支持向量机(SVM,Support Vector Machines)是一种广泛使用的监督学习方法,适用于分类、回归和其他任务。SVM的核心思想是找到一个最优的决策边界(在二维空间中是一条线,在更高维度是一个超平面),以此来区分不同类别的数据点。SVM试图将这个决策边界与最近的训练数据点(即支持向量)之间的距离最大化,以增强模型的泛化能力。
下面是SVM从底层到高层的详细讲解:
线性SVM
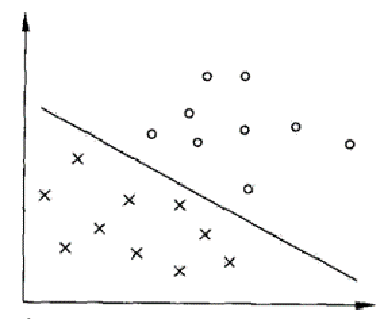
线性SVM专注于在数据特征空间中寻找一个最优的线性超平面,该超平面能够正确分离不同类别的数据点。
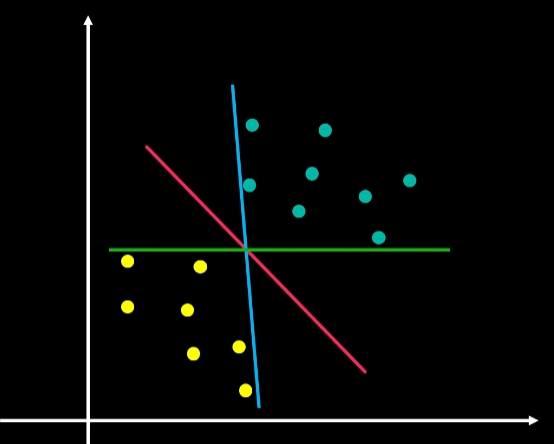
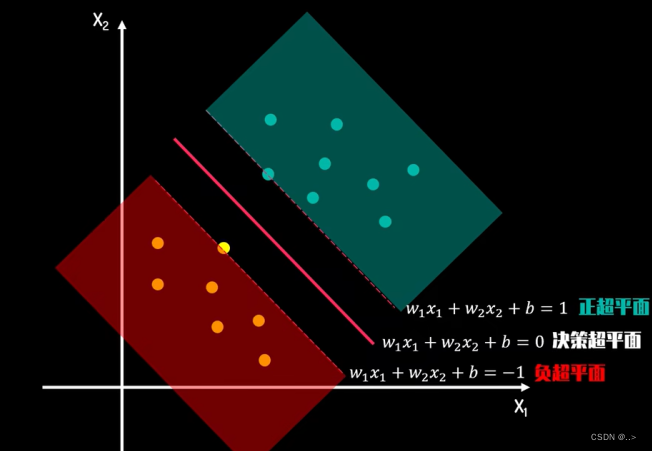
- 决策边界:在二分类问题中,假设我们有两类数据点,线性SVM的目标是找到一个超平面((w \cdot x + b = 0),其中(w)是权重向量,(b)是偏置项),使得正类和负类数据点被该超平面分开。
- 最大间隔:SVM通过最大化决策边界与最近数据点之间的距离(即间隔)来选择最优的超平面。这些最近的数据点称为支持向量,它们直接影响决策边界的位置和方向。
- 优化问题:找到这样的(w)和(b),可以通过求解一个凸二次规划问题来实现,目标函数是最小化(\frac{1}{2}||w||^2),同时满足约束条件(y_i(w \cdot x_i + b) \geq 1),对于所有的训练样本(i)。这里(y_i)是每个样本的标签,取值为+1或-1。
核技巧
当数据不是线性可分时,线性SVM就无法有效工作。这时,可以应用核技巧将原始特征映射到一个更高维的空间,使得数据在这个新空间中线性可分。
- 核函数:核技巧通过一个核函数来隐式地完成这种高维映射,而不需要直接计算映射后的数据点。常用的核函数包括线性核、多项式核、径向基函数(RBF)核和sigmoid核。
- 映射到高维空间:在这个高维特征空间中,数据点的分布可能会变得线性可分。然后,SVM可以像处理线性可分数据那样来找到一个最优的决策边界。
模型训练
- 损失函数:SVM的损失函数设计为合页损失(hinge loss),它对于正确分类且离决策边界足够远的样本不会累积损失,而对于分类错误或离决策边界过近的样本会累积损失。
- 优化算法:求解SVM的优化问题通常使用序列最小优化(SMO)算法或其他凸优化算法。SMO算法通过一次只优化一对参数来高效地解决问题。
多类分类
虽然SVM本质上是一个二分类器,但它可以通过一对一(OvO)或一对多(OvR)策略被扩展到多类分类问题。
SVM的优势
- 有效处理高维空间:SVM在处理高维数据(特征多)时表现出色,即使在数据维度超过样本数量的情况下也能有效工作。
- 适用于复杂数据集:通过使用合适的核函数,SVM可以有效处理线性不可分的数据集。
- 泛化能力强:SVM试图最大化决策边界的边缘,因此通常泛化错误率低,即在未见过的数据上的表现比较好。
- 模型简洁:SVM模型基本上由支持向量决定,这意味着模型不仅简洁,而且决策函数只依赖于少数数据点,从而提高了模型的解释性。
- 灵活性:通过选择不同的核函数,SVM可以适
应不同类型的数据特征分布,包括线性和非线性关系。
SVM的局限
- 参数选择敏感:SVM的性能在很大程度上依赖于核函数的选择以及核函数参数(如RBF核的γ)和正则化参数C的设置。不恰当的参数选择可能导致过拟合或欠拟合。
- 大规模数据集处理:对于非常大的数据集,SVM的训练时间可能非常长,这主要是因为优化问题的复杂性。尽管有一些改进的算法(如近似训练技术),但在处理大规模数据时,SVM可能不如一些线性模型或基于树的模型高效。
- 概率估计困难:SVM本身不直接提供概率估计,虽然可以通过额外的五折交叉验证步骤来获得这些估计,但这会增加计算成本。
- 多类分类问题:虽然SVM可以扩展到多类分类,但这种扩展通常涉及将多类问题分解为多个二类问题,这增加了训练和优化的复杂性。
- 数据预处理和特征缩放:SVM对特征的缩放非常敏感,因此在应用SVM之前需要仔细地数据预处理,特别是进行特征缩放。
代码实现
我们可以使用Python中的Scikit-learn库
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.svm import SVC
# 加载数据集,这里我们使用内置的鸢尾花(Iris)数据集
iris = datasets.load_iris()
X = iris.data
y = iris.target
# 为了简化问题,我们只使用前两个特征,并且只处理二分类问题
X = X[:, :2]
y = y[y < 2]
# 划分数据集为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 特征缩放
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
# 训练线性SVM分类器
svm = SVC(kernel='linear', C=1.0)
svm.fit(X_train_scaled, y_train)
# 测试集上的准确率
accuracy = svm.score(X_test_scaled, y_test)
print(f"测试集准确率: {
accuracy:.2f}")
这段代码首先加载鸢尾花数据集,然后选择了前两个特征和两个类别来简化为一个二分类问题。之后,数据集被划分为训练集和测试集,特征进行了标准化处理(这是SVM训练前的重要步骤之一)。最后,使用线性核函数训练SVM分类器,并在测试集上评估其准确率。
注意,这个简单的例子只使用了线性核,并且处理了一个二分类问题。对于非线性可分的数据集,你可能需要使用不同的核函数(如RBF核),Scikit-learn的SVC类同样支持通过kernel参数选择不同的核函数。而且,对于多类分类问题,Scikit-learn会自动应用一对一(OvO)或一对多(OvR)策略,无需用户手动实现。