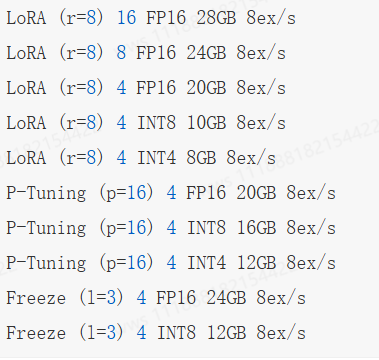
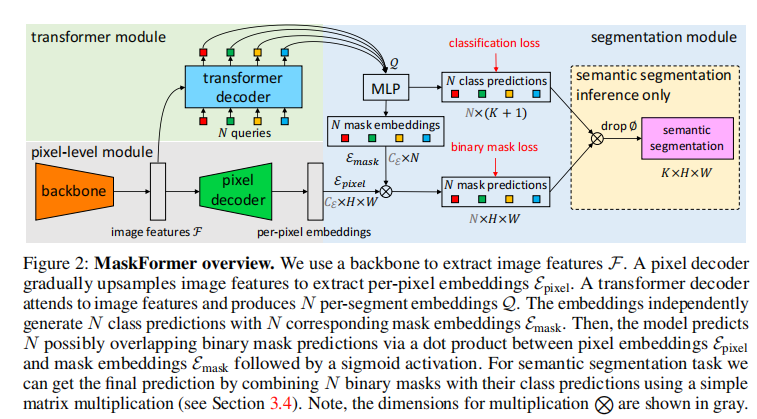
微调大模型基本思路
一般来说, 垂直领域的现状就是大家积累很多垂域数据,从现实出发,第一步可以先做增量训练.所以会把模型分成3个阶段:
(1)、第一阶段:(Continue PreTraining)增量预训练,在海量领域文档数据(领域知识)上二次预训练base模型,以注入领域知识。属于无监督学习,让模型自己寻找语言的规律, 这样一个巨大的词向量空间就形成了
(2)、第二阶段: SFT(Supervised Fine-tuning)有监督微调,构造指令微调数据集,在预训练模型基础上做指令精调,以对齐指令意图。可以激发大模型理解领域内的各种问题并进行回答的能力(在有召回知识(从其先前的训练数据或经验中提取并回忆起的知识)的基础上),教会模型什么该说,什么不该说(训练数据集)
(3)、第三阶段 : RLHF和DPO二选一
RLHF(Reinforcement Learning from Human Feedback)基于人类反馈对语言模型进行强化学习,分为两步:
- RM(Reward Model)奖励模型建模,构造人类偏好排序数据集,训练奖励模型,用来建模人类偏好,
- RL(Reinforcement Learning)强化学习,用奖励模型来训练SFT模型,生成模型使用奖励或惩罚来更新其策略,以便生成更高质量、更符合人类偏好的回答,给模型的回答进行打分,告诉他在他的一众回答中,哪些回答更好。(验证数据集)
DPO(Direct Preference Optimization)直接偏好优化方法,DPO通过直接优化语言模型来实现对其行为的精确控制,而无需使用复杂的强化学习,也可以有效学习到人类偏好,DPO相较于RLHF更容易实现且易于训练,效果更好
增量预训练灾难性遗忘
目前不少开源模型在通用领域具有不错的效果,但由于缺乏领域数据,往往在一些垂直领域中表现不理想,这时就需要增量预训练和微调等方法来提高模型的领域能力。但在领域数据增量预训练或微调时,很容易出现灾难性遗忘现象,也就是学会了垂直领域知识,但忘记了通用领域知识,
办法:
- 领域数据和通用数据的比率,结合具体数据:10%,15%,20%的都有。方案之一是:让无监督数据和指令数据混合,合并增量预训练和微调两个阶段。
- 降低学习率,增量预训练2e-5;指令微调需要更低1e-6;但是得多跑几轮不然学不到领域知识
- 在第一轮训练的时候,每个数据点对模型来说都是新的,模型会很快地进行数据分布修正,如果这时候学习率就很大,极有可能导致开始的时候就对该数据“过拟合”,后面要通过多轮训练才能拉回来,浪费时间。当训练了一段时间(比如两轮、三轮)后,模型已经对每个数据点看过几遍了,或者说对当前的batch而言有了一些正确的先验,较大的学习率就不那么容易会使模型学偏,所以可以适当调大学习率。这个过程就可以看做是warmup。那么为什么之后还要decay呢?当模型训到一定阶段后(比如十个epoch),模型的分布就已经比较固定了,或者说能学到的新东西就比较少了。如果还沿用较大的学习率,就会破坏这种稳定性,用我们通常的话说,就是已经接近loss的local optimal了,为了靠近这个point,我们就要慢慢来。
- 对新任务中参数的变化施加惩罚
- 知识蒸馏(KD),使微调模型的预测结果接近旧模型的预测结果。
注意:
1.二次预训练可能效果一般,不如直接sft,有可能是数据配比的问题
2.sft可以快速看到不错的结果,但会发现要提高上限比较困难。
3.通用大模型+向量知识库:领域知识库加上通用大模型,针对通用大模型见过的知识比较少的问题,利用向量数据库等方式根据问题在领域知识库中找到相关内容,再利用通用大模型强大的summarization和qa的能力生成回复
4.如果你只有5k数据,建议你在Chat模型上进行微调;
如果你有10w数据,建议你在Base模型上进行微调。
5. 数据配比(合通用数据以缓解模型遗忘通用能力)
(1)从头训练的BloombergGPT数据配比通用数据:金融数据1:1,效果很差
(2)二次预训练如果要让模型不丢失通用能力,比如summarization,qa等,「领域数据的比例要在15%以下」,一旦超过这个阈值,模型的通用能力会下降很明显。最好在在10%-15%左右,而且,该阈值和预训练模型的大小,预训练时原始数据的比例等条件都息息相关,需要在实践中反复修正。这个结果其实和ChatGPT大概用不到10%的中文数据就能得到一个很不错的中文模型的结果还挺相似的。这个经验也告诉我们不要轻易用continue pretraing或者from scratch pretraining的方法做行业大模型,每100B的领域数据,需要配上700B-1000B的通用数据,这比直接训练通用大模型要困难多了。(领域:通用数据比例为1:5时最优,应该跟领域数据量有关,当数据量没有那多时,一般数据比例在1:5到1:10之间是比较合适的。)
(3)对sft来说,这个比例就可以提高不少,大概领域数据和通用数据比例在1:1的时候还是有不错的效果的。当然,如果sft的数据量少,混不混数据的差别就不太大了。所以说,做pretraining不仅耗资源,需要大量的卡和数据,还需要大量的实验去调数据配比。(从头训练可能需要几百张卡,而sft只需要几张卡)
(4)领域相关网站内容、新闻内容都是重要数据,但在领域上的重要性或者知识密度可能不如领域书籍和技术标准。
6.
大模型的训练成本,以GPT-3为例:GPT-3需要400-500个A100/年(用400-500张A100训1年),假设不买显卡,租公有云,现在8张A100包年的价格大概一年80万,一次性走量打五折40万,训练GPT-3的成本大概是2500万人民币。
上面的讨论是按照GPU跑满100%的使用率来计算,实际上GPU永远是有被浪费的时候,浪费的原因可能是:
- 显卡不稳定,可能会挂掉
- 由于显卡容易挂掉,需要做checkpointing,而每次checkpoint的保存可能也需要分钟级别的时间成本
- CUDA core大多数时候也是跑不满的,需要等显存带宽的I/O、 IB网络的I/O等等
7.炼丹技巧
- 在小模型上做实验的方法,又会遇到在小模型上的实验挺好,但一到100B这个级别就会发现各种loss的不收敛/猛增(梯度爆炸或模型结构不合理)/飞掉(即损失值异常高或波动剧烈)的问题。采用的策略可能是回退几步checkpoint,或者扔掉这一部分数据(如噪声数据、异常值等),然后接着往前走。
- FP32/FP16/BF16的选择问题:更倾向于BF16,因为看起来更好收敛。(FP32(Floating Point 32-bit)适合需要高精度计算的应用场景、FP16(半精度浮点数)通常用于需要较高数值精度的场景,如图形处理和一些深度学习任务、BF16(Brain Floating Point 16-bit)是一种介于FP32和FP16之间的格式,其数值范围与FP32相同,但精度较低。它适用于深度学习中的一些应用,特别是在神经网络的训练阶段,可以加快计算速度并减少内存使用,同时保持足够的精度)
- 在硬件的选择上,尽可能用最先进的显卡进行训练,因为:第一,性能上的差异巨大,以A800和H100为例,算力差了六倍,然后通信带宽也差了两倍;第二,在落后的显卡上去训练,需要考虑更多的分布式问题,而将来迁移到高端显卡上的时候,在老显卡上累积的经验能直接用上的不多。
- 并行计算方案的选择:Megatron-DeepSpeed是现在比较SOTA的一个方案。
- 通过人工标注,然后纯做finetune,可以达到八成效果。但是想走的更远的话,那只能靠强化学习。
- 奖励模型(RM)训练叫做reward hacking的现象,开放的决策对于模拟打分环境来说难度太大了,对奖励模型的泛化程度有极其高的要求。最终大概率你的模型学习到了输出一堆没什么用的东西,但是RM分数很高。这就是reward hacking(来自 【大模型训练的一些坑点和判断】 )
- 评估的问题:同时模型的评估也是一个可能会有坑点的地方:评估做不好 = 费钱费时;所以你做实验慢了,相当于比别人少了GPU
- 过拟合的问题:只用领域数据非常容易过拟合到领域数据上,对Out of Distribution (OOD) 数据(即与训练数据分布不同的数据)的处理会表现的非常差。想让他在某一个方向加深能力,并且保持原有的能力不下降,整体要付出的成本不下于重新塑造一个通用大模型。
- DPO这种方法,可以省掉PPO采样的时间。DPO在对齐的时候,把RM和采样的压力,转化为标注数据的压力。
- 多轮对话如何组织训练样本
- pretraining让大模型具有基本的知识储备和语言模型的泛化,这样给SFT一个很好的初始化,降低SFT阶段的数据消耗,让他初步对齐人的习惯。SFT更像是给RL阶段的采样一个冷启动的能力,防止采样到的东西超出了RM的判别能力圈,让他尽量的接近RM限定的好的和坏的的范围之内。SFT相比RL训练过程,其达到的泛化能力上限是比较差的,因为数据总有尽头,高质量的数据更是难上加难,最后在RL阶段,把无限的数据生成交给采样的过程,把判别好坏的过程交给RM
- 大模型LLM微调经验总结&项目更新
参考:
微调实操一: 增量预训练(Pretraining)-CSDN博客
大模型增量预训练新技巧:解决灾难性遗忘_灾难性遗忘 大模型-CSDN博客