支持向量机(SVM)理论知识推导
支持向量机(Support Vector Machine, SVM)是一种用于分类和回归分析的监督学习模型。其主要目的是找到一个能够分离不同类别的超平面。
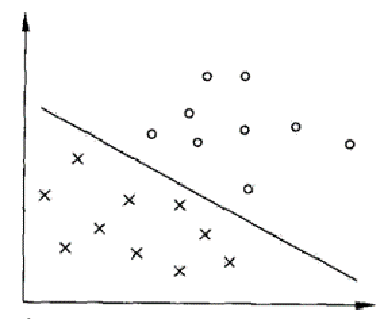
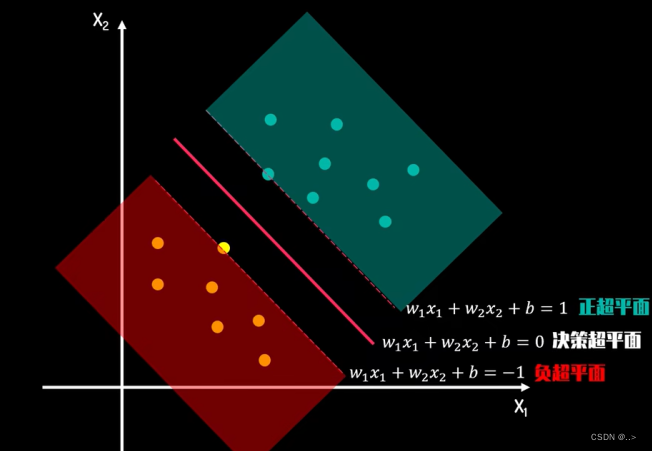
线性可分情况下的SVM



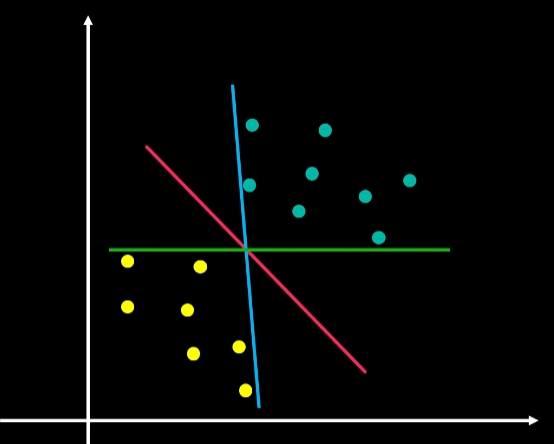
非线性情况下的SVM

常见的核函数包括:

实施步骤与参数解读
- 数据预处理:数据标准化或归一化。
- 选择核函数与参数:选择合适的核函数(如RBF)和参数(如
和
)。
- 模型训练:使用训练数据拟合SVM模型。
- 模型预测与评估:使用测试数据进行预测,并计算模型的性能指标(如准确率)。
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.svm import SVC
from sklearn.metrics import classification_report, accuracy_score
# 设置全局字体为楷体
plt.rcParams['font.family'] = 'KaiTi'
# 生成多维数据集
X, y = datasets.make_classification(n_samples=500, n_features=5, n_informative=3, n_redundant=2, random_state=42)
# 数据标准化
scaler = StandardScaler()
X = scaler.fit_transform(X)
# 数据集划分
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 未优化模型
clf_unoptimized = SVC(kernel='rbf')
clf_unoptimized.fit(X_train, y_train)
y_pred_unoptimized = clf_unoptimized.predict(X_test)
# 输出未优化模型的结果
print("未优化模型的分类报告:")
print(classification_report(y_test, y_pred_unoptimized))
print("未优化模型的准确率:", accuracy_score(y_test, y_pred_unoptimized))
# 优化后的模型
clf_optimized = SVC(kernel='rbf', C=10, gamma=0.1)
clf_optimized.fit(X_train, y_train)
y_pred_optimized = clf_optimized.predict(X_test)
# 输出优化后的模型的结果
print("优化后的模型的分类报告:")
print(classification_report(y_test, y_pred_optimized))
print("优化后的模型的准确率:", accuracy_score(y_test, y_pred_optimized))
# 可视化
plt.figure(figsize=(12, 6))
# 选取二维特征进行可视化
X_vis = X_test[:, :2]
y_vis = y_test
# 未优化模型的可视化
plt.subplot(1, 2, 1)
plt.scatter(X_vis[y_vis == 0][:, 0], X_vis[y_vis == 0][:, 1], color='blue', label='Class 0')
plt.scatter(X_vis[y_vis == 1][:, 0], X_vis[y_vis == 1][:, 1], color='red', label='Class 1')
plt.title('未优化模型')
plt.xlabel('Feature 1')
plt.ylabel('Feature 2')
plt.legend()
# 优化后的模型的可视化
plt.subplot(1, 2, 2)
plt.scatter(X_vis[y_vis == 0][:, 0], X_vis[y_vis == 0][:, 1], color='blue', label='Class 0')
plt.scatter(X_vis[y_vis == 1][:, 0], X_vis[y_vis == 1][:, 1], color='red', label='Class 1')
plt.title('优化后的模型')
plt.xlabel('Feature 1')
plt.ylabel('Feature 2')
plt.legend()
plt.show()


结果解释
- 未优化模型:使用默认参数的非线性SVM,分类报告和准确率较低,可能因为未选择合适的超参数。
- 优化后的模型:调整了超参数
可视化图展示
- 未优化模型:二维特征的可视化显示了数据分布和分类结果,可以看到分类边界不够明确。
- 优化后的模型:优化后的模型分类边界更加清晰,分类结果更接近实际情况。
通过上述步骤,我们实现了非线性支持向量机的训练和优化,并通过可视化对比了两个模型的效果。