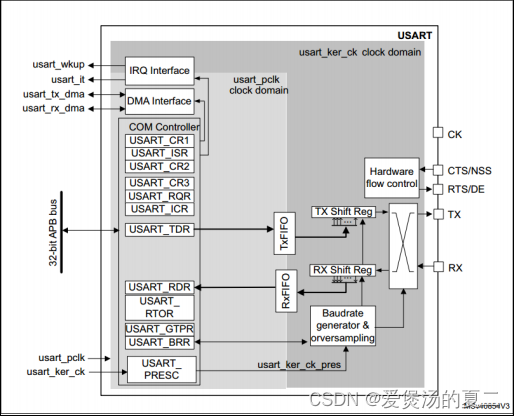
一、微调的原因
大模型微调(Fine-tuning)的原因主要有以下几点:
- 适应特定任务:预训练的大模型往往是在大量通用数据上训练的,虽然具有强大的表示学习能力,但可能并不直接适用于特定的下游任务。通过微调,可以使模型针对特定任务的数据分布进行调整,从而提高在该任务上的性能。
- 利用预训练知识:预训练的大模型已经学习到了大量的通用知识,这些知识对于很多任务来说都是有益的。通过微调,可以保留这些预训练的知识,并在此基础上进行特定任务的调整,从而实现知识的迁移和复用。
- 减少训练时间和计算资源:从头开始训练一个大型模型需要大量的时间和计算资源。而微调一个预训练模型通常只需要较少的数据和计算资源,就可以达到较好的性能。这大大降低了应用深度学习技术的门槛和成本。
- 提高模型性能:通过微调,可以优化模型在特定任务上的性能。微调过程中,模型会根据特定任务的数据进行参数调整,使其更好地适应任务需求,从而提高性能。
- 解决过拟合问题:在某些情况下,直接应用预训练模型到特定任务可能会导致过拟合问题。通过微调,可以对模型进行正则化,减少过拟合的风险,提高模型的泛化能力。
综上所述,大模型微调是一种有效的方法,可以使模型更好地适应特定任务,提高性能,并降低训练成本和时间。
二、两种微调范式
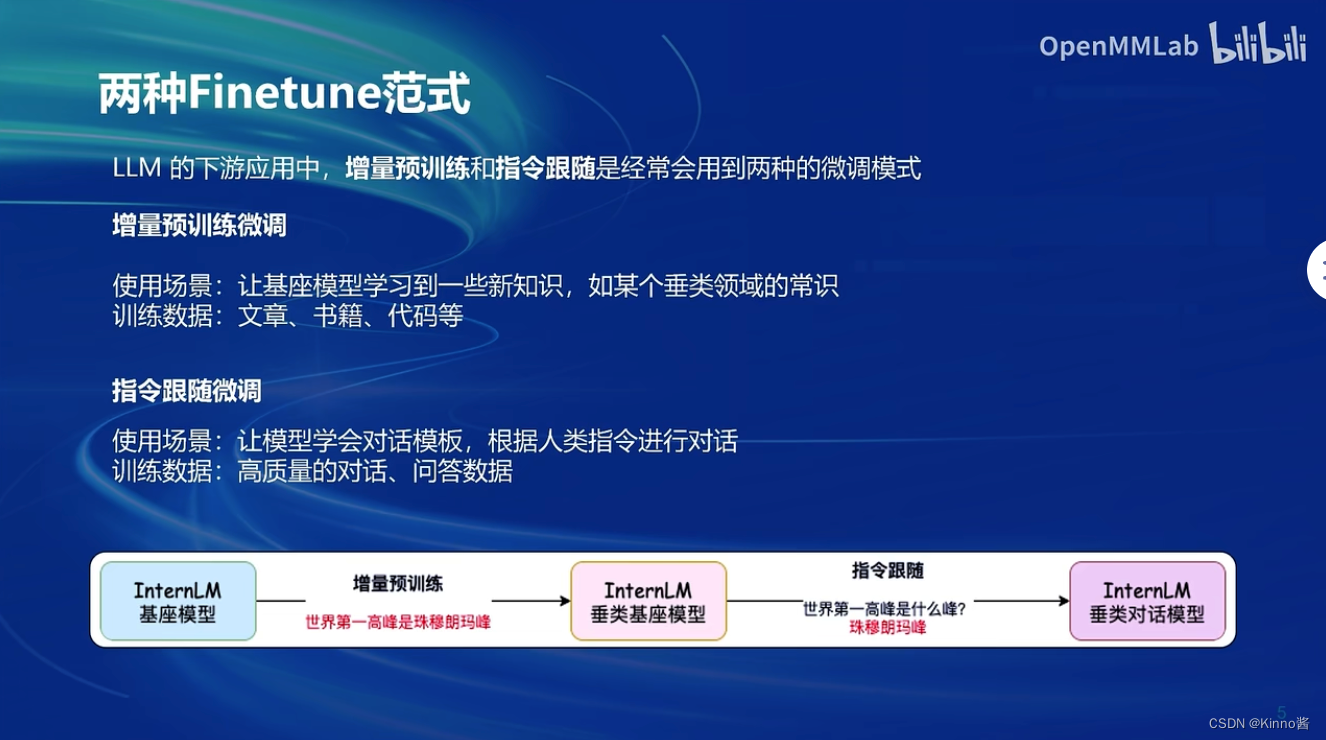
两种微调范式主要包括增量预训练微调和指令跟随微调。这两种范式在LLM(大型语言模型)的下游应用中经常被用到,各有其独特的使用场景和所需训练数据。
增量预训练微调
- 使用场景:该范式主要用于让基座模型学习到一些新知识,这些知识可能是某个特定垂类领域内的常识或专业知识。通过这种方式,模型能够在原有基础上进行扩展,增强其对特定领域的理解和处理能力。
- 训练数据:增量预训练微调通常需要大量的文章、书籍、代码等作为训练数据。这些数据能够提供丰富的领域知识和上下文信息,帮助模型更好地理解和吸收新知识。
指令跟随微调
- 使用场景:这种微调模式主要用于让模型学会对话模板,并能够根据人类的指令进行对话。通过这种方式,模型能够更好地理解人类的意图和需求,从而提供更为准确和有用的回应。
- 训练数据:指令跟随微调通常需要高质量的对话、问答数据作为训练素材。这些数据能够提供丰富的对话场景和指令类型,帮助模型学会如何根据不同的指令进行回应。
这两种微调范式各有其优势和适用场景。增量预训练微调更适合于那些需要模型具备特定领域知识的应用,而指令跟随微调则更适用于那些需要模型与人类进行自然交互的场景。在实际应用中,可以根据具体需求选择合适的微调范式,以达到最佳的模型性能和应用效果。

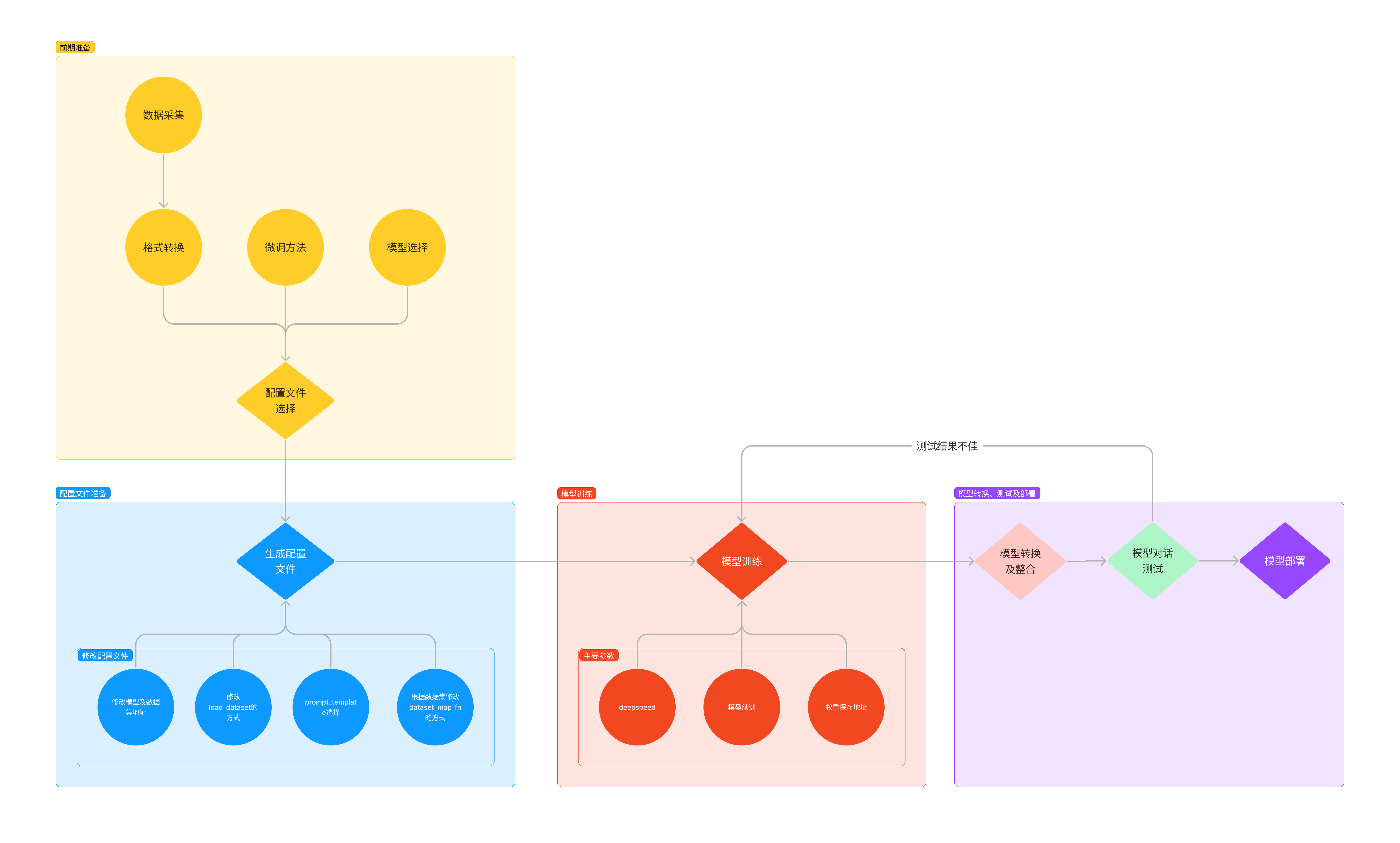
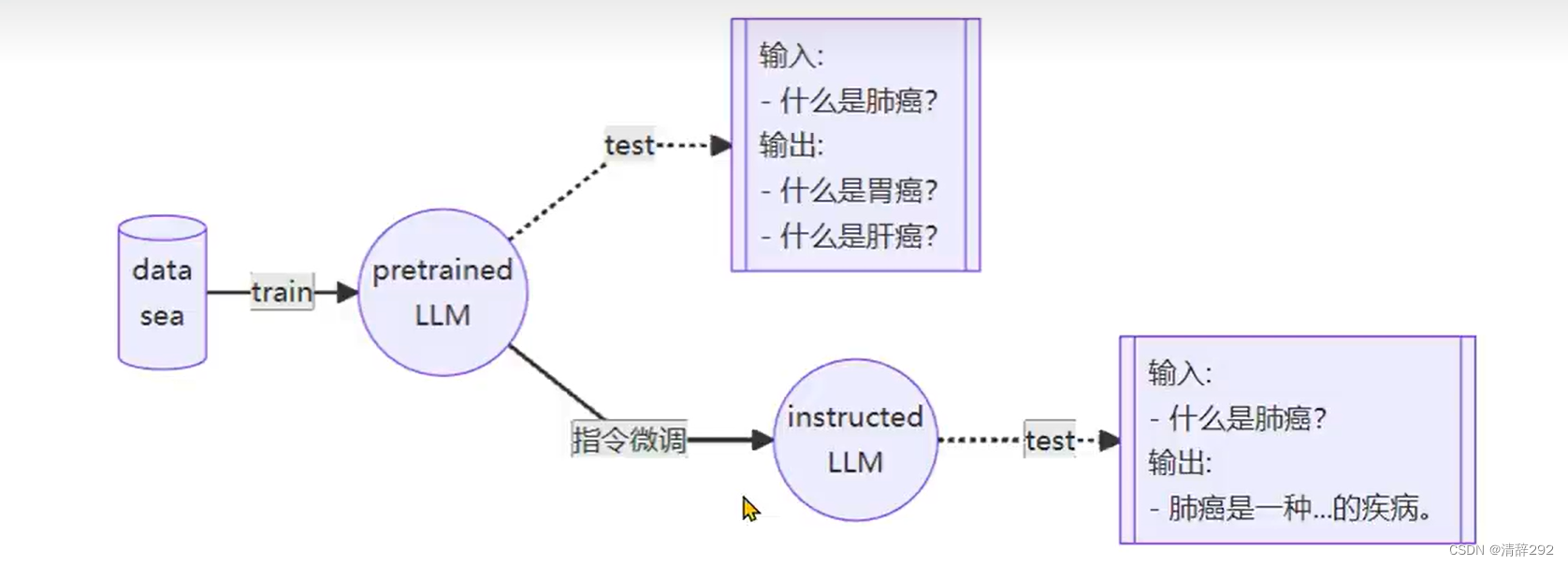 三、一条数据的一生
三、一条数据的一生
原始数据以标准格式进入系统,这些数据可能包括各种形式的信息,如文本、图像等。在Llama 2部分,用户输入数据,系统根据这些数据生成报告,并与用户进行互动。在这个过程中,系统还会对数据添加对话模板和标签,以便更好地理解和处理用户的请求。
接下来,在InternLM部分,数据会经历系统上下载、系统下打包和Llama 2训练等步骤。系统下载和上传数据,进行数据打包处理,然后利用这些数据对Llama 2进行训练,提升模型的性能和准确性。
最后,通过InternLM生成阶段,系统会根据用户的指令和对话模板,生成包含对话模板的助理回复。这个回复不仅回答了用户的问题,还遵循了特定的对话格式和规则,使得整个交互过程更加自然和流畅。
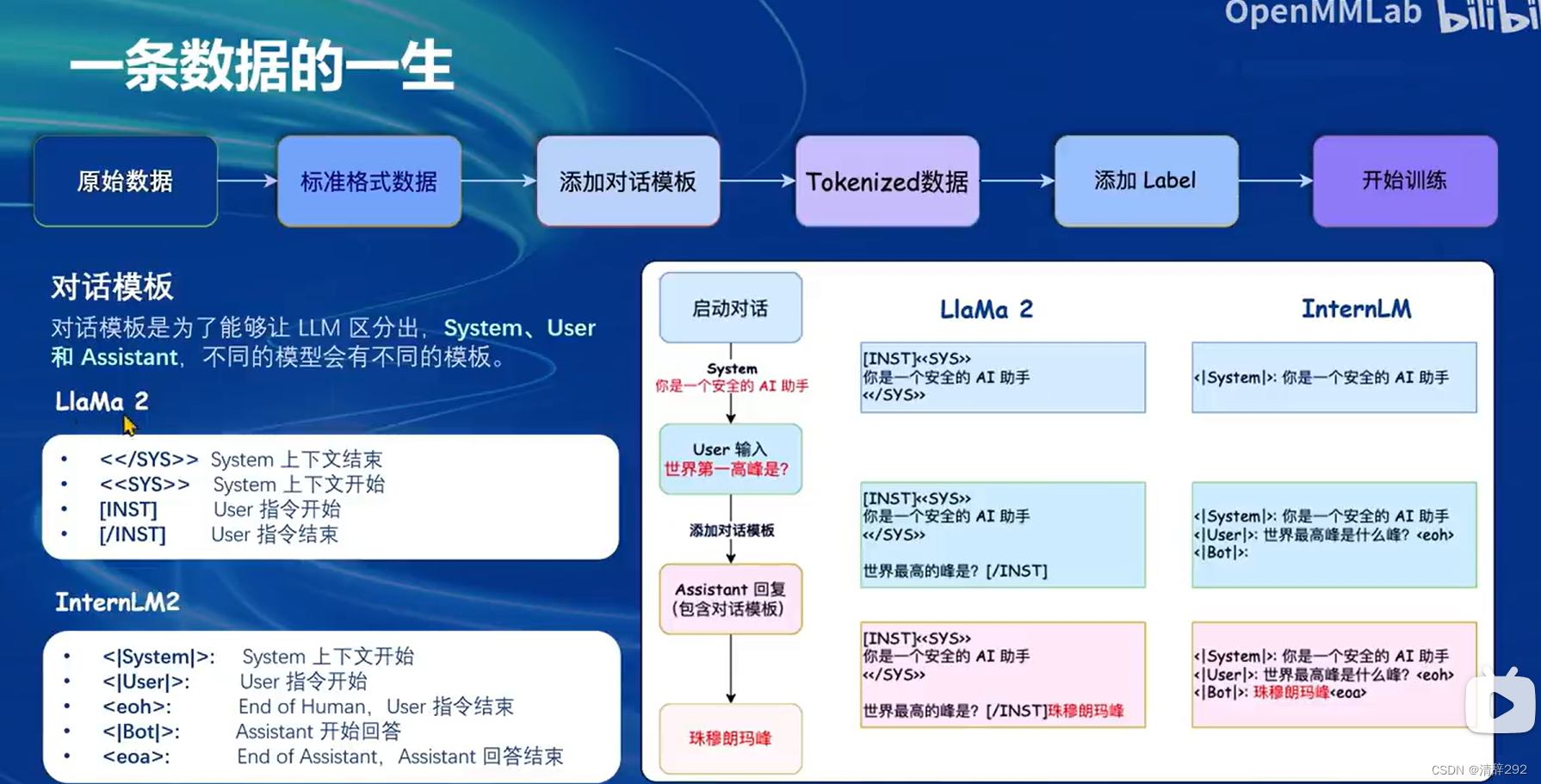 四、LoRA & QLoRA
四、LoRA & QLoRA
LoRA和QLoRA为我们提供了一种高效且灵活的方式来优化大型语言模型的性能,而无需对整个模型进行全面的改动。它们通过引入低秩适应和量化技术,成功降低了模型微调的显存消耗,为模型的部署和应用提供了更大的便利性和可能性。
LoRA主要是通过添加一个小型的线性层(支路)到原有的大型线性层旁边,来降低模型微调的显存消耗。这个新增的支路通常被称为Adapter,其参数量远小于原有的线性层,因此能够显著减少训练时所需的显存。通过这种方法,LoRA允许我们在不改变原有模型结构的情况下,对其进行有效的微调,以适应不同的任务或数据集。
而QLoRA是LoRA的一种改进版本,它引入了量化技术来进一步压缩Adapter的参数量。这种量化方法可以将Adapter的权重表示为低精度的数值,从而进一步减少显存消耗。即使只有有限的计算资源,QLoRA也能帮助我们有效地改造和优化大型语言模型。

五、XTuner简介
XTuner是一款功能强大的软件,其设计旨在提供灵活且高效的微调策略与算法,以满足各类场景下的应用需求。其主要功能亮点体现在多个方面:
首先,XTuner支持多种微调算法,无论是InternLM、Llama、Gemma,还是Mistral等,都能找到相应的优化策略。这种多样化的算法支持使得XTuner可以覆盖更广泛的场景,从而为用户提供更多的选择。
其次,XTuner能够适配多种开源生态,如HuggingFace和ModelScope等。这意味着用户可以轻松加载各种模型或数据集,进行快速的微调操作,提高工作效率。
此外,XTuner在任务类型、数据格式以及训练引擎等方面也提供了丰富的支持。无论是Alpaca、QLoRA微调,还是增量预训练等任务,XTuner都能提供相应的优化加速方案。
在硬件适配方面,XTuner展现出了出色的兼容性。它支持从消费级显卡到数据中心级显卡的广泛选择,包括但不限于NVIDIA的20系、30系、40系显卡,以及A10、A100、H100等高端显卡。这使得用户可以根据自身的硬件条件,选择最适合的配置进行微调操作。
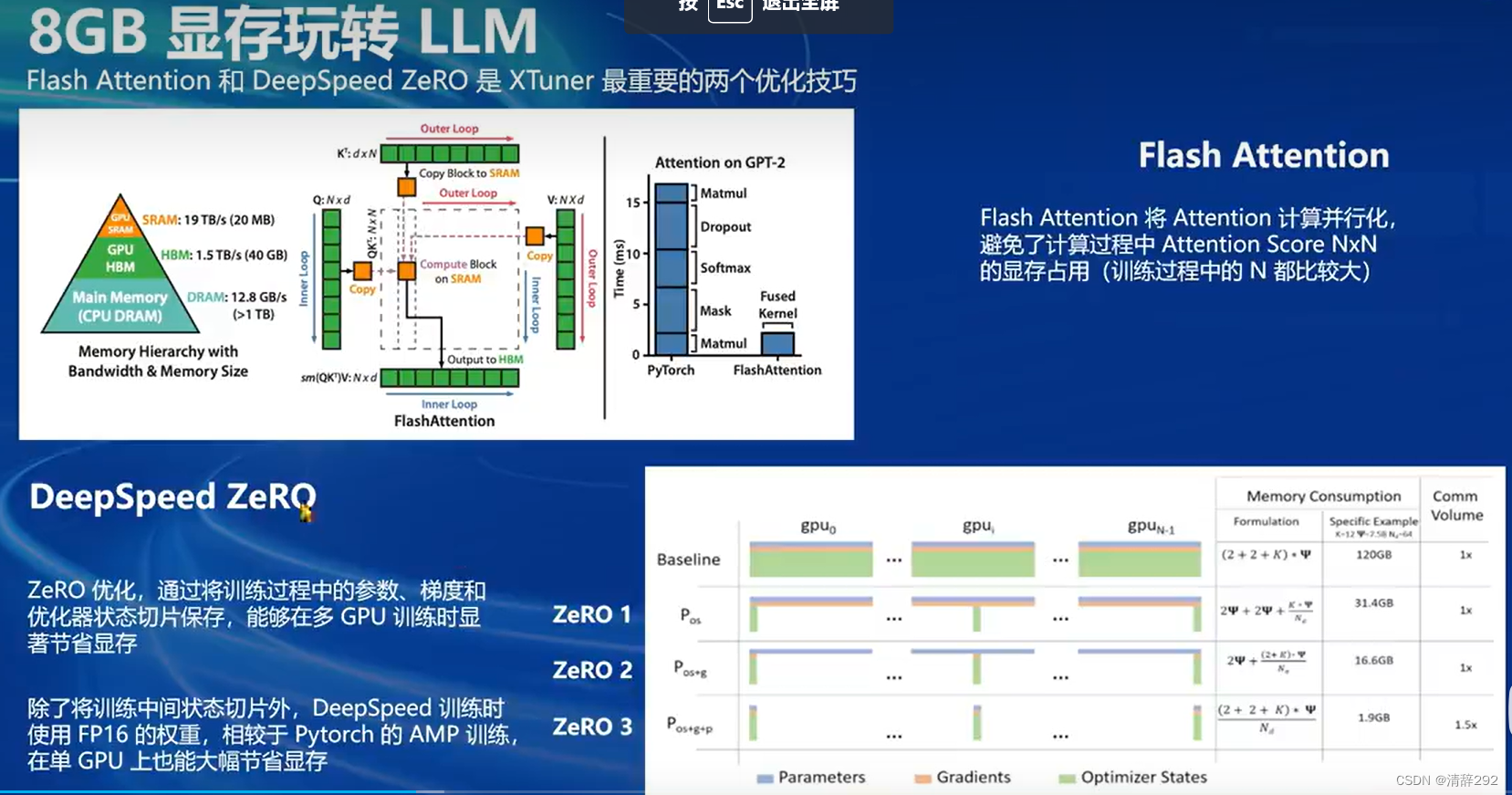
 六、8GB显存玩转LLM
六、8GB显存玩转LLM
DeepSpeed ZeRQ和FlashAttention都是XTuner框架中针对深度学习模型训练过程中的显存消耗和计算效率问题而设计的优化技巧。它们通过不同的方式,有效地提升了模型训练的性能和速度,使得在有限的硬件资源下,能够更有效地进行深度学习模型的训练和部署。
DeepSpeed ZeRQ是DeepSpeed框架中的一个分布式训练技术,它通过优化模型参数的共享和内存使用,提高了深度学习模型训练的效率和速度。具体来说,ZeRQ实现了零总和压缩算法,这种算法通过减少同步操作中传输的数据量来降低通信开销。此外,ZeRQ还提供了ZeRO-2(Zero Redundancy Optimizer-2)的内存优化技术,这种技术将大型模型参数分割成多个小块,每个小块独立存储于不同的设备上,从而减少了内存使用量。每个分块都可以被独立地更新和同步,进一步提高了训练速度和可扩展性。因此,使用DeepSpeed ZeRQ可以在保持模型性能的同时,显著降低训练时的显存消耗,从而使得更大规模、更复杂的模型训练成为可能。
而FlashAttention则主要关注于提高深度学习模型中Attention机制的计算效率。传统的Attention机制在计算过程中需要频繁地读写内存,这会导致显著的延迟。FlashAttention通过优化内存访问模式,减少了这种延迟。它利用高效的数据布局和访问模式,将Attention计算并行化,从而避免了计算过程中Attention Score NxN的显存占用。这种优化使得FlashAttention在处理大规模数据时,能够显著提高计算效率,加快训练速度。
 七、InternLM2 1.8B 模型
七、InternLM2 1.8B 模型
InternLM2 1.8B模型是一款高质量、高适应灵活性的基础模型,它是为了响应社区用户强烈的呼声而开发的,并已经正式开源。这款模型提供了三个不同版本供用户选择,满足不同需求。它能够为下游深度适应提供良好的起点,并且拥有较低的硬件门槛,使得初学者也能轻松进行大模型的全链路操作。此外,该模型还表现出优秀的指令跟随、聊天体验和函数调用能力,非常推荐在下游应用程序中使用。具体来说,在FP16精度模式下,InternLM2-1.8B仅需4GB显存的笔记本显卡即可顺畅运行,而拥有8GB显存的消费级显卡即可轻松进行模型的微调工作。
 八、多模态LLM
八、多模态LLM
1.多模态LLM简介
多模态LLM,即多模态大语言模型(Multimodal Large Language Model),是一种能够处理多种模态输入(如文本、图像、语音等)的语言模型。相比于传统的单模态语言模型,多模态LLM能够更好地理解和生成与多模态输入相关的自然语言。
多模态LLM通过模态对齐和多模态融合技术,能够实现对不同模态信息的有效整合和处理。这使得多模态LLM在智能客服、智能助手、文本生成和创作辅助、智能搜索和信息推荐、智能编程和代码生成等多个领域具有广泛的应用前景。
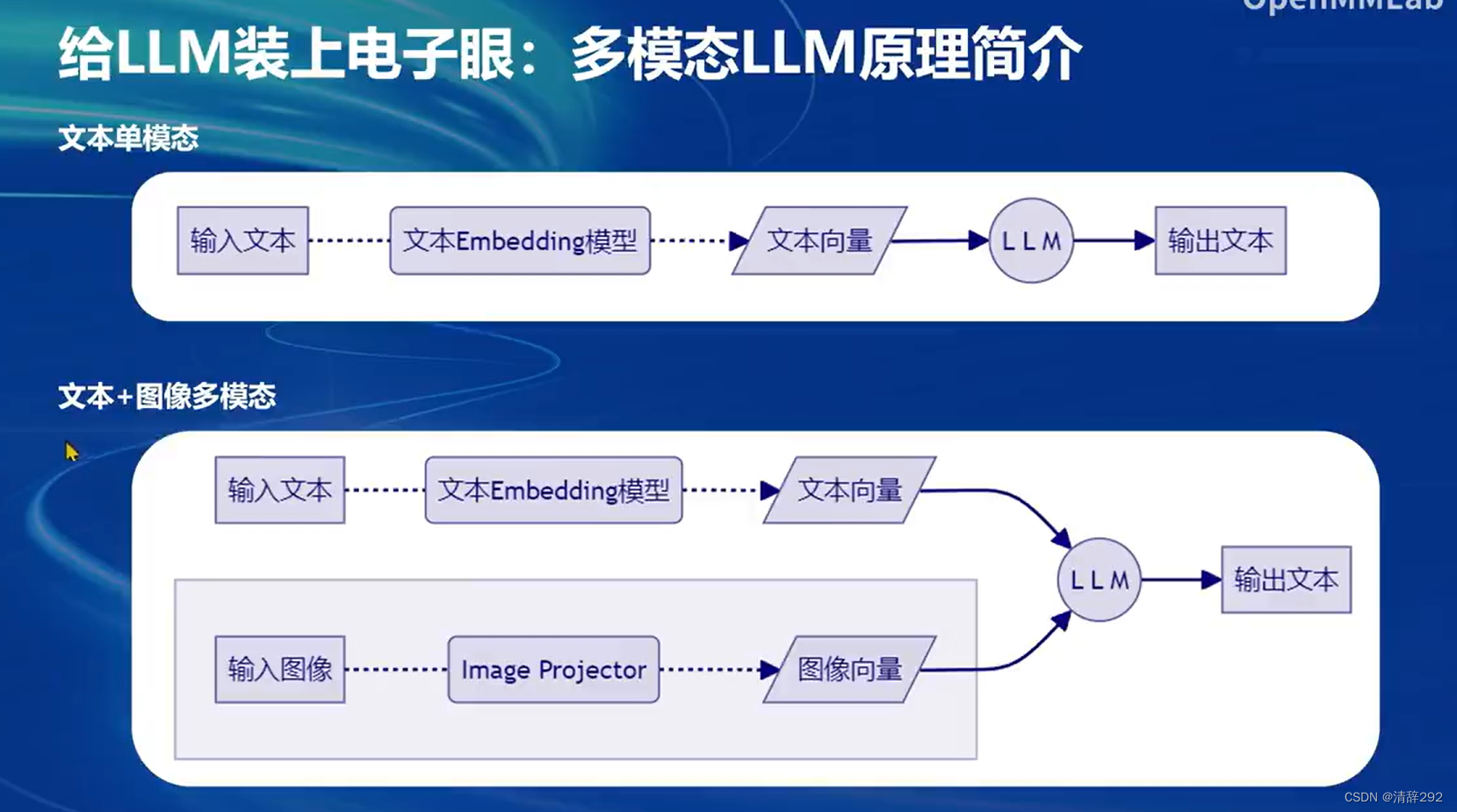
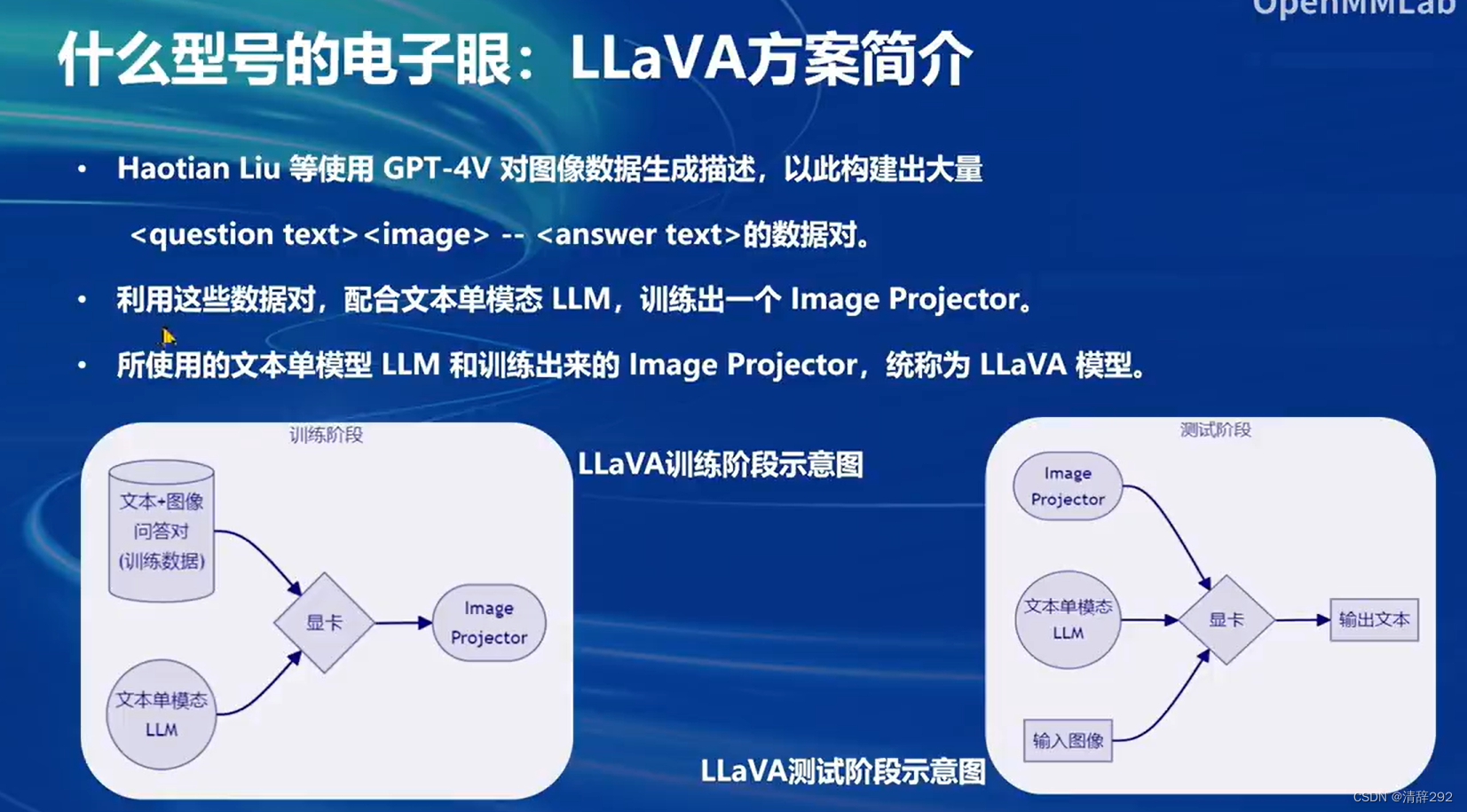
2.LLaVA方案简介
LLaVA方案是一种创新的文本与图像结合的处理方案。它主要利用了GPT-4V项目对图像数据进行描述生成,进而构建出大量包含问题文本、图像和答案文本的数据对。这些数据对为后续的模型训练提供了丰富的资源。
在训练阶段,LLaVA方案通过利用已有的文本单模态LLM(大语言模型)和训练出的ImageProjector(图像投影器),共同构建成一个完整的LLaVA模型。这个模型不仅能够处理文本数据,还能够处理图像数据,实现了文本与图像的多模态融合。
在LLaVA训练阶段示意图中,我们可以看到图像数据经过预处理后,被送入ImageProjector进行特征提取,然后与文本数据一起,通过文本单模态LLM进行处理。在这个过程中,模型学习到了如何将图像特征与文本信息进行有效的结合,从而提高了对图像的理解和生成文本的质量。
到了测试阶段,LLaVA模型可以接收新的图像输入,通过ImageProjector提取图像特征,并结合文本单模态LLM生成相应的文本输出。这种能力使得LLaVA模型在智能客服、图像描述生成、图像问答等多个领域具有广泛的应用前景。
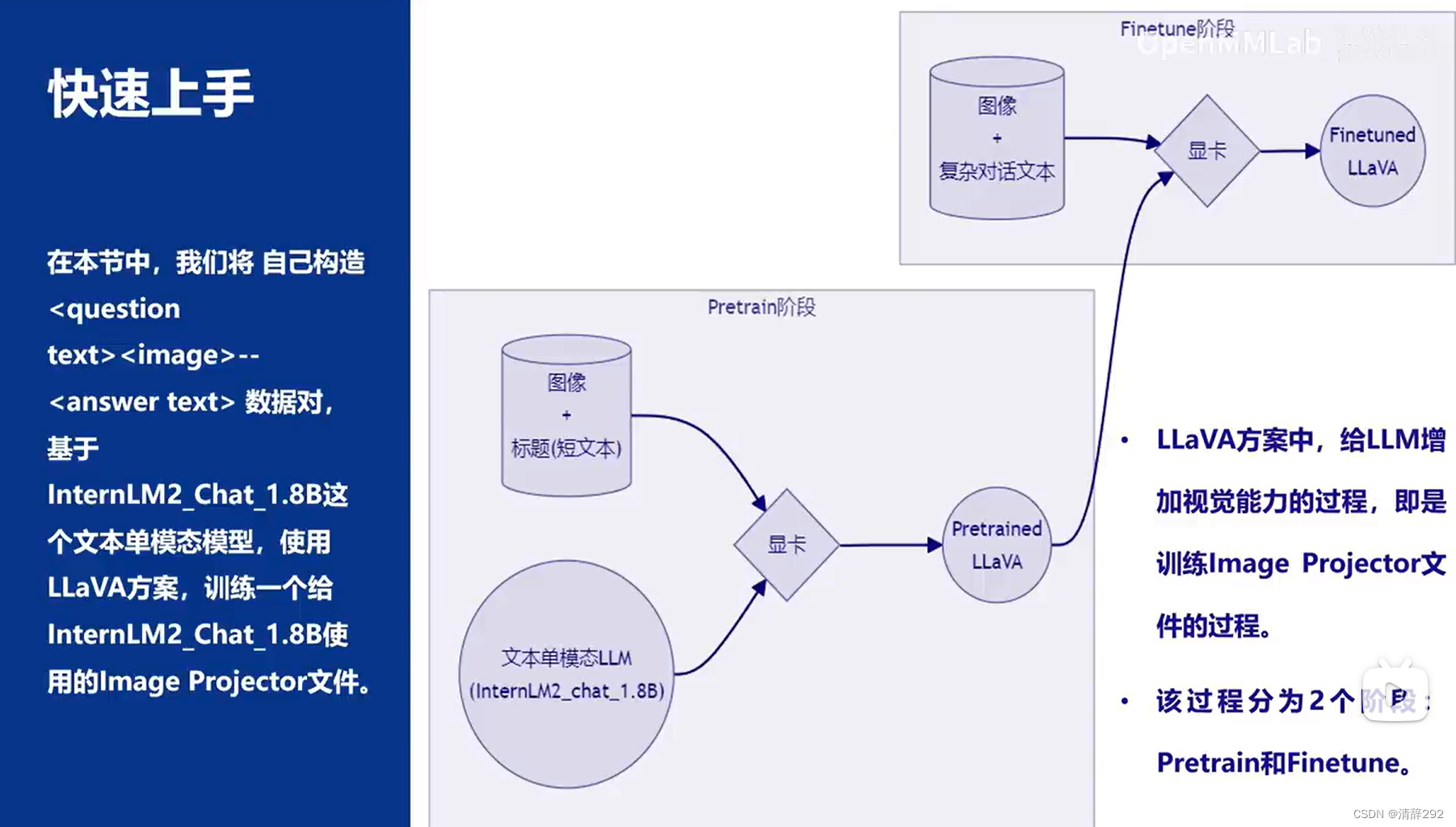
3.快速上手
在【InternLM 实战营第二期作业04】XTuner微调LLM:1.8B、多模态、Agent中会详细展示【InternLM 实战营第二期作业04】XTuner微调LLM:1.8B、多模态、Agent-CSDN博客:

![[<span style='color:red;'>InternLM</span>训练<span style='color:red;'>营</span><span style='color:red;'>第二</span><span style='color:red;'>期</span><span style='color:red;'>笔记</span>]4. <span style='color:red;'>XTuner</span> <span style='color:red;'>微调</span> <span style='color:red;'>LLM</span>:1.8<span style='color:red;'>B</span>、<span style='color:red;'>多</span><span style='color:red;'>模</span><span style='color:red;'>态</span>、<span style='color:red;'>Agent</span>](https://img-blog.csdnimg.cn/direct/57e34f733ca44480a76ca2d2a28ad5d8.png)






















![Amazon云计算AWS之[1]基础存储架构Dynamo](https://img-blog.csdnimg.cn/direct/b62a96e4c92b4f558f8421ee8f99b9ec.png#pic_center)







![OpenHarmony网络协议通信c-ares [交叉编译]异步解析器库](https://img-blog.csdnimg.cn/img_convert/b38c2df125567aa4947938efa77af821.gif)