目录
标准误差

为了计算 IPTW 估计量的标准误差,我们可以使用加权平均方差的公式。
但是,只有当我们有真实的倾向得分时,我们才能使用它。 如果我们使用它的估计版本,,我们需要考虑这个估计过程中的错误。 最简单的方法是引导整个过程。 这是通过从原始数据中进行自助法采样(bootstrapping)并像我们上面所做的那样计算 ATE 来实现的。 然后我们重复多次以获得 ATE 估计的分布。
from joblib import Parallel, delayed # for parallel processing
# define function that computes the IPTW estimator
def run_ps(df, X, T, y):
# estimate the propensity score
ps = LogisticRegression(C=1e6).fit(df[X], df[T]).predict_proba(df[X])[:, 1]
weight = (df[T]-ps) / (ps*(1-ps)) # define the weights
return np.mean(weight * df[y]) # compute the ATE
np.random.seed(88)
# run 1000 bootstrap samples
bootstrap_sample = 1000
ates = Parallel(n_jobs=4)(delayed(run_ps)(data_with_categ.sample(frac=1, replace=True), X, T, Y)
for _ in range(bootstrap_sample))
ates = np.array(ates)ATE 是自助法采样样本的平均值。 为了获得置信区间,我们可以自助法采样分布的分位数。 对于 95% C.I.,我们使用 2.5 和 97.5 百分位数。
print(f"ATE: {ates.mean()}")
print(f"95% C.I.: {(np.percentile(ates, 2.5), np.percentile(ates, 97.5))}")
ATE: 0.3877452824895804
95% C.I.: (0.35448188811098386, 0.41992764030841984)我们还可以直观地了解引导样本的外观以及置信区间。
sns.distplot(ates, kde=False)
plt.vlines(np.percentile(ates, 2.5), 0, 30, linestyles="dotted")
plt.vlines(np.percentile(ates, 97.5), 0, 30, linestyles="dotted", label="95% CI")
plt.title("ATE Bootstrap Distribution")
plt.legend();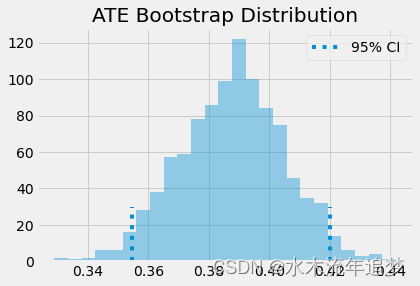
倾向得分的常见问题
作为一名数据科学家,我知道使用机器学习工具包的所有功能来使倾向得分估计尽可能精确是很诱人的。你很快就会被 AUC 优化、交叉验证和贝叶斯超参数调优这些很炫的技术所吸引。我现在并不是说你不应该那样做。事实上,所有关于倾向得分和机器学习的理论都是最近才出现的,所以还有很多我们还不知道的。但首先对一些基础的东西加以理解是值得的。
首先,倾向得分的预测质量并不能转化为它的平衡特性。对于来自机器学习领域的人来说,要学好因果推理,最具挑战性的方面之一就是放弃将所有事情都视为预测问题。事实上,最大化倾向得分的预测能力甚至会损害因果推理的目标。 倾向评分不需要很好地预测干预。它只需要包含所有混淆变量。如果我们包括在预测干预方面非常好的变量,但对结果没有影响,这实际上会增加倾向评分估计量的方差。当我们包含与干预相关但与结果无关的变量时,这类似于线性回归面临的问题。

要了解这一点,请考虑以下示例(改编自 Hernán's 的书 Causal Inference: What If)。 假设有 2 所学校,其中一所将成长心态研讨会应用于 99% 的学生,另一所则应用于 1%。 假设学校对干预效果没有影响(即只通过干预分配进行影响),则无需对其进行控制。 如果将学校变量添加到倾向得分模型中,它将具有非常高的预测能力。 然而,有一种可能,我们最终得到一个样本,其中学校 A 的每个人都接受了干预,导致该学校的倾向得分为 1,这将导致无限方差。 这是一个极端的例子,但让我们通过模拟数据来看看具体是怎么实现的。
np.random.seed(42)
school_a = pd.DataFrame(dict(T=np.random.binomial(1, .99, 400), school=0, intercept=1))
school_b = pd.DataFrame(dict(T=np.random.binomial(1, .01, 400), school=1, intercept=1))
ex_data = pd.concat([school_a, school_b]).assign(y = lambda d: np.random.normal(1 + 0.1 * d["T"]))
ex_data.head()
在模拟了这些数据后,我们运行两次自助法采样(bootstrapping),并对采样样本使用倾向得分算法。 第一次,倾向评分模型中包括了学校作为一个特征。 第二次,模型中不包括学校。
ate_w_f = np.array([run_ps(ex_data.sample(frac=1, replace=True), ["school"], "T", "y") for _ in range(500)])
ate_wo_f = np.array([run_ps(ex_data.sample(frac=1, replace=True), ["intercept"], "T", "y") for _ in range(500)])
sns.distplot(ate_w_f, kde=False, label="PS W School")
sns.distplot(ate_wo_f, kde=False, label="PS W/O School")
plt.legend();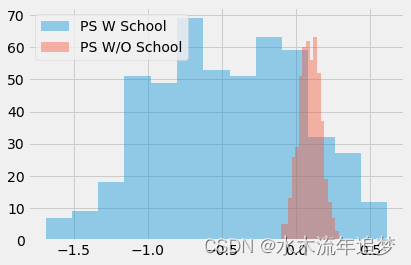
如你所见,添加学校这个特征的倾向得分估计器具有巨大的方差,而没有这个特征的倾向得分估计器表现得更好。 此外,由于学校不是混淆因子,因此没有它的模型也没有偏差。 正如我所说,简单地预测是否进行了干预并不是重点。 我们在进行预测的时候,实际上需要以控制混淆因子为目的来构建模型,而不是以对干预变量本身进行预测为目的。
这导致了倾向评分方法中经常遇到的另一个问题。 比如在我们的心态案例中,数据显然是非常平衡的。 但实际情况并非总是如此。 在某些情况下,接受干预的人比未经干预的人有更高的被干预概率,从而导致倾向得分分布没有太多重叠。(从而违背了positivity这个假设)
sns.distplot(np.random.beta(4,1,500), kde=False, label="Non Treated")
sns.distplot(np.random.beta(1,3,500), kde=False, label="Treated")
plt.title("Positivity Check")
plt.legend();
如果发生这种情况,则意味着正值性(positivity)不是很强。如果接受干预的人的倾向得分为 0.9,而未经干预的人的最大倾向得分为 0.7,那么我们将没有任何未经干预的人与倾向得分为 0.9 的个体进行比较。这种缺乏平衡会产生一些偏差,因为我们必须将干预结果外推到未知区域。不仅如此,倾向得分非常高或非常低的实体具有非常高的权重,这会增加方差。作为一般经验法则,如果任何权重高于 20(倾向得分为 0.95 的未干预样本或倾向得分为 0.05 的被干预样本都会发生这种情况),您就会遇到麻烦。
另一种方法是将权重限制为最大 20。这将减少方差,但实际上会产生更多偏差。老实说,虽然这是减少差异的常见做法,但我并不喜欢它。你永远不会知道你用剪裁(clipping)引起的偏差是否太大。此外,如果分布不重叠,那么您的数据可能还不足以得出因果结论。为了进一步了解这一点,我们可以研究一种结合倾向得分和匹配的技术
倾向得分匹配
正如我之前所说,当你有倾向得分时,你不需要控制 X。 控制它就足够了。 因此,您可以将倾向得分视为对特征空间执行一种降维。 它将 X 中的所有特征浓缩到一个单一的处理分配维度中。 因此,我们可以将倾向得分视为其他模型的输入特征。 以回归模型为例。
smf.ols("achievement_score ~ intervention + propensity_score", data=data_ps).fit().summary().tables[1]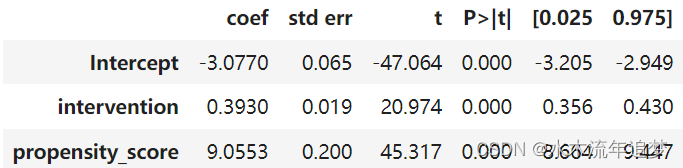
如果我们控制倾向得分,我们现在估计 ATE 为 0.39,低于我们之前使用回归模型而不控制倾向得分得到的 0.47。 我们还可以在倾向得分上使用匹配。 这一次,我们可以找到仅具有相同倾向得分的匹配,而不是试图找到所有 X 特征中相似的匹配。
这是对匹配估计器的巨大改进,因为它处理了维度灾难。 此外,如果一个特征对干预的分配不重要,倾向评分模型将学习这一点,并在拟合干预机制时对其给予较低的重要性。 另一方面,特征匹配仍然会尝试找到个人在这个不重要特征上相似的匹配。
cm = CausalModel(
Y=data_ps["achievement_score"].values,
D=data_ps["intervention"].values,
X=data_ps[["propensity_score"]].values
)
cm.est_via_matching(matches=1, bias_adj=True)
print(cm.estimates)
正如我们所看到的,我们也得到了 0.38 的 ATE,这更符合我们之前通过倾向得分加权看到的结果。 倾向得分的匹配也让我们对为什么在干预和未干预之间的倾向得分有小的重叠是危险的有一些直觉。 如果发生这种情况,倾向得分差异的匹配将很大,这将导致偏差,正如我们在匹配章节中看到的那样。
最后要注意的是,上述标准误差是错误的,因为它们没有考虑倾向得分估计的不确定性。 不幸的是,自助法(bootstrap)不适用于匹配。 此外,上述理论太新了,以至于没有具有正确标准误差的倾向评分方法的 Python 实现。 出于这个原因,我们在 Python 中看不到很多倾向得分匹配。
关键思想
在这里,我们了解到接受干预的概率称为倾向得分,我们可以将其用作平衡得分。这意味着,如果我们有倾向得分,我们就不需要直接控制混杂因素。为了识别因果效应,控制倾向得分就足够了。我们看到了倾向得分如何作为混杂空间的降维。
这些属性使我们能够推导出因果推理的加权估计量。不仅如此,我们还看到了如何将倾向得分与其他方法一起使用来控制混杂偏差。
然后,我们研究了倾向得分和一般因果推理可能出现的一些常见问题。第一个是当我们被分配干预机制的任务所迷惑时。我们看到,以一种非常违反直觉(因此很容易出错)的方式,提高接受干预可能的预测性反而不会转化为更好的因果估计,因为它会增加方差。
最后,我们研究了一些外推问题,如果我们无法在干预和未干预的倾向得分分布之间有良好的重叠,我们可能会遇到这些问题。