K近邻算法(K-Nearest-Neighbor, KNN)是一种用于分类和回归的非参数统计方法,是机器学习最基础的算法之一。它正是基于以上思想:要确定一个样本的类别,可以计算它与所有训练样本的距离,然后找出和该样本最接近的k个样本,统计出这些样本的类别并进行投票,票数最多的那个类就是分类的结果。KNN的三个基本要素:
K值,一个样本的分类是由K个邻居的“多数表决”确定的。K值越小,容易受噪声影响,反之,会使类别之间的界限变得模糊。
距离度量,反映了特征空间中两个样本间的相似度,距离越小,越相似。常用的有Lp距离(p=2时,即为欧式距离)、曼哈顿距离、海明距离等。
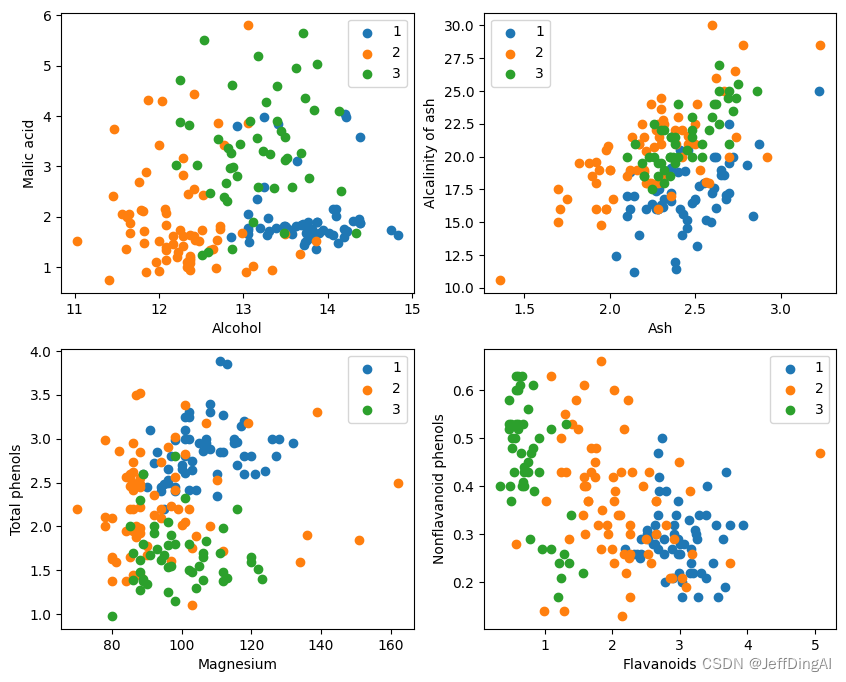
如果两个东西是可以分类的,只要把这个东西的每个属性当成一个维度数据输入,那么一定是可以分开的。
类似下图数据,必然存在一条虚线,可以把他们分为两类。

如果是三维的数据,可以找到二维面把他们分开。依此类推…







































![[ACM独立出版]2024年虚拟现实、图像和信号处理国际学术会议(ICVISP 2024)](https://img-blog.csdnimg.cn/img_convert/67b64be0ec3791a39b833c5bd583a1a4.png)