文章目录
LMDeploy环境部署
conda环境->安装LMDeploy
LMDeploy模型对话
HuggingFace
针对深度学习模型和数据集的在线托管社区,托管模型通常为HuggingFace格式存储,简写为HF格式
TurboMind
LMDeploy团队开发的LLM高效推理引擎,功能包括:LLaMa 结构模型的支持,continuous batch 推理模式和可扩展的 KV 缓存管理器。
支持TurboMind格式模型,最新LMDeploy支持自动将hf格式模型转化为TurboMind格式
LMDeploy与TurboMind的关系:TurboMind为LMDeploy的一个子模块,LMDeploy也可以使用pytorch作为推理引擎
使用Transformers库运行模型
model.chat()
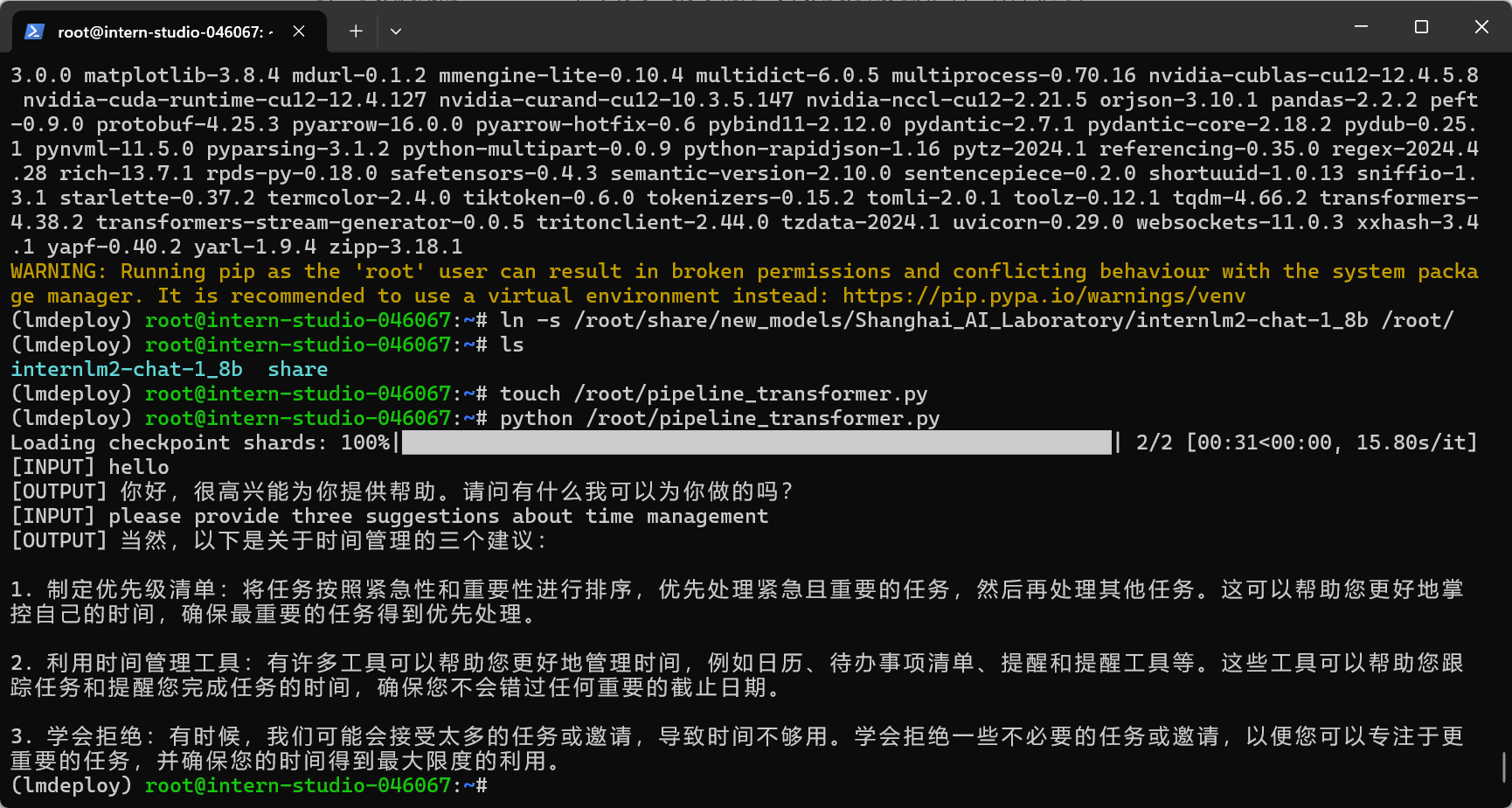
使用LMDeploy与模型对话
这个速度有点快得离谱了
lmdeploy chat [HF格式模型路径/TurboMind格式模型路径]

LMDeploy量化部署(lite)
量化:以参数或计算中间结果精度下降换空间节省(以及同时带来的性能提升)的策略。主要包括KV8量化和W4A16量化。
计算密集型(compute-bound):推理过程中,绝大部分时间消耗在数值计算上,解决办法是使用更快的硬件计算单元
访存密集型(memory-bound):推理过程中,绝大部分时间消耗在数据读取上,减少访存次数、提高计算访存比或降低访存量来优化
常见decoder-only架构的LLM模型,实际推理时大多数的时间都消耗在了逐 Token 生成阶段(Decoding 阶段),是典型的访存密集型
KV8量化:将逐 Token(Decoding)生成过程中的上下文 K 和 V 中间结果进行 INT8 量化(计算时再反量化),以降低生成过程中的显存占用。
W4A16量化:将 FP16 的模型权重量化为 INT4,仅量化权重,数值计算依然采用 FP16(需要将 INT4 权重反量化)
设置最大KV Cache缓存大小
KV Cache技术:通过存储键值对的形式来复用计算结果,以达到提高性能和降低内存消耗的目的。
LMDeploy的KV Cache管理器可以通过设置--cache-max-entry-count参数控制KV缓存占用剩余显存的最大比例,默认值为0.8
默认值部署:

改变--cache-max-entry-count参数,设为0.5,部署占用显存状况

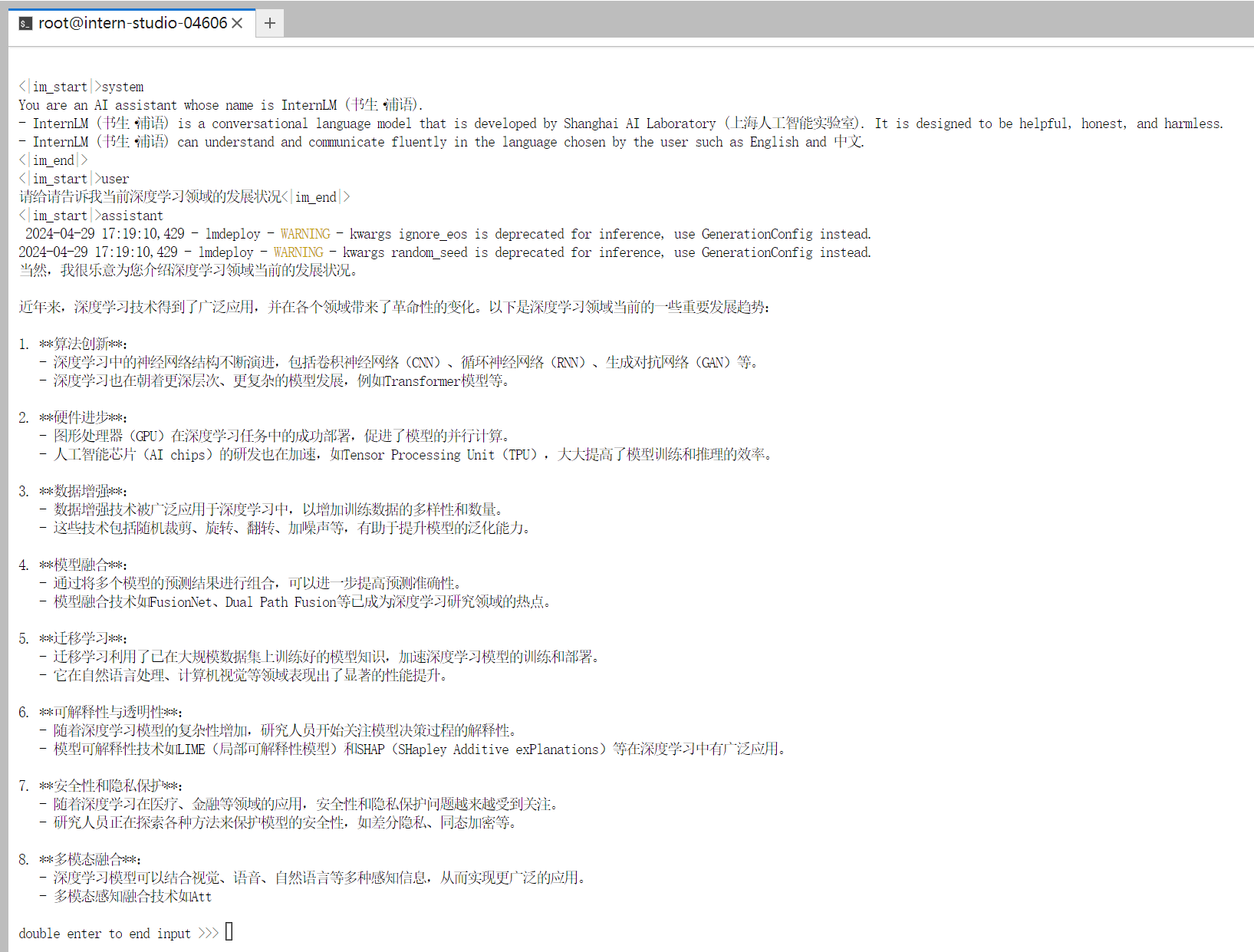
把--cache-max-entry-count参数设置为0.01,约等于禁止KV Cache占用显存,部署占用显存状况

速度还是挺快的,但是结果不是那么好?

下面是默认的--cache-max-entry-count = 0.8的chat效果

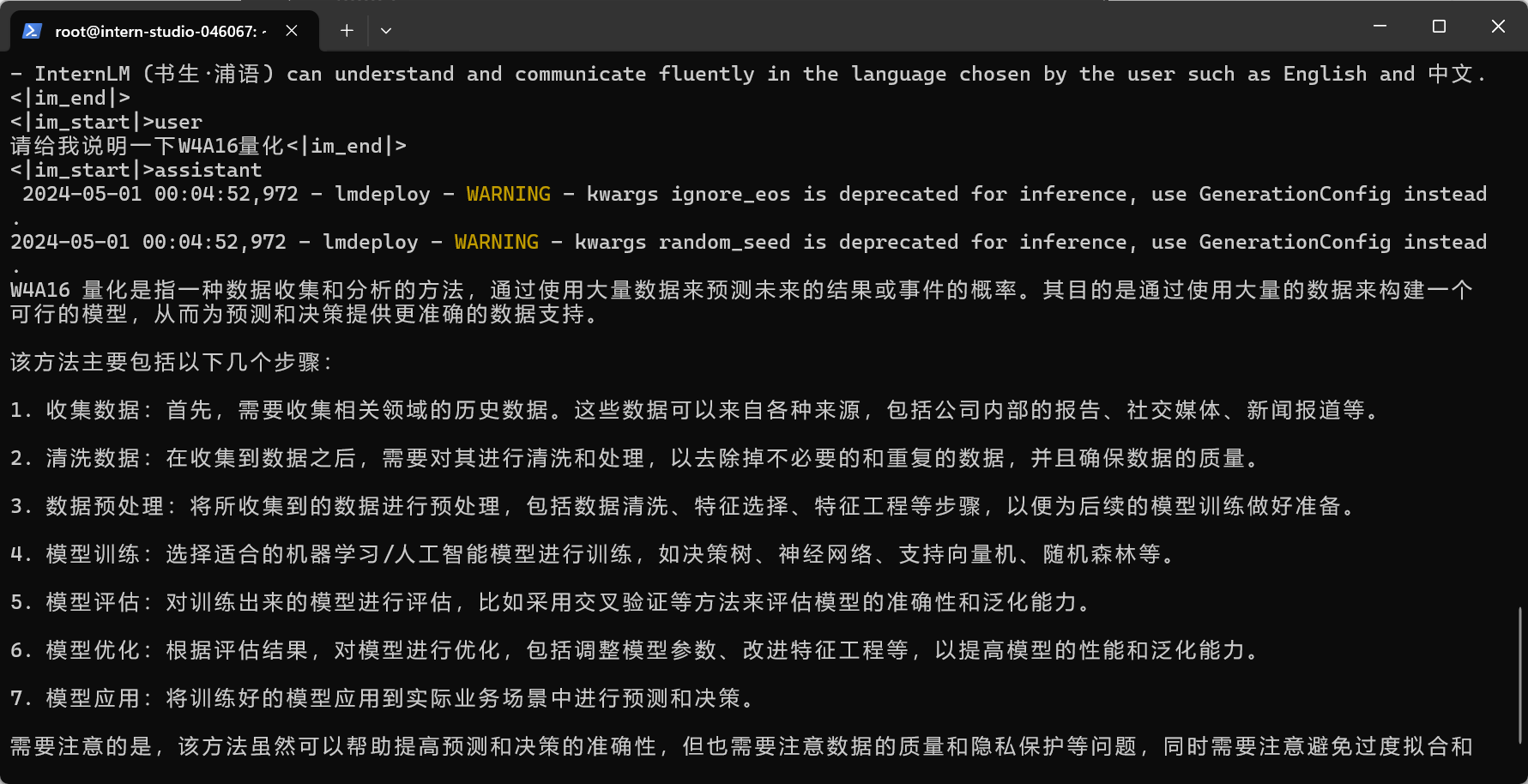
使用W4A16量化
LMDeploy使用AWQ算法,实现模型4bit权重量化
模型量化:
lmdeploy lite auto_awq /root/internlm2-chat-1_8b --calib-dataset 'ptb' --calib-samples 128 --calib-seqlen 102 --w-bits 4 --w-group-size 128 --work-dir /root/internlm2-chat-1_8b-4bit
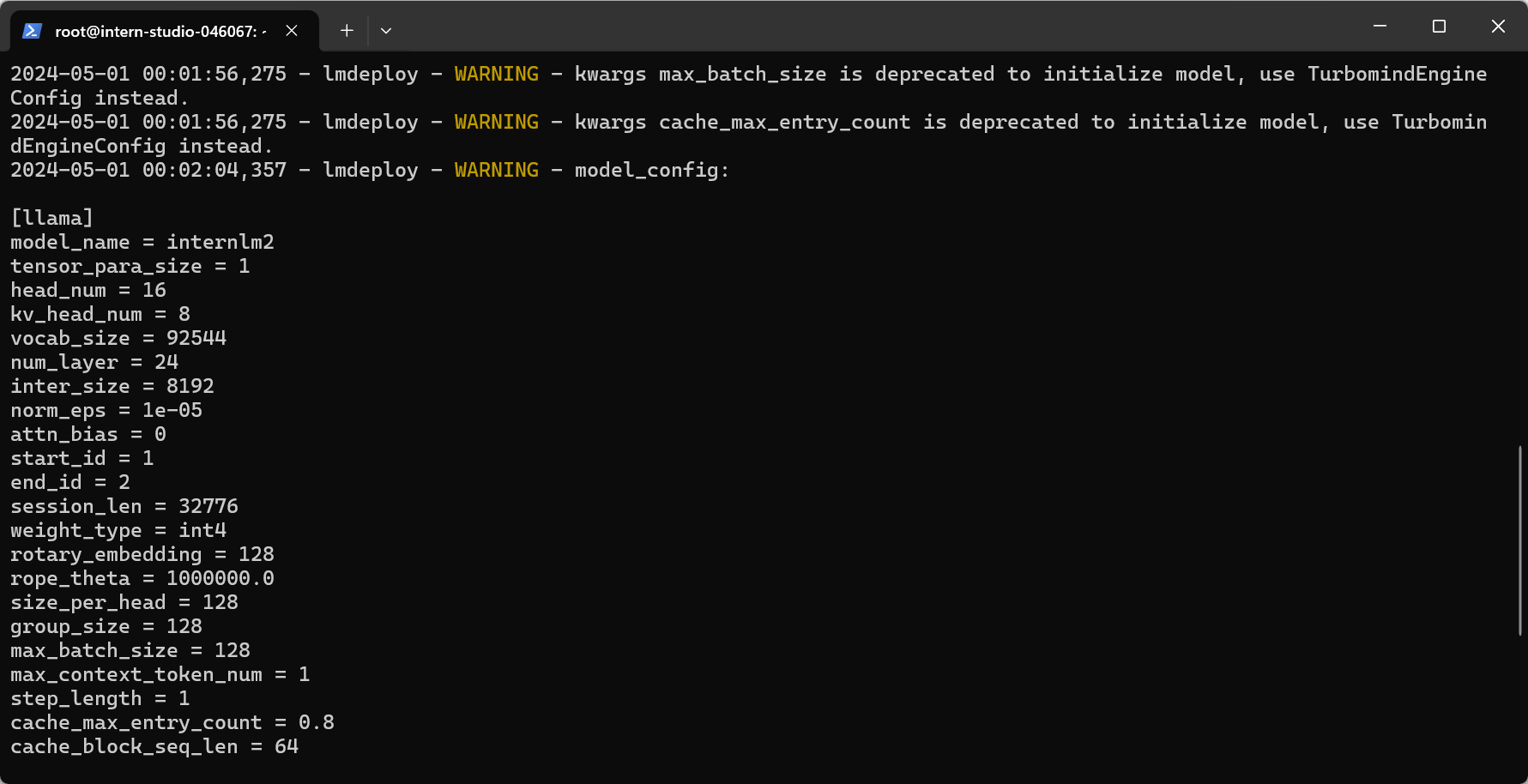
lmdeploy chat运行W4A16量化后的模型(使用–model-format参数):
lmdeploy chat /root/internlm2-chat-1_8b-4bit --model-format awq
显存占用情况

结果显示,这个模型好像不太理解W4A16量化,乱生成
加上KV Cache控制(--cache-max-entry-count 0.01)的例子
显存占用情况展示:

LMDeploy服务(serve)
将llm封装为一个服务,提供api供客户端使用
架构图展示:
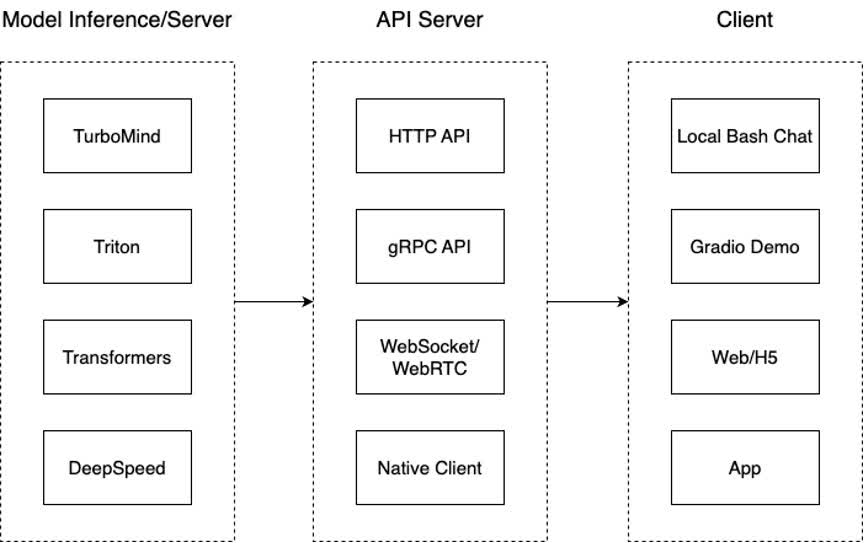
一共三个模块
模型推理/服务:和具体业务解耦,专注模型推理本身性能的优化。可以以模块、API等多种方式提供。
API Server:把后端推理/服务通过HTTP,gRPC或其他形式的接口,供前端调用
Client:通过通过网页端/命令行去调用API接口,获取模型推理/服务
启动API服务器
lmdeploy serve api_server /root/internlm2-chat-1_8b --model-format hf --quant-policy 0 --server-name 0.0.0.0 --server-port 23333 --tp 1
FASTAPI使用说明网页版

命令行客户端连接FASTAPI服务器
lmdeploy serve api_client http://localhost:23333
效果展示:
现在的服务架构
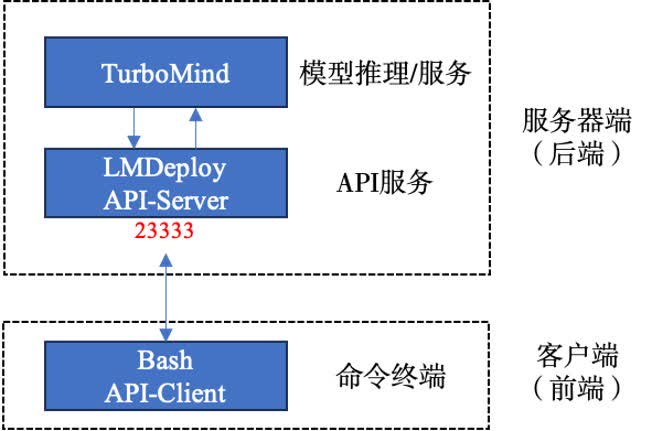
网页客户端连接FASTAPI服务器
# 使用gradio作为前端启动网页客户端
lmdeploy serve gradio http://localhost:23333 --server-name 0.0.0.0 --server-port 6006
现在的架构图:
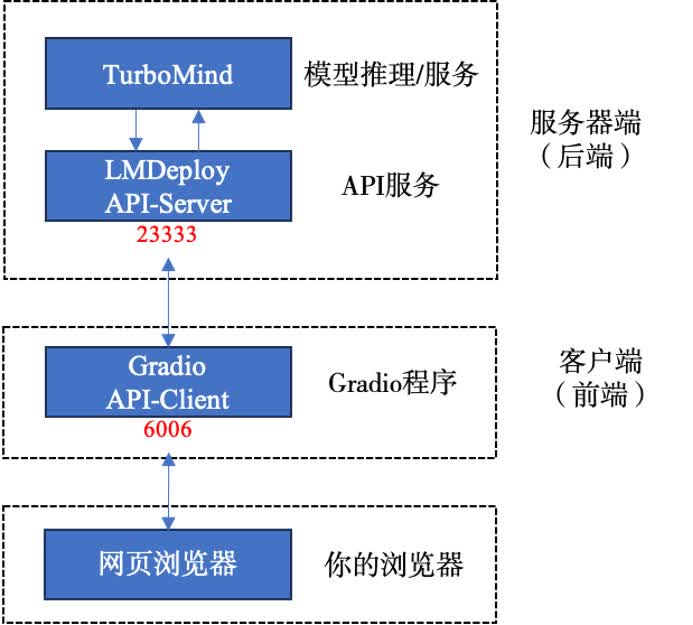
Python代码集成
直接推理
使用lmdeploy的pipeline模块,加载模型,模型推理调用
from lmdeploy import pipeline
pipe = pipeline('/root/internlm2-chat-1_8b')
response = pipe(['Hi, pls intro yourself', '上海是'])
print(response)

在python代码中配置TurboMind
通过创建TurbomindEngineConfig,向lmdeploy传递参数
from lmdeploy import pipeline, TurbomindEngineConfig
# 调低 k/v cache内存占比调整为总显存的 20%
backend_config = TurbomindEngineConfig(cache_max_entry_count=0.2)
pipe = pipeline('/root/internlm2-chat-1_8b',
backend_config=backend_config)
response = pipe(['Hi, pls intro yourself', '上海是'])
print(response)
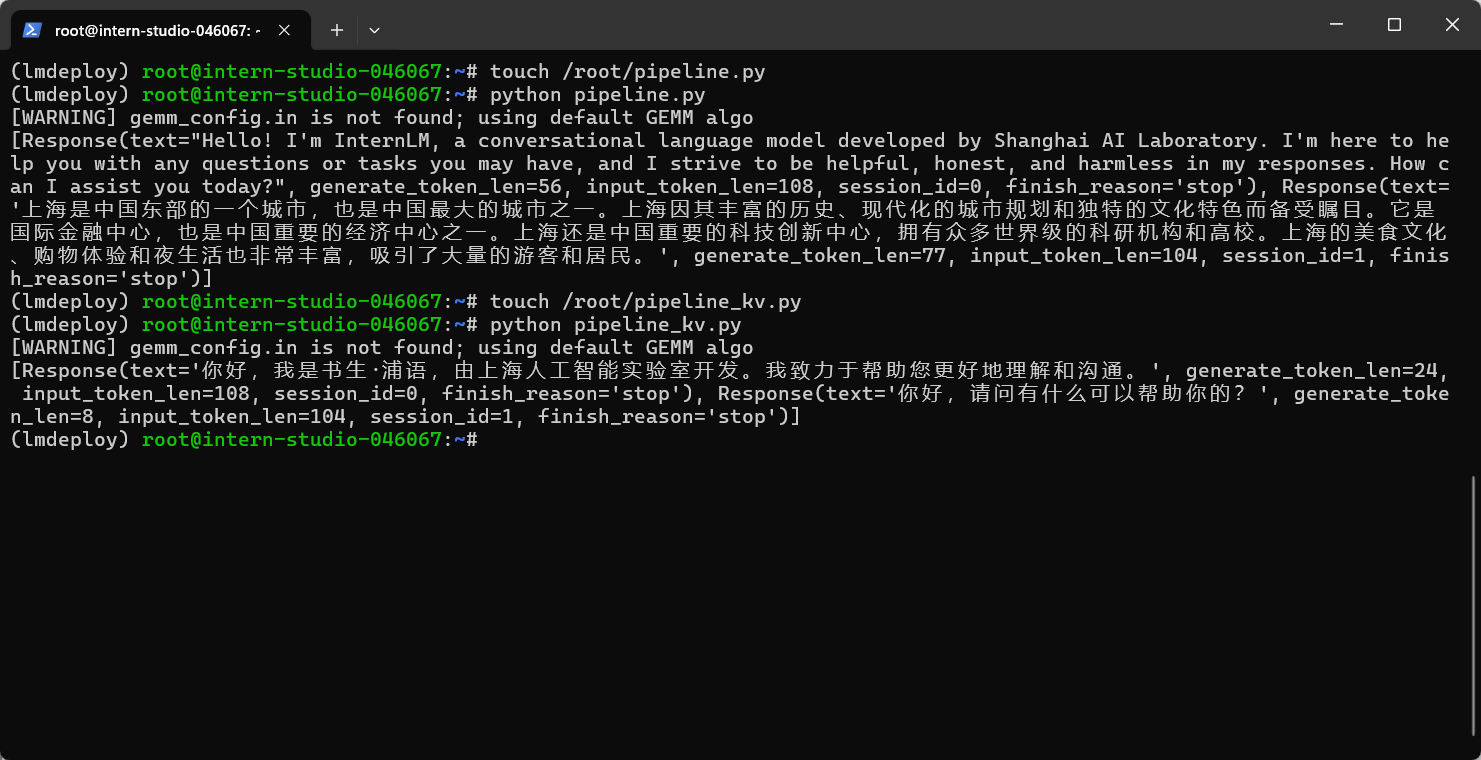
没回答第二个问题,不懂为什么会这样子

![[<span style='color:red;'>书生</span>·<span style='color:red;'>浦</span><span style='color:red;'>语</span><span style='color:red;'>大</span><span style='color:red;'>模型</span><span style='color:red;'>实战</span><span style='color:red;'>营</span>]——<span style='color:red;'>LMDeploy</span> <span style='color:red;'>量化</span><span style='color:red;'>部署</span> <span style='color:red;'>LLM</span> <span style='color:red;'>实践</span>](https://img-blog.csdnimg.cn/direct/8d577c3ced1b42588c295eb8f7ad0e7f.png)




![[InternLM训练<span style='color:red;'>营</span><span style='color:red;'>第二</span><span style='color:red;'>期</span><span style='color:red;'>笔记</span>]<span style='color:red;'>5</span>. <span style='color:red;'>LMDeploy</span> <span style='color:red;'>量化</span><span style='color:red;'>部署</span> <span style='color:red;'>LLM</span> <span style='color:red;'>实践</span>](https://img-blog.csdnimg.cn/direct/1e17ac1ca10c4fb69f2fcda944558916.png)