="x", T="t", Y="y")
print("DR ATE:", est_fn(df_easy_y))
print("95% CI", bootstrap(df_easy_y, est_fn))
DR ATE: -1.0028459347805823
95% CI [-1.04156952 -0.96353366]我希望这两个例子能更清楚地说明为什么双重稳健估计会非常有趣。最重要的一点是,它让你有两次机会获得正确。在某些情况下,建立 模型很难,但建立
模型却很容易。而在其他情况下,情况可能正好相反。不管怎样,只要你能正确地建立其中一个模型,你就可以把
模型和
模型结合起来,只需其中一个正确即可。这就是双重稳健估计器的真正威力。
Generalized Propensity Score for Continuous Treatment
到目前为止,只展示了如何将倾向分数用于离散干预。这是有道理的。连续干预处理起来要复杂得多。以至于我可以说,作为一门科学,因果推断对如何处理连续处理并没有很好的答案。
通过假设干预反应的函数形式,你设法摆脱了连续干预。比如 y = a + bt(线性形式)或 y = a + b t(平方根形式),然后用 OLS 对其进行估计。但就倾向加权而言,并不存在参数反应函数。通过重新加权和取平均值,可以对潜在结果进行非参数估计。如果 T 是连续的,则存在无限多的潜在结果 Yt。此外,由于连续变量的概率总是零,因此在这种情况下估计 是不可行的。
要解决这些问题,最简单的办法就是把连续的干预离散化成一个更粗的版本,然后再把它当作离散的干预来处理。但还有另一条出路,那就是使用广义倾向得分。如果对传统的倾向得分做一些改动,就能适应任何类型的干预。请看下面的例子。
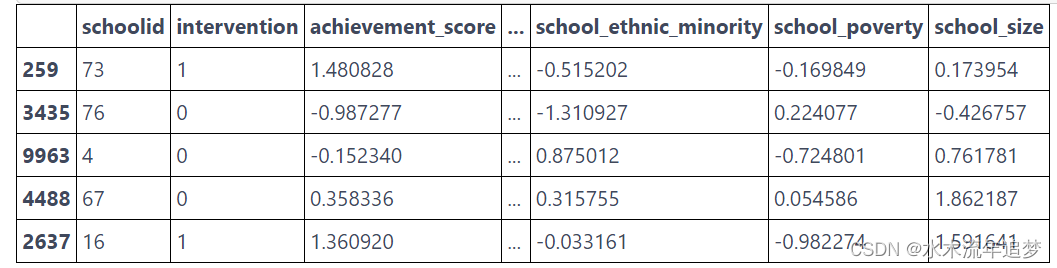
一家银行想知道贷款利率如何影响客户选择偿还贷款的期限(以月为单位)。直观地说,利息对贷款期限的影响应该是负的,因为人们喜欢尽快偿还高利率贷款,以避免支付过多的利息。
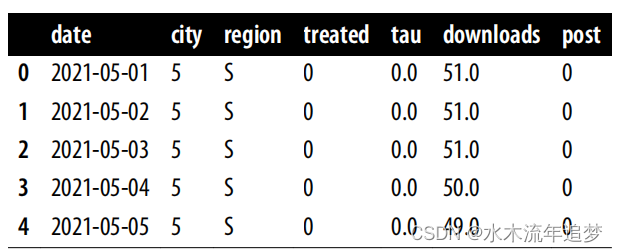
为了回答这个问题,银行可以随机调整利率,但这样做需要花费大量的金钱和时间。相反,银行希望利用已有的数据。银行知道利率是由两个机器学习模型 ml_1 和 ml_2 分配的。此外,由于银行的数据科学家非常聪明,他们在利率决策过程中加入了随机高斯噪声。这确保了政策的非确定性,也确保了不违反实在性假设。观察(非随机)利息数据以及混杂因素 ml_1 和 ml_2 和结果持续时间的信息存储在 df_cont_t 数据帧中:
df_cont_t = pd.read_csv("./data/interest_rate.csv")
df_cont_t.head()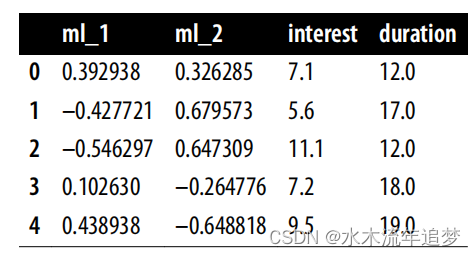
您的任务是在调整 ml_1 和 ml_2 后,消除利率与期限之间的偏差。请注意,如果你不对任何因素进行调整,直接估计干预效果,你会发现干预效果为正。如前所述,这在商业上是不合理的,因此这一结果很可能是有偏差的:
m_naive = smf.ols("duration ~ interest", data=df_cont_t).fit()
m_naive.summary().tables[1]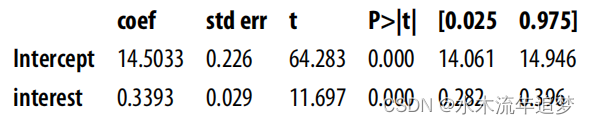
要调整 ml_1 和 ml_2,可以直接将它们纳入模型中,但让我们来看看如何通过重新加权来处理同样的问题。需要解决的第一个难题是连续变量在任何地方的概率都为零,即 。这是因为概率由密度下的面积表示,而单点的面积总是零。一种可能的解决方法是用条件密度函数
代替条件概率
。不过,这种方法会带来另一个问题,即指定干预的分布。
这里,为了简单起见,我们假设它是从正态分布 中提取的。这是一个相当合理的简化,尤其是因为正态分布可以用来近似其他分布。此外,我们假设方差 σ2 不变,而不是每个个体的方差都会变化。
回想一下,正态分布的密度由以下函数给出:
现在,您需要估计这个条件高斯的参数,即均值和标准差。最简单的方法是使用 OLS 来拟合干预变量:
model_t = smf.ols("interest~ml_1+ml_2", data=df_cont_t).fit()然后,拟合值将作为 μi,残差的标准偏差将作为 σ。这样,就得到了条件密度的估计值。接下来,您需要评估给定干预时的条件密度,这就是为什么我在下面的代码中将 T 传递给密度函数中的 x 参数:
def conditional_density(x, mean, std):
denom = std*np.sqrt(2*np.pi)
num = np.exp(-((1/2)*((x-mean)/std)**2))
return (num/denom).ravel()
gps = conditional_density(df_cont_t["interest"],
model_t.fittedvalues,
np.std(model_t.resid))
gps
array([0.1989118, 0.14524168, 0.03338421, ..., 0.07339096, 0.19365006,
0.15732008])或者,您可以(也可能应该)从scipy导入正态分布,并使用它来代替:
from scipy.stats import norm
gps = norm(loc=model_t.fittedvalues,
scale=np.std(model_t.resid)).pdf(df_cont_t["interest"])
gps
array([0.1989118, 0.14524168, 0.03338421, ..., 0.07339096, 0.19365006,
0.15732008])在回归模型中使用 GPS 的倒数作为权重可以调整偏差。您可以看到,现在您会发现利息对持续时间有负面影响,这在商业上更有意义:
final_model = smf.wls("duration~interest",
data=df_cont_t, weights=1/gps).fit()
final_model.params["interest"]
-0.6673977919925854还有一项可以改进的地方,这将使人们对全球定位系统有更直观的了解。使用这个分数来构建权重,将赋予不太可能有干预的点更大的重要性。具体来说,在您拟合的处理模型中,您将为残差较高的单位赋予较高的权重。此外,由于正态密度的指数性质,权重将随残差的大小呈指数增长。
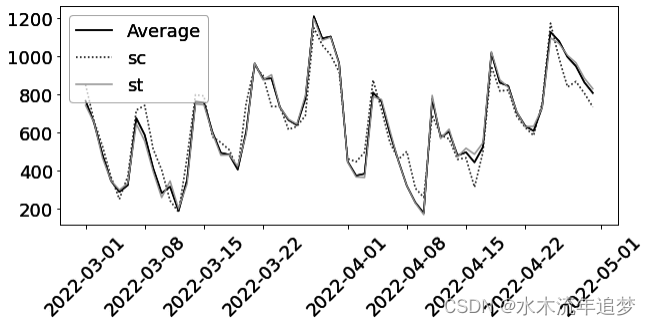
为了说明这一点,假设您只使用 ml_1 而不是 ml_1 和 ml_2 来拟合利率。这样的简化可以在一张图中显示所有内容。得出的权重显示在下图中。第一幅图显示的是原始数据,按混杂因素 ml_1 用颜色标示。ml_1 分数低的客户通常会选择较长的还款期限。此外,ml_1 分数低的客户会获得更高的利率。因此,利率与期限之间的关系存在向上偏差。
第二幅图显示了干预模型的拟合值以及 GPS 从该模型中得到的权重。离拟合线越远,权重越大。这是有道理的,因为 GPS 给不可能干预的处理赋予了更大的权重。但看看这些权重有多大。有些权重超过了 1000!
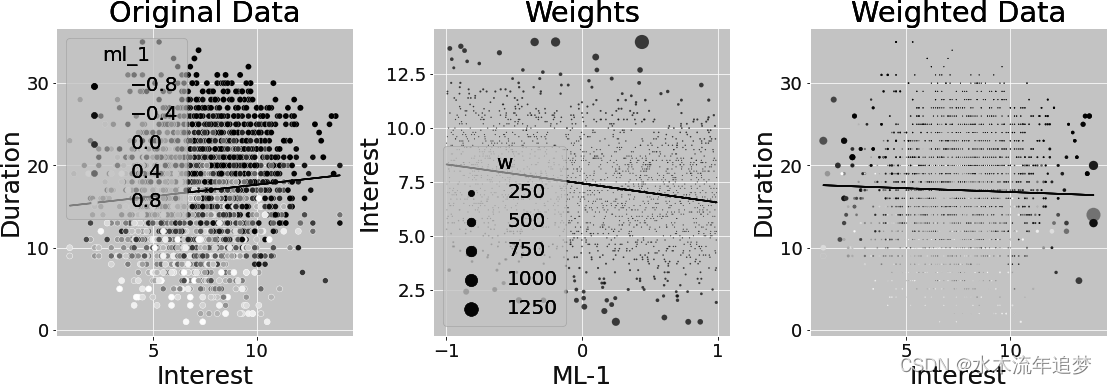
最后一幅图显示的是同样的权重,但却是利息和期限之间的关系。由于 ml_1 低值时的低利率和 ml_1 高值时的高利率都是不可能的,因此逆 GPS 权重对这些点给予了高度的重视。这就扭转了利息和期限之间的正向(偏向)关系。但这种估计方法的方差很大,因为它实际上只是使用了几个数据点--那些权重很高的数据点。此外,由于这个数据是模拟的,我知道真实的 ATE 是-0.8,但前面的估计值只有-0.66。
为了改进估计值,可以通过边际密度 来稳定权重。与离散干预不同,在离散干预中,权重稳定只是一个很好的条件,而在 GPS 中,我认为这是必须的。要估算
,可以简单地使用平均干预值。然后,在给定的干预下评估由此得到的密度。
请注意,这样得出的权重总和(几乎)等于原始样本量。从重要性抽样的角度来考虑,这些权重将您从 带到
,即处理不依赖于 x 的密度:
stabilizer = norm(
loc=df_cont_t["interest"].mean(),
scale=np.std(df_cont_t["interest"] - df_cont_t["interest"].mean())
).pdf(df_cont_t["interest"])
gipw = stabilizer/gps
print("Original Sample Size:", len(df_cont_t))
print("Effective Stable Weights Sample Size:", sum(gipw))
Original Sample Size: 10000
Effective Stable Weights Sample Size: 9988.19595174861再次,假设只使用 ml_1 对 进行拟合,以了解发生了什么。再一次,反倾向加权给与远离干预模型拟合值的点很高的重要性,因为它们属于
的低密度区域。 但此外,稳定也给与远离
的点,即远离均值的点很低的重要性。结果是双重的。首先,稳定后的权重更小,从而降低了方差。其次,我们可以更清楚地看到,我们现在更重视 ml_1 值低和利率低的点(反之亦然)。从第一张图和第三张图之间颜色模式的变化可以看出这一点:
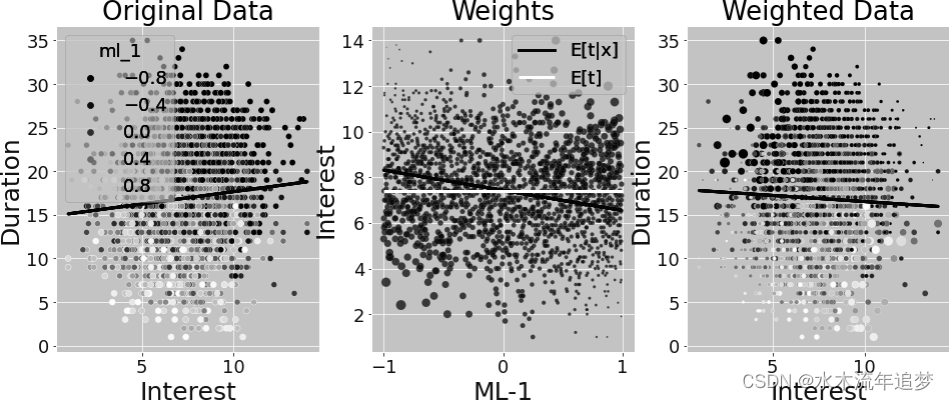
此外,这些稳定的权重给你的估计是更接近真实的ATE-0.8:
final_model = smf.wls("duration ~ interest",
data=df_cont_t, weights=gipw).fit()
final_model.params["interest"]
-0.7787046278134069正如您所看到的,尽管体重稳定在 T 是离散的情况下没有影响,但对于连续干预来说却非常重要。它能让你更接近你试图估计的参数的真实值,还能显著减少方差。由于有些重复,我省略了计算估计值 95% CI 的代码,但这与您之前所做的差不多:只需将整个过程封装在一个函数中并进行引导。不过,为了让你自己看清楚,下面是有稳定化和没有稳定化的 95% CI: