模型部署
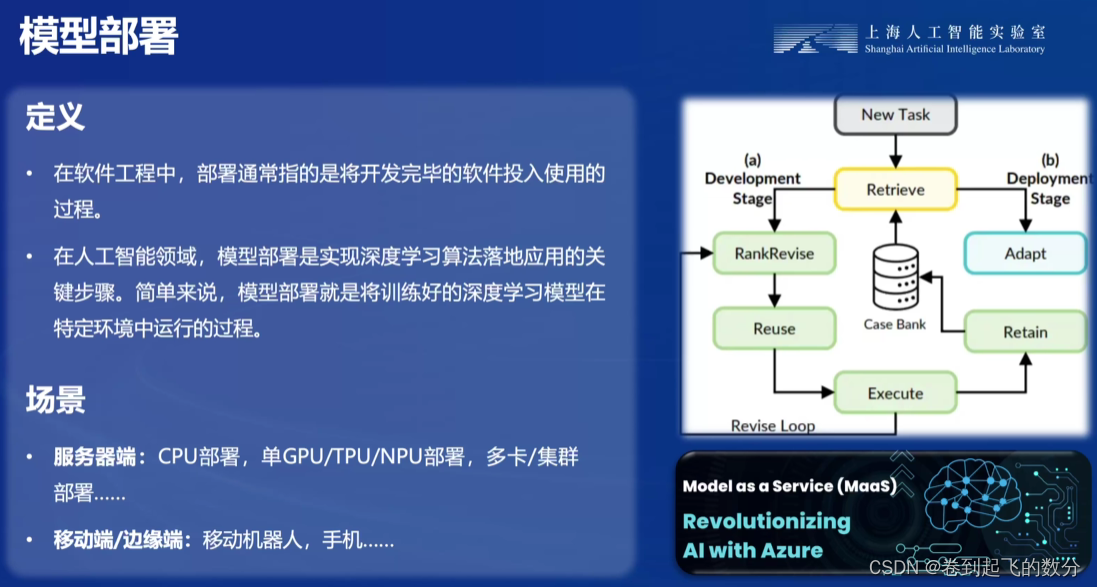
模型部署是指将训练好的机器学习或深度学习模型集成到实际应用中,使其能够对外提供服务的过程。这通常涉及将模型从训练环境中导出,并将其部署到生产环境,以便在实际应用中使用。模型部署是实现机器学习或深度学习价值的关键环节,只有将模型部署到实际应用中,才能发挥其作用,为企业或个人带来实际效益。

大模型部署面临的挑战
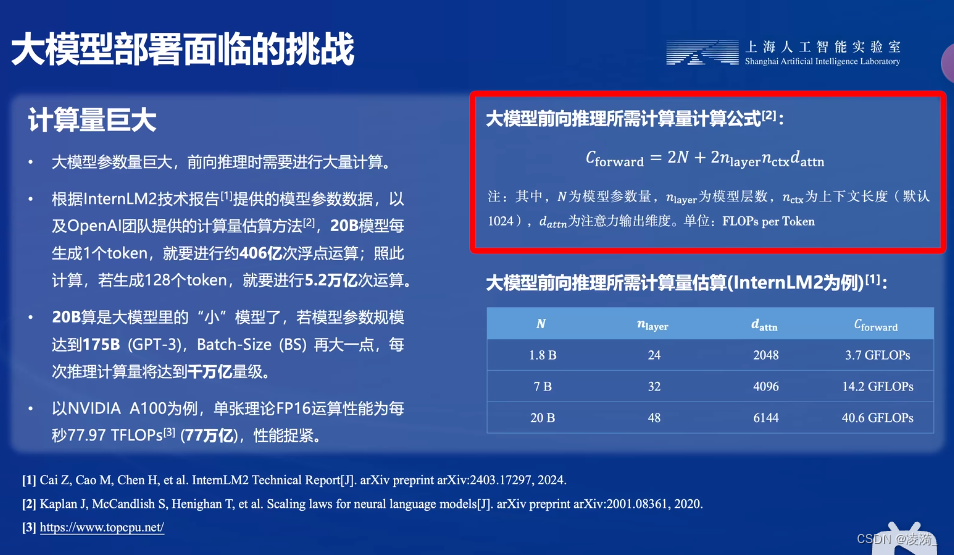
计算量巨大
大模型通常具有数十亿甚至上万亿个参数,需要进行海量的数据处理和计算。在训练过程中,大模型会消耗大量的算力资源。而在部署阶段,为了进行前向推理,同样需要进行大量的计算。这种巨大的计算量对硬件设施提出了很高的要求,需要高性能的计算设备和优化过的算法来支持。
内存开销巨大
大模型在推理过程中会占用大量的内存资源。为了避免重复计算,模型会将计算过程中的一些中间结果缓存起来,这进一步增加了内存开销。此外,加载模型参数本身就需要大量的显存。目前,尽管硬件设备的性能在不断提升,但仍然存在显存带宽与计算速度之间的不匹配问题,导致访存性能瓶颈。
访问瓶颈
随着大模型的规模不断增长,模型参数和数据的访问速度可能成为瓶颈。在分布式计算环境中,节点之间的通信延迟和数据传输速度可能限制模型的整体性能。此外,对于大规模数据的处理和分析,也可能受到存储系统性能的限制。
动态请求
在实际应用中,用户请求往往是动态变化的。对于大模型来说,如何快速响应这些动态请求是一个挑战。特别是在高并发场景下,如何保证服务的稳定性和响应速度是一个重要问题。此外,随着用户需求的不断变化,模型可能需要不断地进行调优和更新,这也增加了部署和维护的难度。
模型剪枝
模型剪枝是一种从神经网络中移除“不必要”权重或偏差的模型压缩技术,旨在通过减少模型中冗余的参数和结构来显著减小模型的尺寸和计算量,从而提高模型的推理速度。这种技术有助于在保持模型性能的同时减小模型的规模,使得模型更加适用于资源受限的环境,如移动设备和嵌入式系统。

知识蒸馏
知识蒸馏(knowledge distillation)是模型压缩的一种常用方法,它不同于模型压缩中的剪枝和量化,而是通过构建一个轻量化的小模型,利用性能更好的大模型的监督信息来训练这个小模型,以期达到更好的性能和精度。
知识蒸馏已广泛应用于深度学习领域,尤其是在边缘计算、人脸识别、自然语言处理、图像分类以及增量学习等场景中。在边缘计算中,由于计算能力的限制,知识蒸馏可以有效地提高边缘设备上神经网络的性能和精度。在人脸识别和自然语言处理等领域,由于深度学习模型通常非常庞大,需要巨大的存储空间和计算能力,知识蒸馏也发挥了重要作用。

量化
大模型量化是指针对大型深度学习模型进行的量化操作,即将模型的连续取值(如float32)近似为有限多个离散值(如int8)的过程。这种量化方法旨在减少模型尺寸和推理时的内存消耗,并在一些低精度运算较快的处理器上增加推理速度。
在大模型量化中,可以针对模型的权重、激活值或两者都进行量化。权重量化仅对模型的权重进行量化操作,以整型形式存储模型权重,从而压缩模型的大小。全量化则同时考虑模型权重和激活值的量化,这样不仅可以进一步压缩模型大小,减少推理过程的内存占用,还可以使用高效的整型运算单元加速推理过程。
 LMDeploy核心功能
LMDeploy核心功能
LMDeploy的核心功能主要包括以下几个方面:
- 高效推理引擎TurboMind:基于FasterTransformer实现的高效推理引擎,支持多种模型(如InternLM、LLaMA、vicuna等)在NVIDIA GPU上的推理。它通过缓存多轮对话过程中的attention的k/v,记住对话历史,从而避免重复处理历史会话,进一步优化模型执行效率。此外,LMDeploy支持TurboMind和Pytorch两种推理后端,提供持久化batch推理,支持动态batch处理,使得大模型推理更加高效。
- 模型量化压缩:量化的主要目的是减小显存占用,提升运行速度。LMDeploy提供了模型量化功能,将模型参数或计算中间结果进行INT8量化,进一步压缩模型大小,减少推理时的内存消耗,同时提高推理速度。此外,其内部的AWQ算法能够高效地实现Weight Only的量化,起到解决现存和提升推理速度的作用。
- 服务化部署:LMDeploy不仅关注模型的推理和量化,还提供了便捷的服务化部署功能。它支持模型的本地推理和部署,可以通过简单的命令启动推理服务,使得模型能够方便地被前端或后端使用。

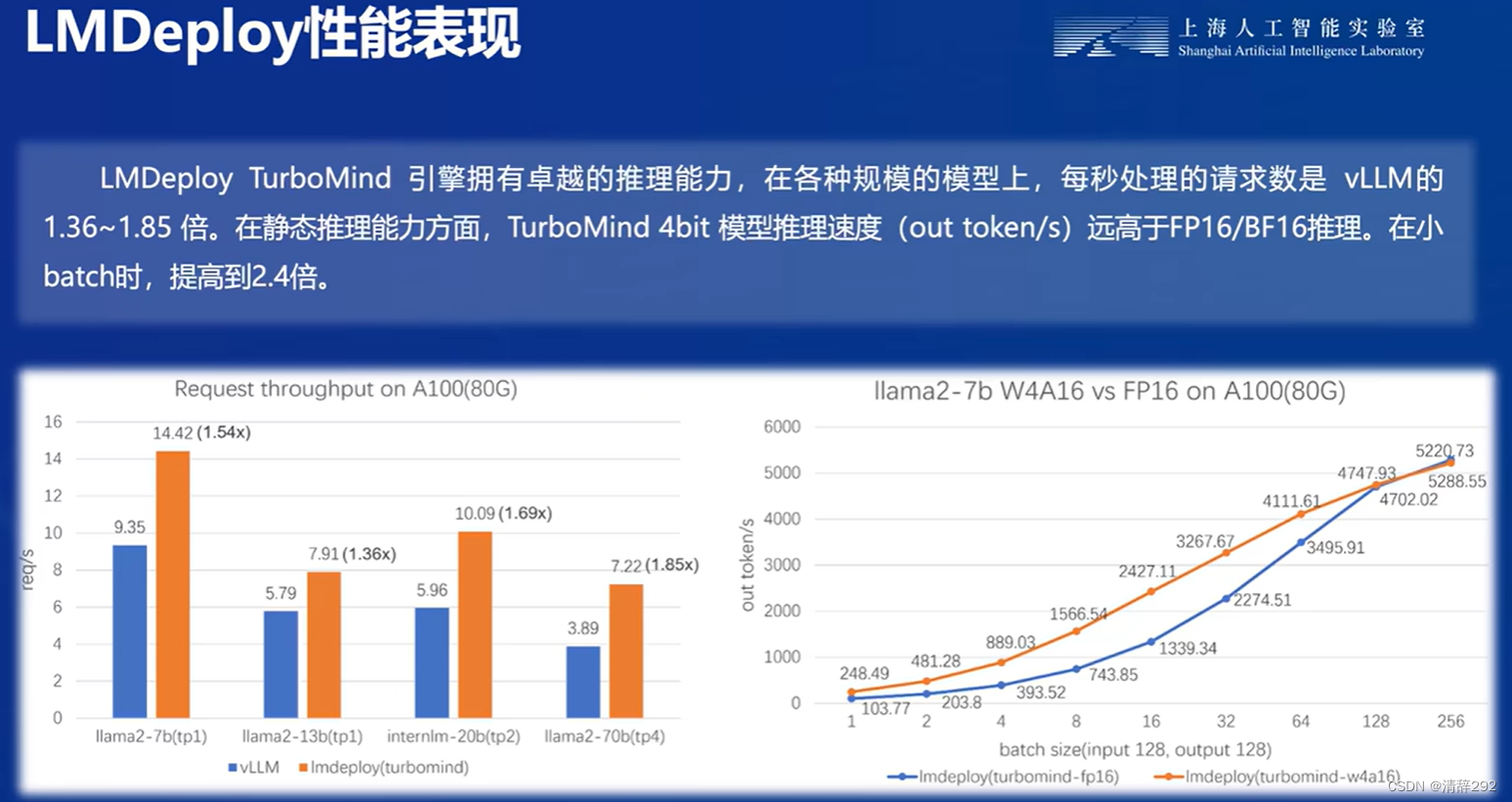
LMDeploy性能表现
LMDeploy在性能表现方面展现出显著的优势。它采用了高效的推理加速框架,具有出色的静态和动态推理性能。具体来说,LMDeploy可以在固定batch的情况下进行静态推理,也可以在真实对话中进行动态推理,处理不定长的输入和输出。这种灵活性使得LMDeploy能够适应不同场景和需求。

![[<span style='color:red;'>InternLM</span>训练<span style='color:red;'>营</span><span style='color:red;'>第二</span><span style='color:red;'>期</span><span style='color:red;'>笔记</span>]5. <span style='color:red;'>LMDeploy</span> <span style='color:red;'>量化</span><span style='color:red;'>部署</span> <span style='color:red;'>LLM</span> <span style='color:red;'>实践</span>](https://img-blog.csdnimg.cn/direct/1e17ac1ca10c4fb69f2fcda944558916.png)