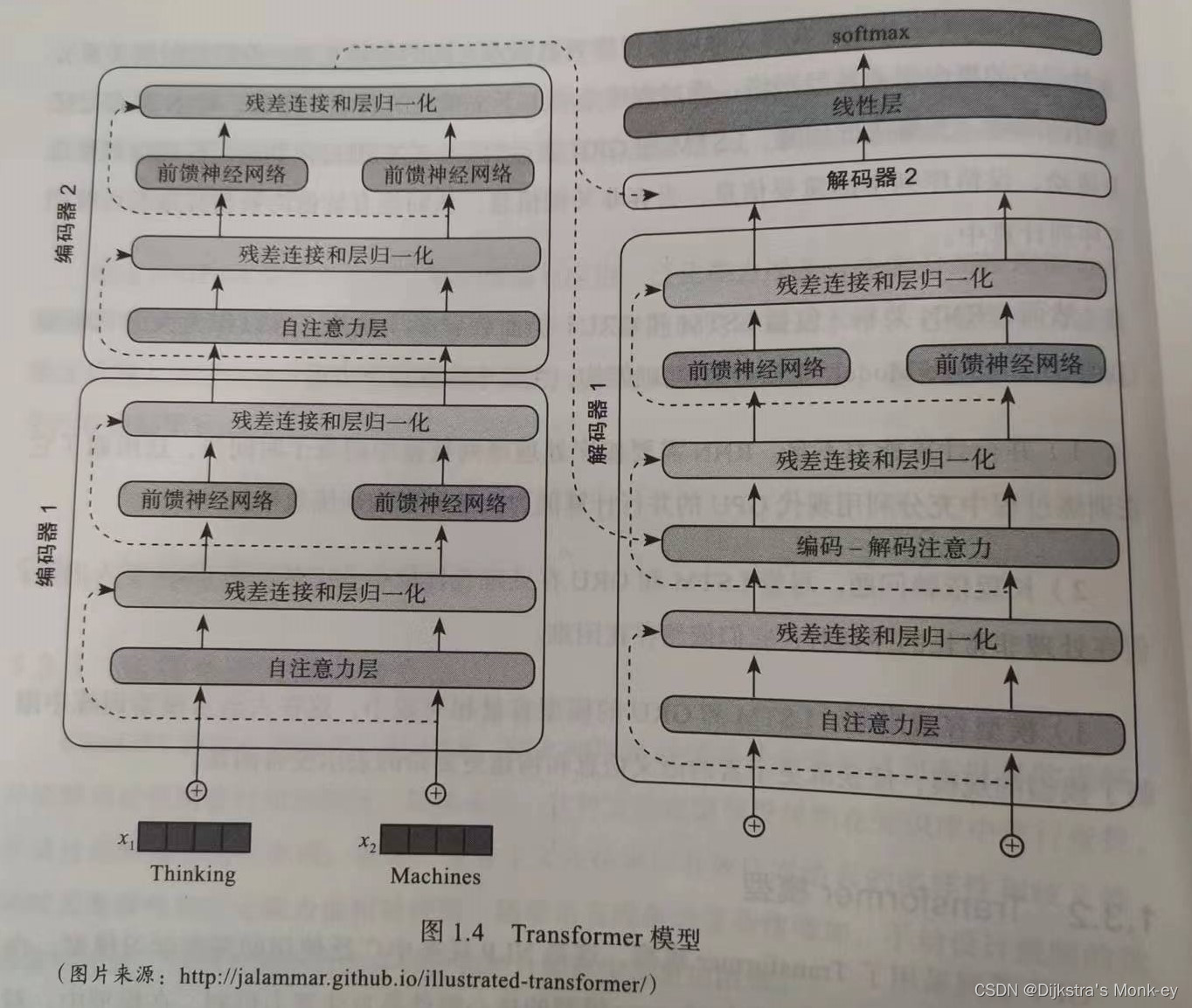
课程
(这节也是边看课边装环境~)

背景

我自己的理解,就是一个“固化”模型让它能够持续吞吐的操作。

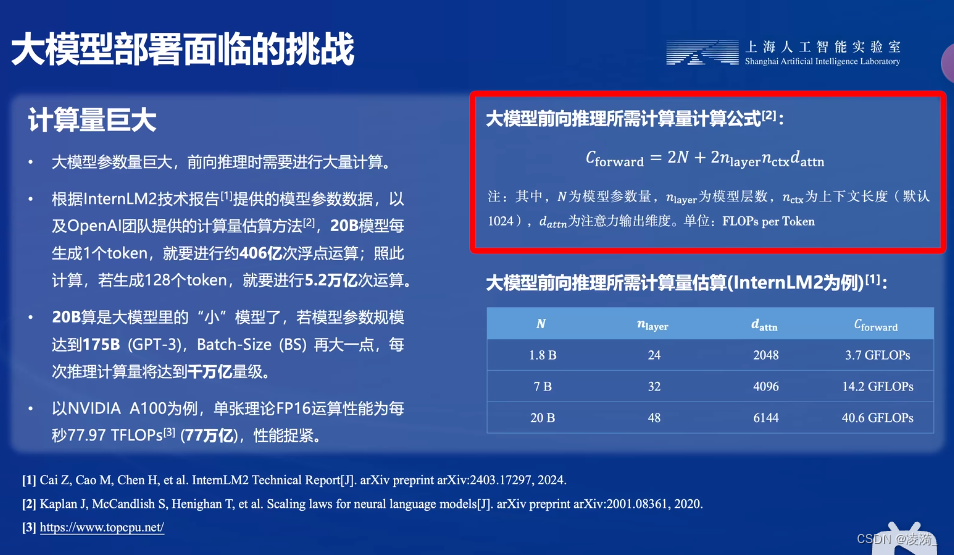
性能捉紧是啥……
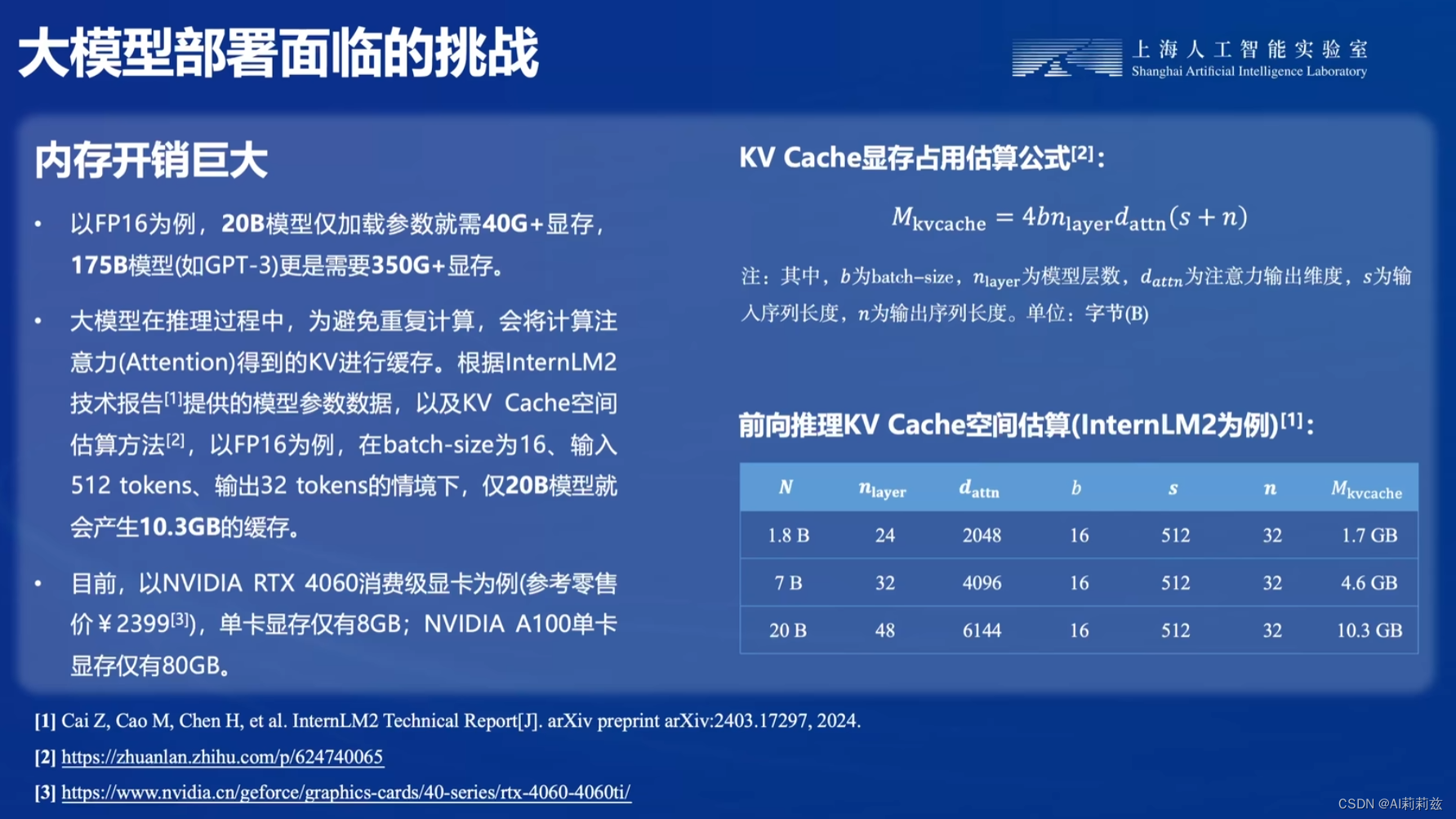

这几页对我来说是新知了,之前很少了解这些计算细节。
常见部署方法



LMDeploy

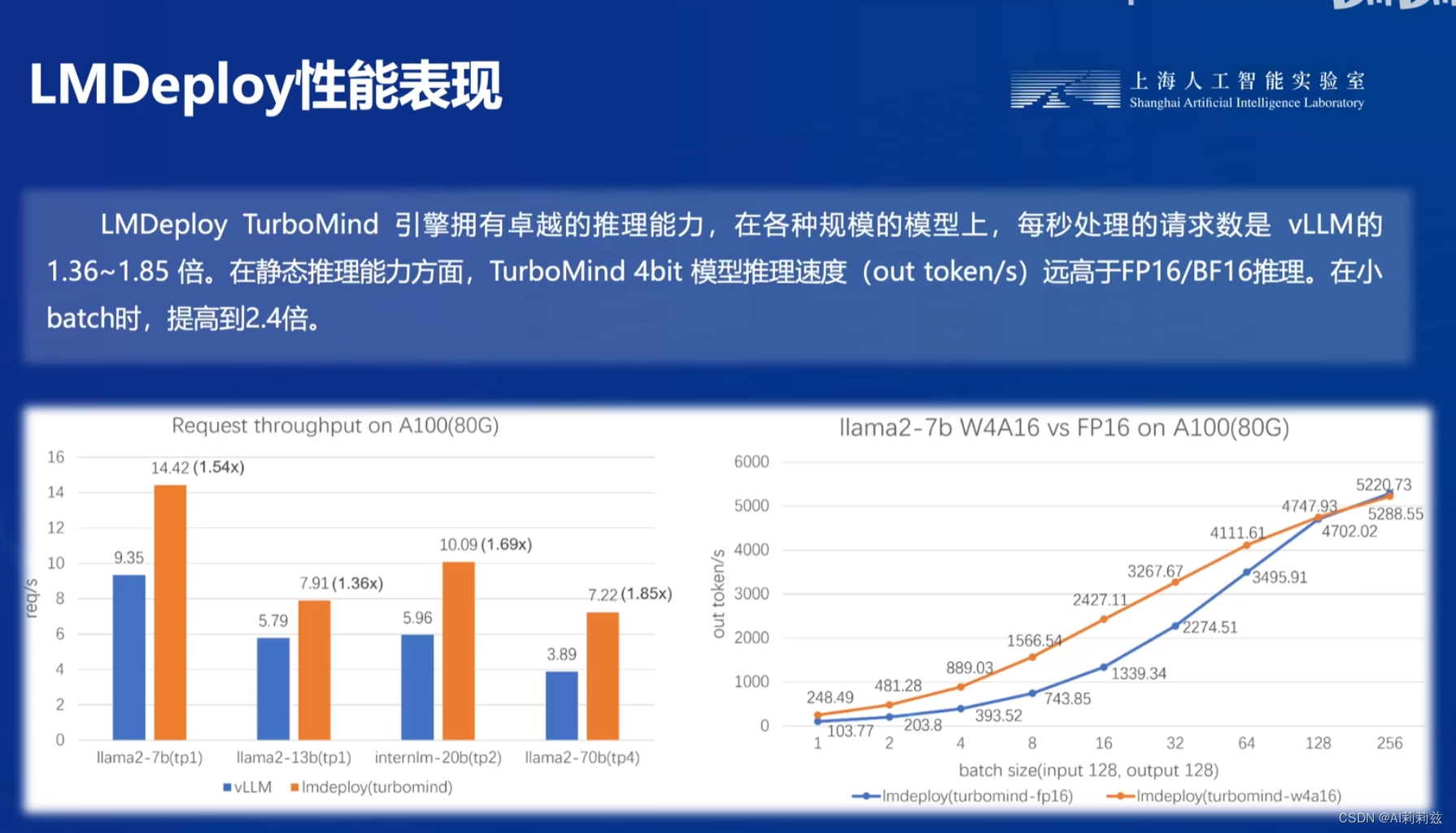
这么强的性能,这下不得不试了~
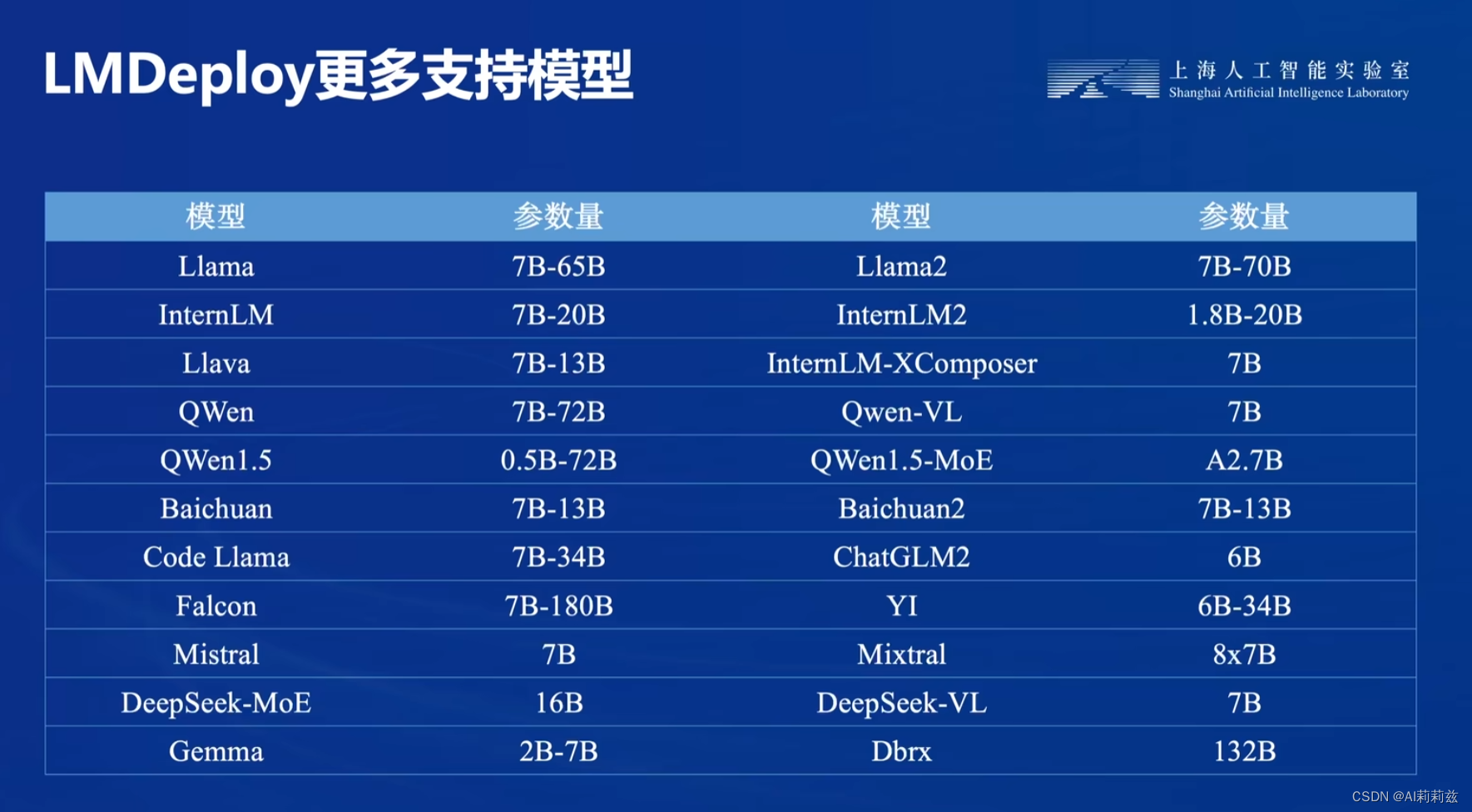
安装、部署、量化
还是尽量提前装好环境节省时间。
看看,卡在这也不动,不知道干啥呢。

推理延迟也有点不对劲,按说 A100 跑1.8B模型不可能这么慢,快赶上CPU了。难道是显存切分机制导致的吗?
另外……问英文你回答中文,你这模型严格来说训坏了啊……
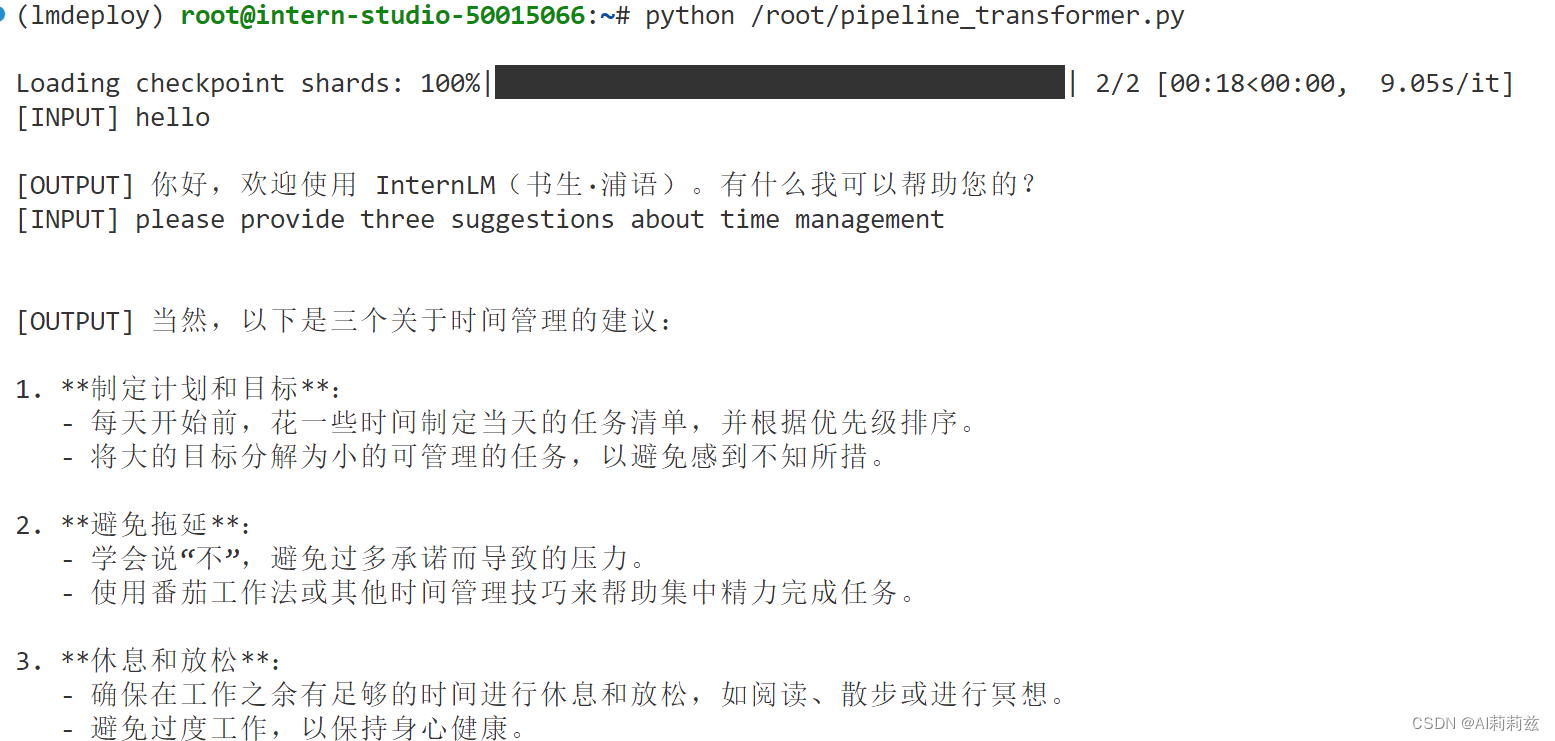
换成 LMDeploy 推理,哇 stream 模式下确实立杆见影,目测是3倍以上的提速:
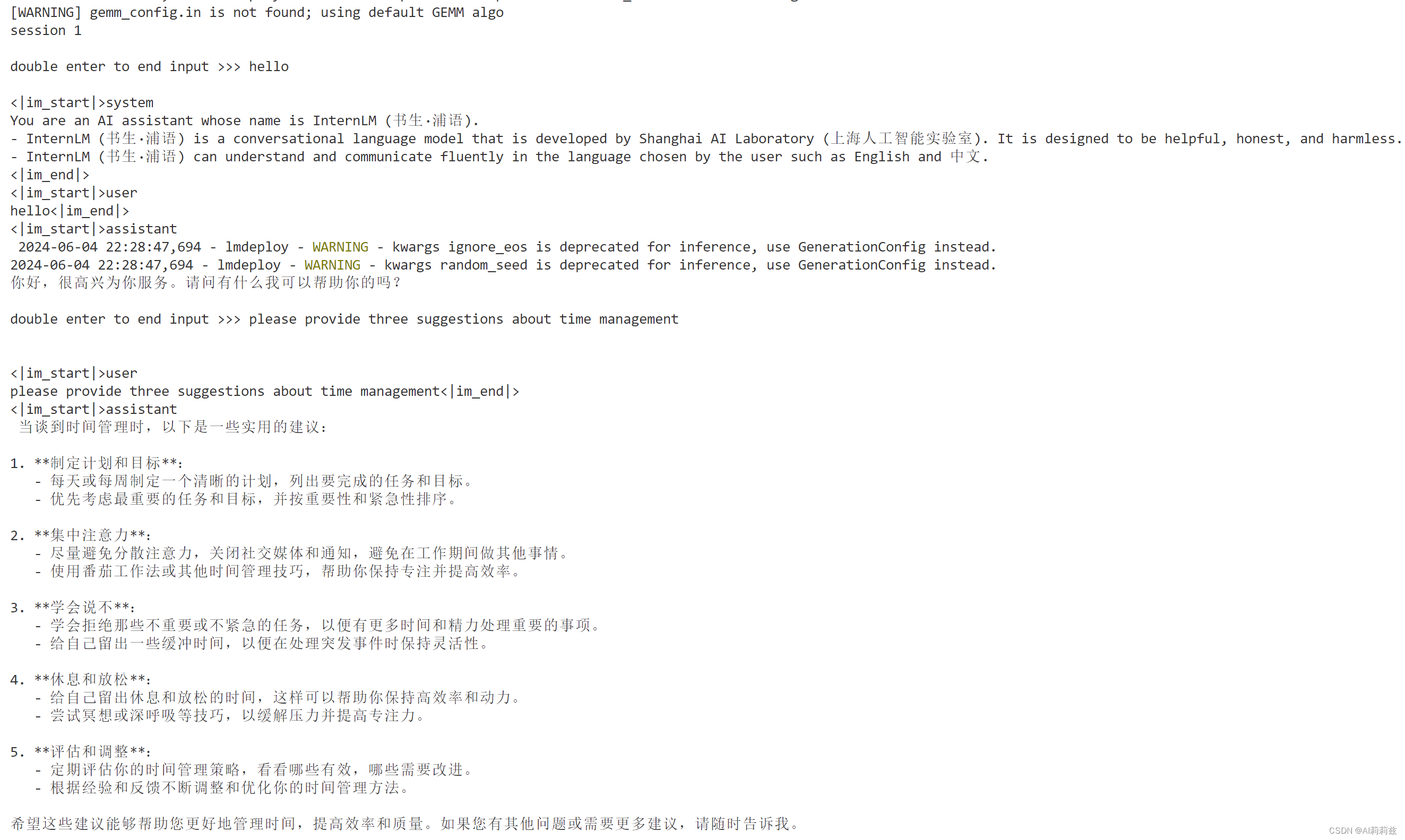
量化
默认比例 KV cache
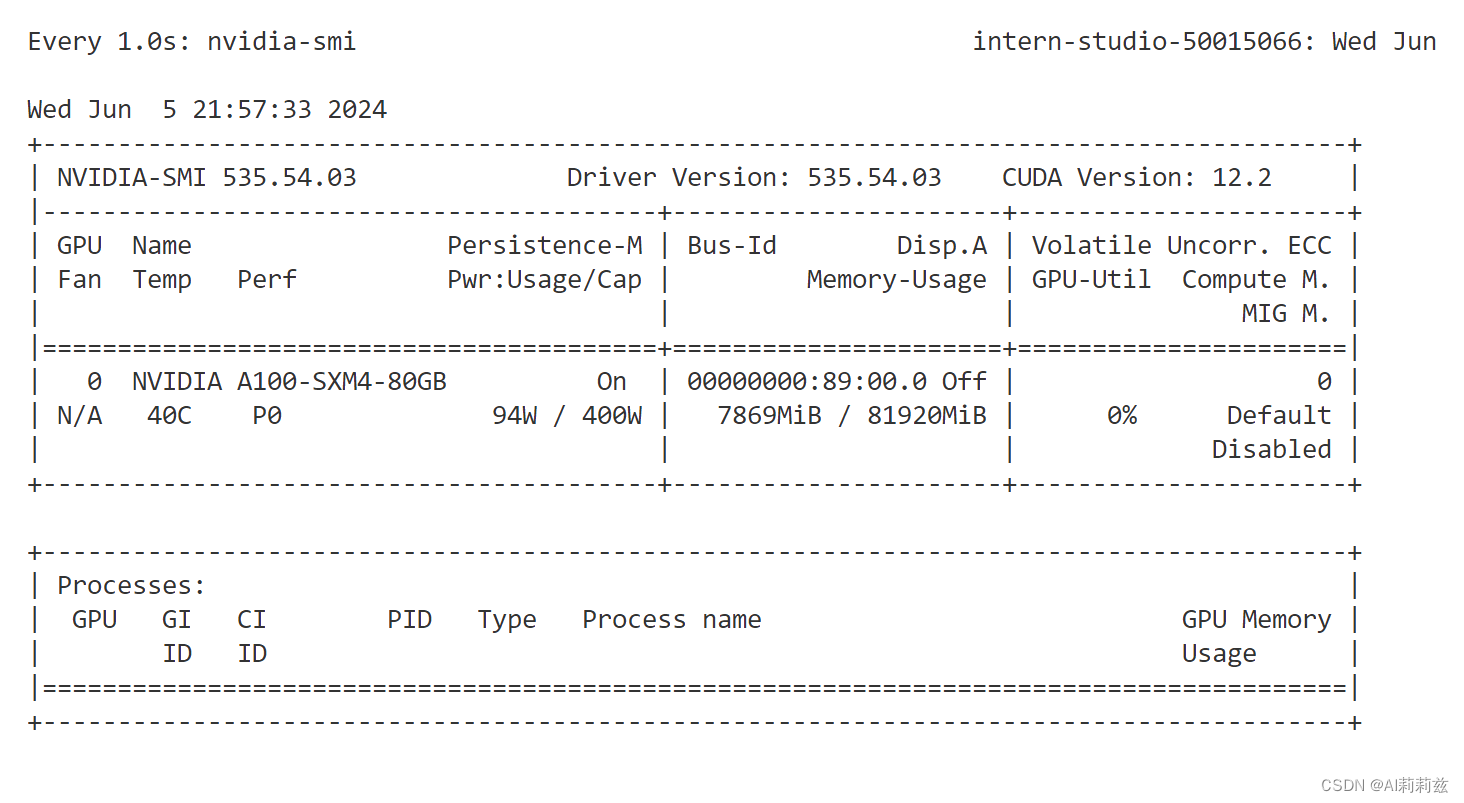
cache-max-entry-count=0.5

cache-max-entry-count=0.01
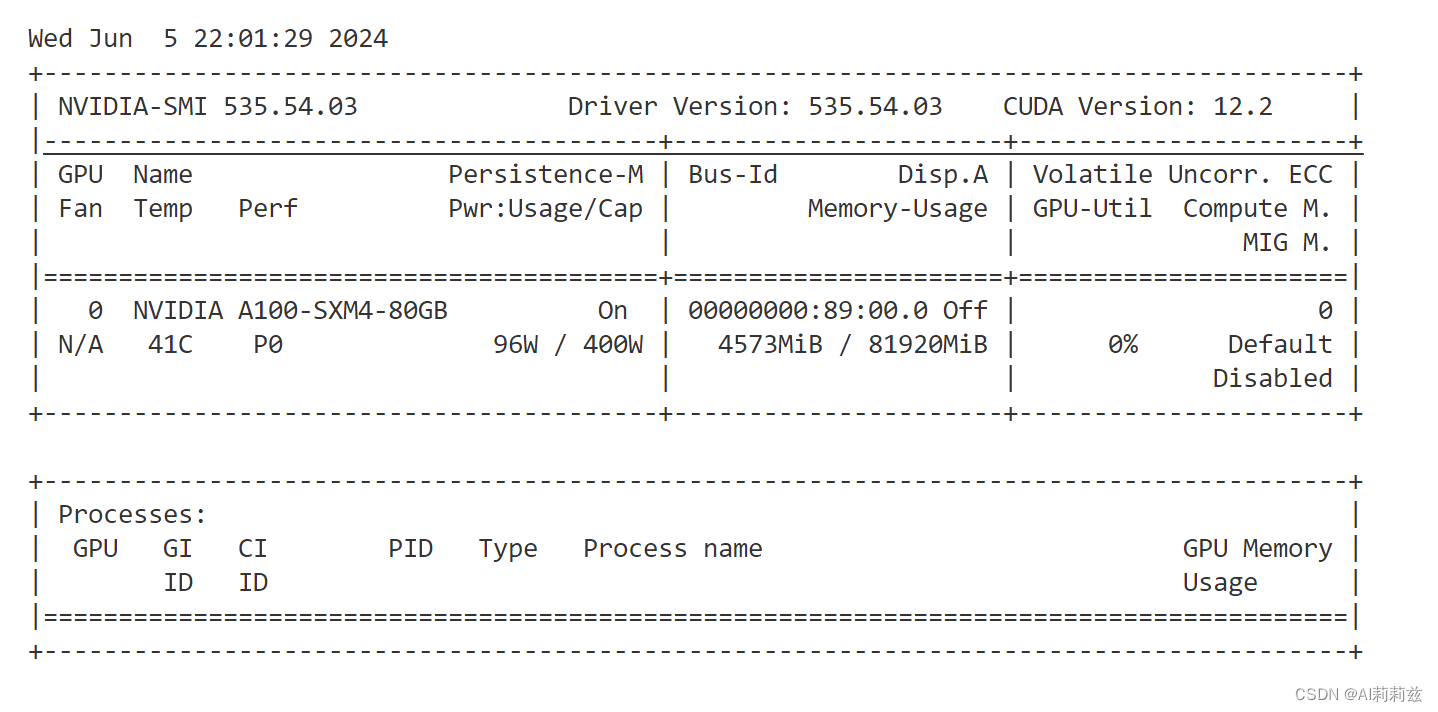
4bit 量化
KV cache 的调试结束,接下来该尝试 AWQ 量化了:
卧槽,祈祷这个较长别太折磨人……
之前没接触过低 bit 量化,也不知道 ptb 是啥数据集,就从代码里搜了一下,确认是指这个:
https://huggingface.co/datasets/ptb-text-only/ptb_text_only
特定年份的华尔街日报全集的数字版。
好奇不同的量化数据会不会影响量化后的效果……
(按理说应该会)

结束了,比我预想得居然快很多,看来就像之前说的,(至少我这台)开发机的IO有些问题。

确实贼快,百字秒出的感觉。但显存占用还是7.4G+
降低 kv cache 比例到最小:
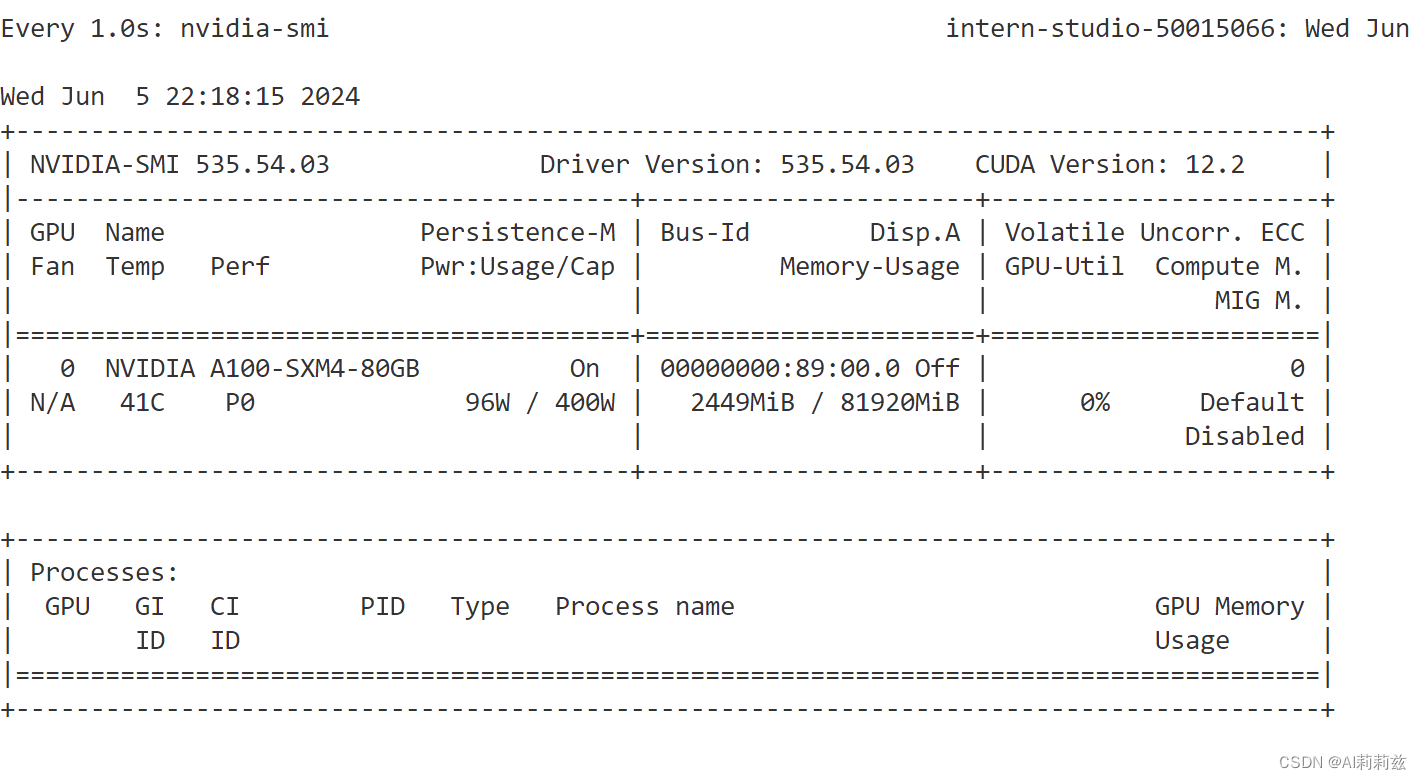
这下非常小了。
单个测试用例下,输出速度没有明显体感变化。

小模型都不太聪明的样子。讲笑话太难了。(Claude/ChatGPT 也没有很好)
Serve a model

好奇这三部分怎么合并成一块。
启动服务
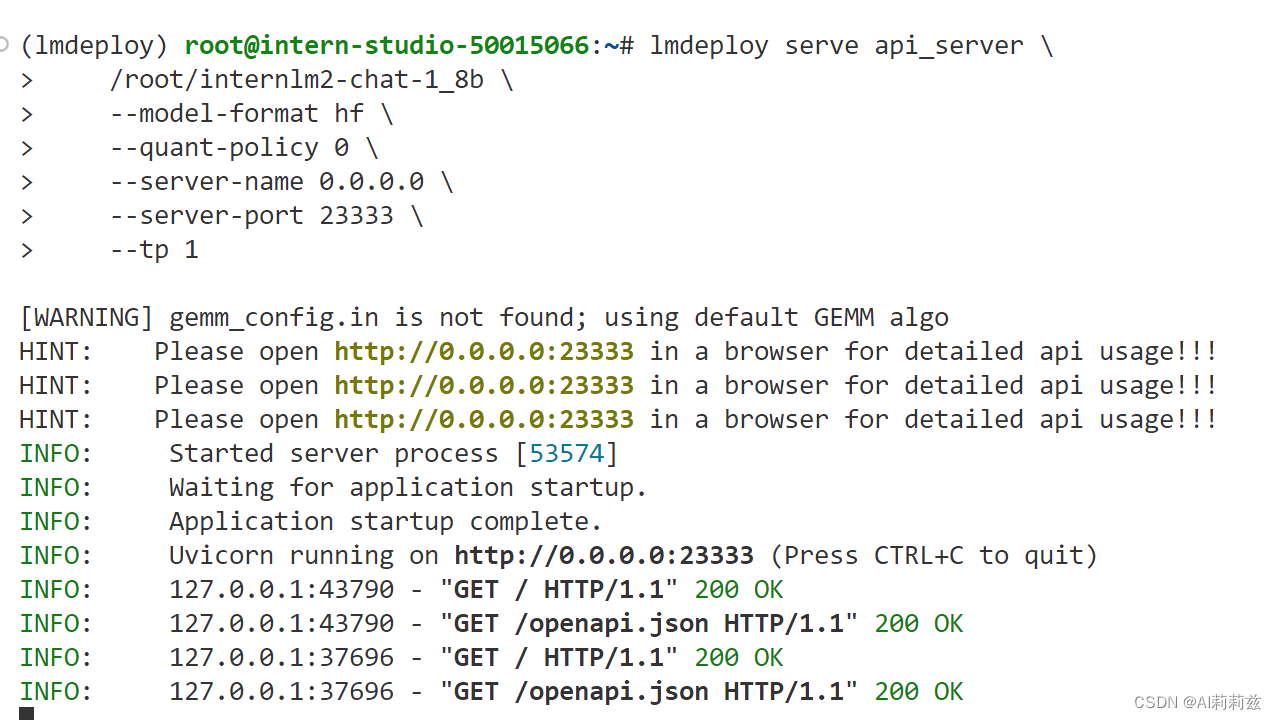
这个启动过程居然很快,

(VS Code 本地客户端远程模式下可以自动转发端口,课程中太省事了。推荐给各位同学使用。)
链接 API 服务器

网页客户端访问服务器 API


哇,太冷了,依然 get 不到这个“大模型”的笑点。
代码集成
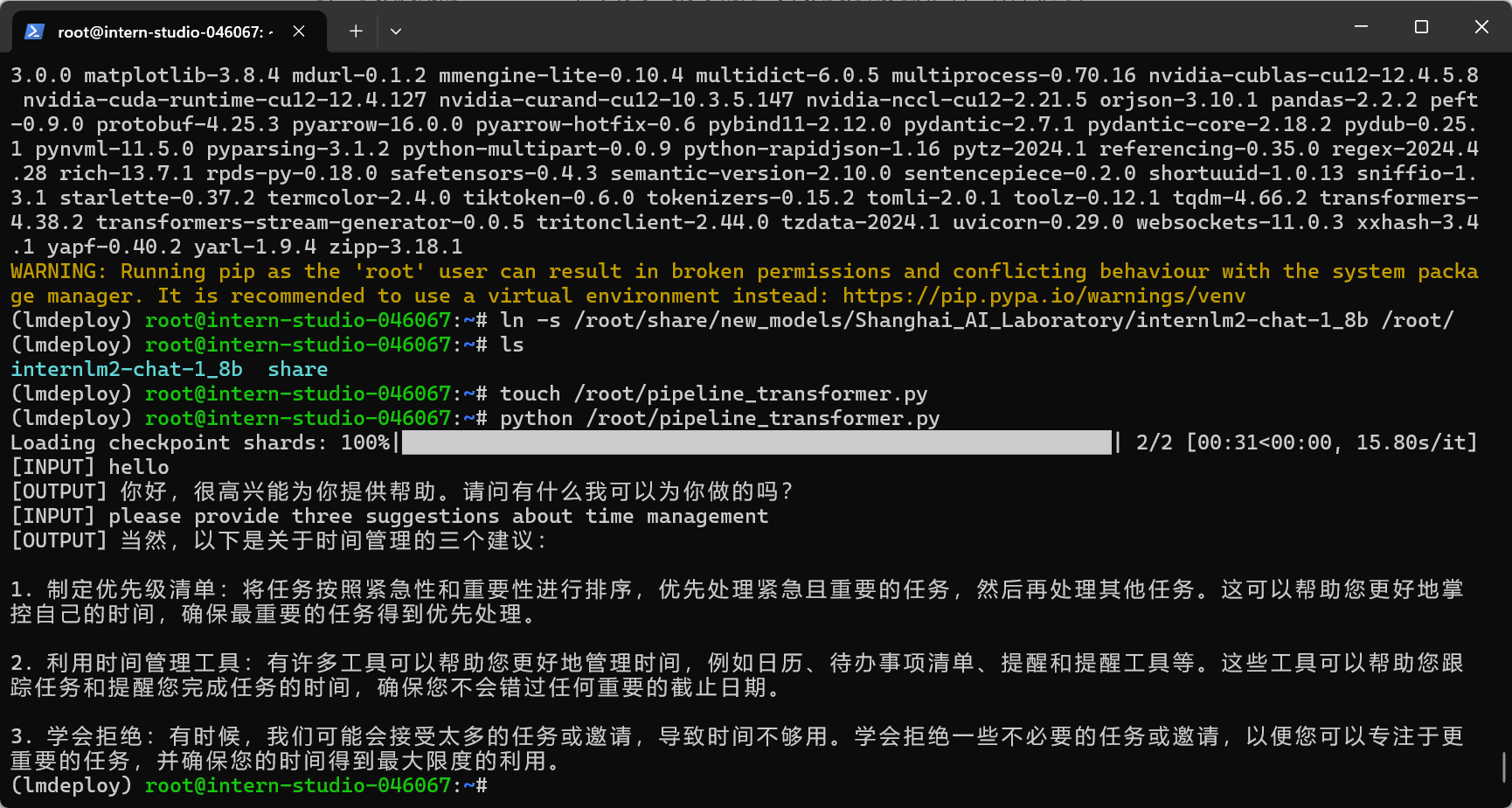
Python 代码运行 1.8B 模型
按照教程生成文件并执行,好像不太对:


第二遍对了,有点奇怪。随机性这会儿发挥作用了?
向 TurboMind 后端传递参数
啊,跑到这儿才想起来忘记截图显存占用了:

拓展
运行 llava
命令行模式:

网页模式:


咦……?随手找了张插画,也是用英文提问,但回答居然是中文,跟老师说的不太一样?(老师说这个模型对中文支持不太好)
换一张:
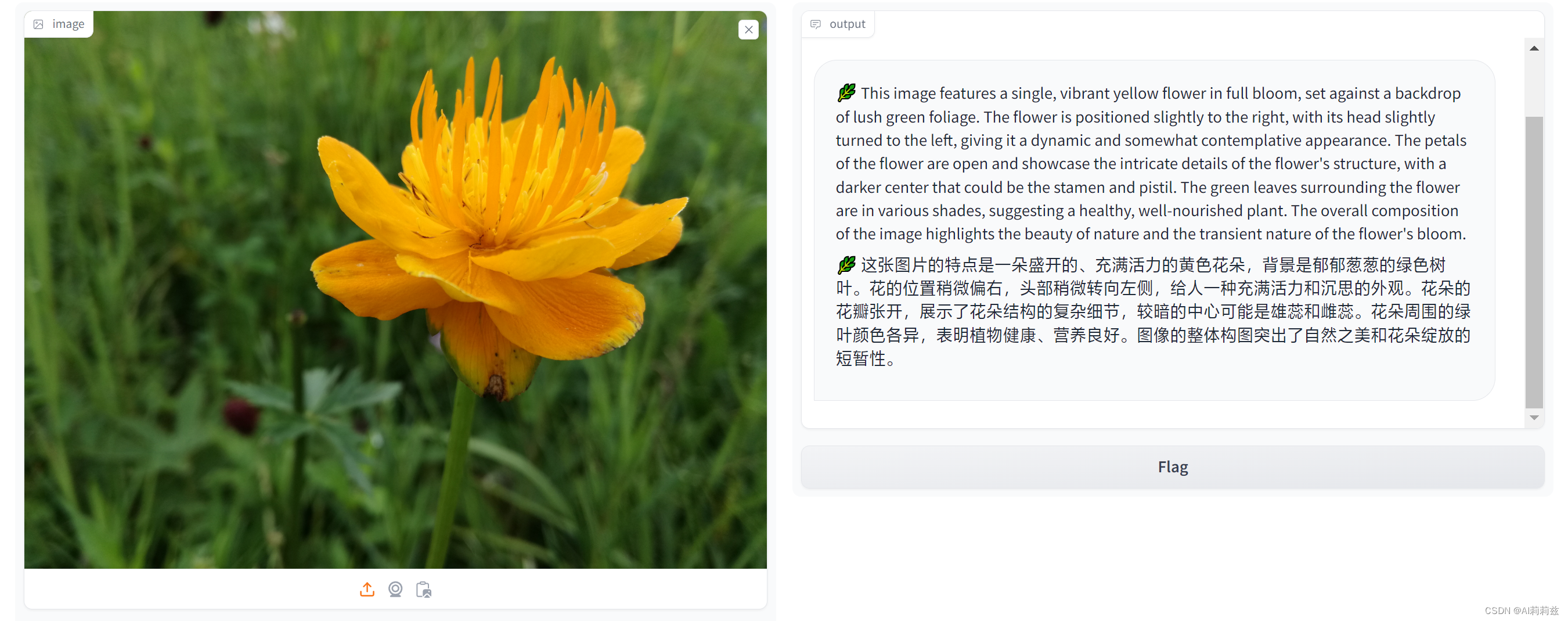
这回倒是对了。
速度比较

确实是六倍的差距!
作业
基础作业见上方,下面是优秀学员作业。因为不像之前需要额外做很多事情(主要瓶颈在开发机的IO上,太花时间了导致完全不想折腾)就顺手做了。
设置KV Cache最大占用比例为0.4,开启W4A16量化,以命令行方式与模型对话
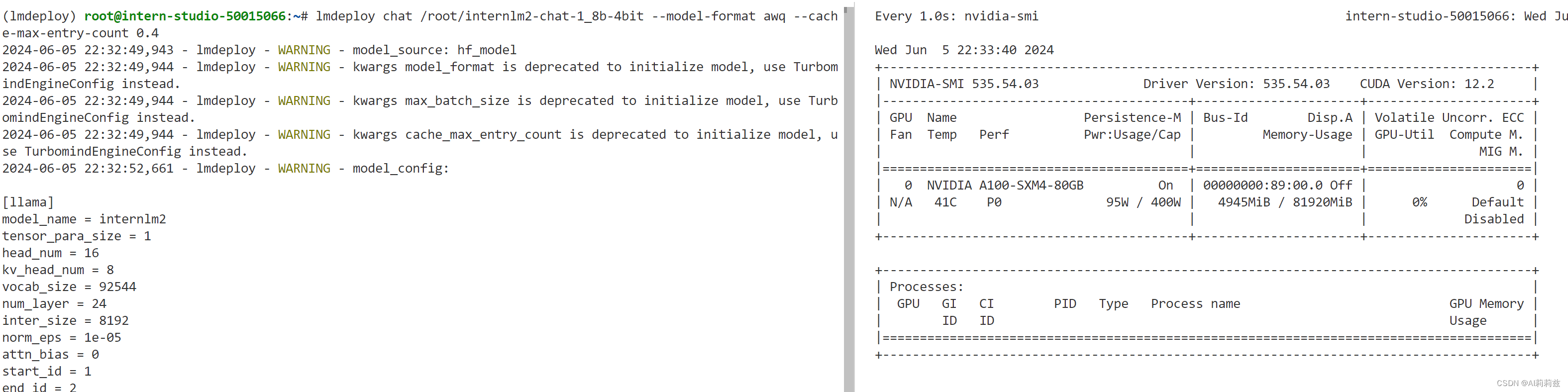

要不后面我自己微调个专门讲笑话的模型吧……
以API Server方式启动 lmdeploy,开启 W4A16量化,调整KV Cache的占用比例为0.4,分别使用命令行客户端与Gradio网页客户端与模型对话。
教程没直接写这时候参数该怎么填,-h 也没提供有效信息。不过可以猜嘛,只要教程编写者和项目开发者没有太离谱,大概率是能直接跑的:
lmdeploy serve api_server /root/internlm2-chat-1_8b-4bit/ --model-format awq --quant-policy 0 --server-name 0.0.0.0 --server-port 23333 --tp 1 --cache-max-entry-count 0.4
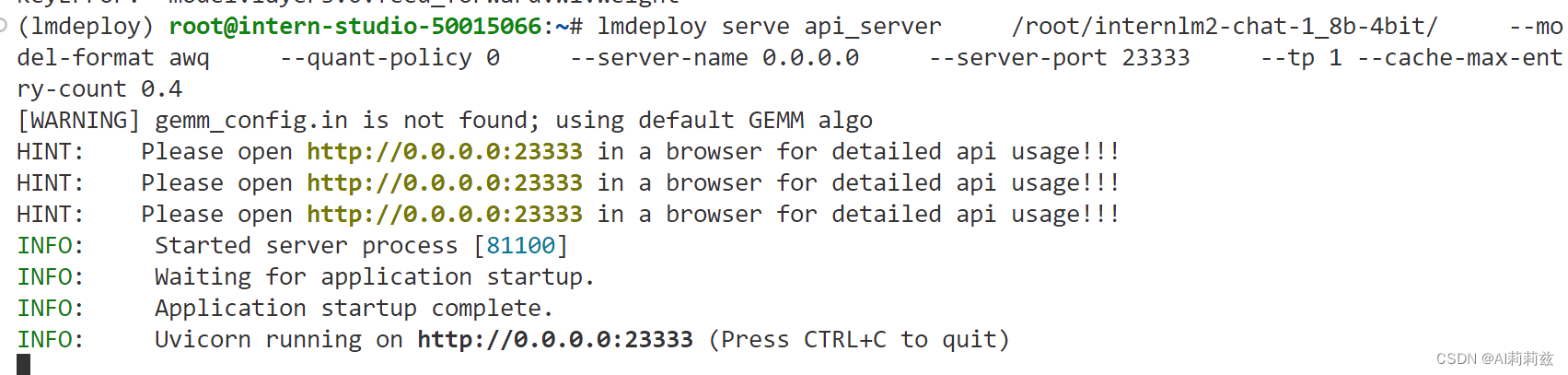
命令行

忽然觉得挺奇怪的。按说语料里不应该没有笑话,但为啥似乎所有的(出于严谨随手找了三个 chat 网页端测试)大模型都在这方面表现很烂呢?


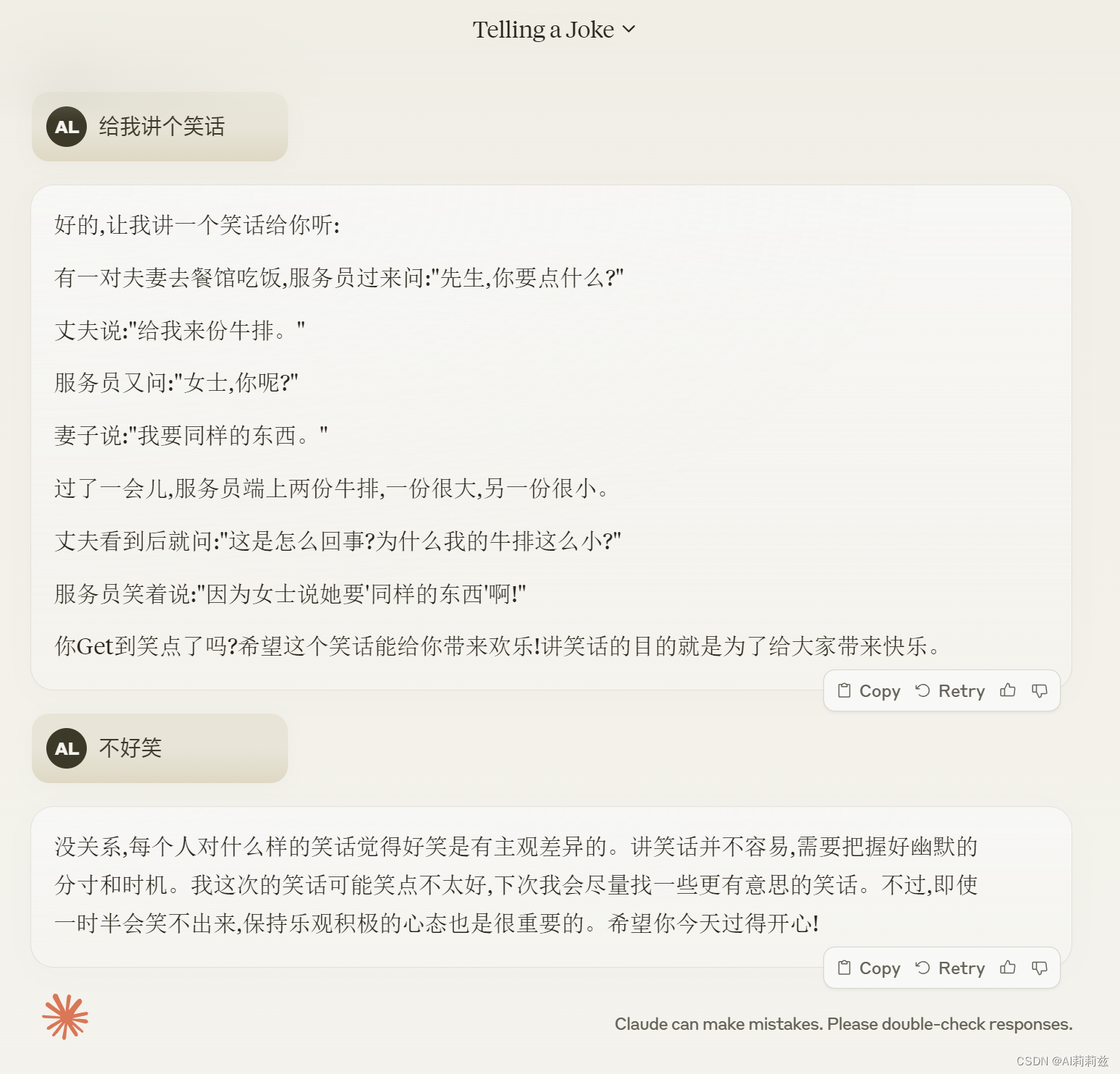
确实没记错……
网页对话

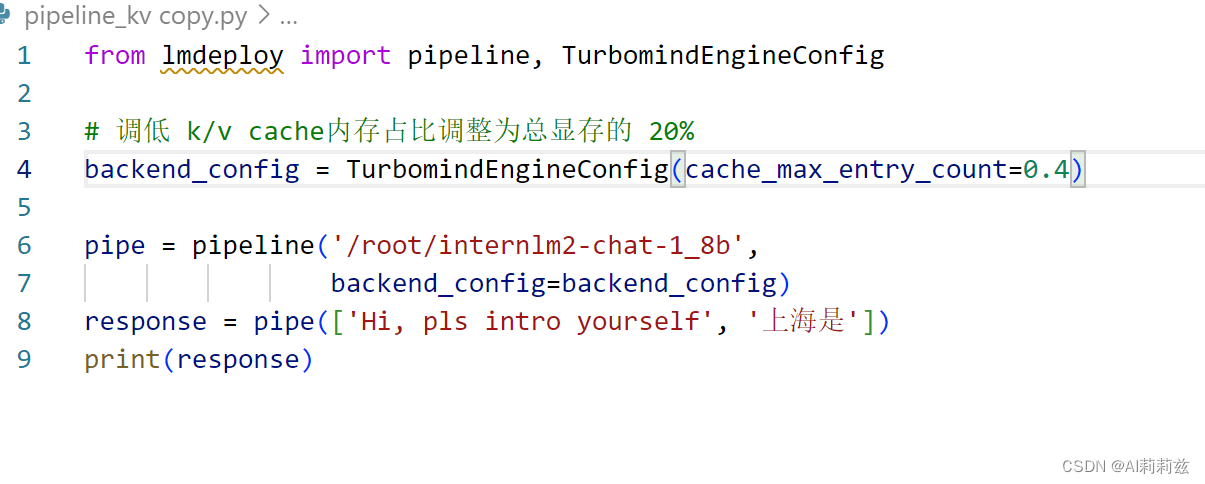
使用W4A16量化,调整KV Cache的占用比例为0.4,使用Python代码集成的方式运行internlm2-chat-1.8b模型。

使用 LMDeploy 运行视觉多模态大模型 llava gradio demo
(见拓展部分截图)

![[<span style='color:red;'>InternLM</span>训练<span style='color:red;'>营</span><span style='color:red;'>第二</span><span style='color:red;'>期</span><span style='color:red;'>笔记</span>]5. <span style='color:red;'>LMDeploy</span> <span style='color:red;'>量化</span><span style='color:red;'>部署</span> <span style='color:red;'>LLM</span> <span style='color:red;'>实践</span>](https://img-blog.csdnimg.cn/direct/1e17ac1ca10c4fb69f2fcda944558916.png)