1.peft
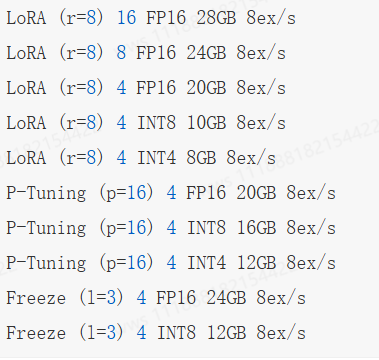
1.1 微调方法批处理大小模式GPU显存速度
1.2 当前高效微调技术存在的一些问题
当前的高效微调技术很难在类似方法之间进行直接比较并评估它们的真实性能,主要的原因如下所示:
- 参数计算口径不一致:参数计算可以分为三类: 可训练参数的数量、微调模型与原始模型相比改变的参数的数量、微调模型和原始模型之间差异的等级。例如,DiffPruning更新0.5%的参数,但是实际参与训练的参数量是200%。这为比较带来了困难。尽管可训练的参数量是最可靠的存储高效指标,但是也不完美。Ladder-sideTuning使用一个单独的小网络,参数量高于LoRA或BitFit,但是因为反向传播不经过主网络,其消耗的内存反而更小。
- 缺乏模型大小的考虑:已有工作表明,大模型在微调中需要更新的参数量更小(无论是以百分比相对而论还是以绝对数量而论),因此(基)模型大小在比较不同PEFT方法时也要考虑到。
- 缺乏测量基准和评价标准:不同方法所使用的模型/数据集组合都不一样,评价指标也不一样,难以得到有意义的结论。
- 代码实现可读性差:很多开源代码都是简单拷贝Transformer代码库,然后进行小修小补。这些拷贝也不使用git fork,难以找出改了
哪里。即便是能找到,可复用性也比较差(通常指定某个Transformer版本,没有说明如何脱离已有代码库复用这些方法)。
1.3 高效微调技术最佳实践
针对以上存在的问题,研究高效微调技术时,建议按照最佳实践进行实施:
- 明确指出参数数量类型。
- 使用不同大小的模型进行评估。
- 和类似方法进行比较。
- 标准化PEFT测量基准。重视代码清晰度,以最小化进行实现。
1.4 PEFT存在问题?
相比全参数微调,大部分的高效微调技术目前存在的两个问题:
- 推理速度会变慢;
- 模型精度会变差;
1.5 简单总结一下各种参数高效微调方法?
- 增加额外参数:PrefixTuning、Prompt Tuning、Adapter Tuning及其变体。
- 选取一部分参数更新:BitFit。
- 引入重参数化:LoRA、AdaLoRA、QLoRA。
- 混合高效微调:MAM Adapter、UniPELT。
2.适配器微调(Adapter-tuning)
2.1适配器微调(Adapter-tuning)思路
- 设计了Adapter结构(首先是一个down-project层将高维度特征映射到低维特征,然后过一个非线形层之后,再用一个up-project结构将低维特征映射回原来的高维特征;同时也设计了skip-connection结构,确保了在最差的情况下能够退化为identity),并将其嵌入Transformer的结构里面;
- 在训练时,固定住原来预训练模型的参数不变,只对新增的Adapter结构进行微调。同时为了保证训练的高效性(也就是尽可能少的引入更多参数)。
2.2 适配器微调(Adapter-tuning)特点
- 通过在Transformer层中嵌入Adapter结构,在推理时会额外增加推理时长。
3.LoRA参数配置
# 设置超参数及配置
LORA_R =8
LORA_ALPHA = 16
LORA_DROPOUT = 0.05
TARGET_MODULES =[
"q_proj",
"v_proj",
]
config = LoraConfig(
r=LORA_R,
lora_alpha=LORA_ALPHA,
target_modules=TARGET_MODULES,
lora_dropout=LORA_DROPOUT,
bias="none",
task_type="CAUSAL_LM",
)

4.训练数据
用的 alpaca_gpt4_data_zh.json :https://github.com/Instruction-Tuning-with-GPT-4/GPT-4-LLM/blob/main/data/alpaca_gpt4_data_zh.json
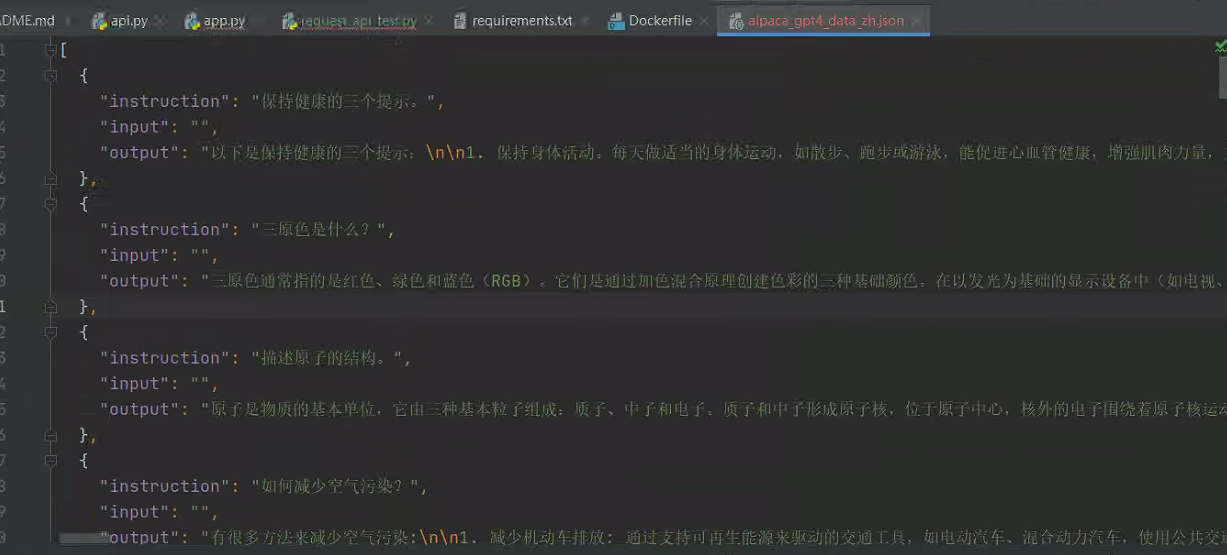
注意,使用本地数据要在dataset_info.json 添加描述: https://github.com/hiyouga/LLaMA-Factory/blob/main/data/README_zh.md
在指令监督微调时,instruction 列对应的内容会与 input 列对应的内容拼接后作为人类指令,即人类指令为 instruction\ninput。而 output 列对应的内容为模型回答。
如果指定,system 列对应的内容将被作为系统提示词。
history 列是由多个字符串二元组构成的列表,分别代表历史消息中每轮对话的指令和回答。注意在指令监督微调时,历史消息中的回答内容也会被用于模型学习。
[
{
"instruction": "人类指令(必填)",
"input": "人类输入(选填)",
"output": "模型回答(必填)",
"system": "系统提示词(选填)",
"history": [
["第一轮指令(选填)", "第一轮回答(选填)"],
["第二轮指令(选填)", "第二轮回答(选填)"]
]
}
]
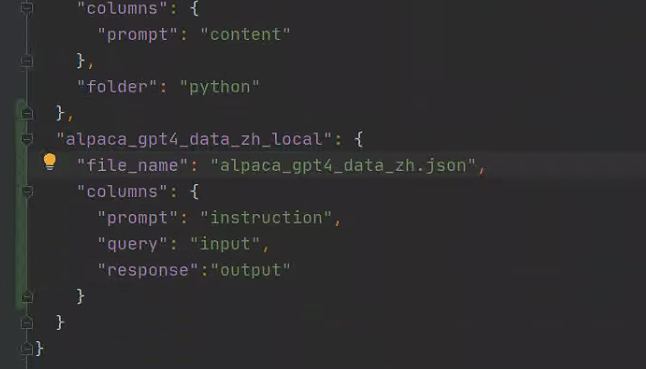
对于上述格式的数据,dataset_info.json 中的数据集描述应为:
"数据集名称": {
"file_name": "data.json",
"columns": {
"prompt": "instruction",
"query": "input",
"response": "output",
"system": "system",
"history": "history"
}
}
5. 开始训练
llamafactory-cli train \
--stage sft \
--do_train True \
--model_name_or_path ./models/Qwen1.5-0.5B\
--preprocessing_num_workers 16 \
--finetuning_type lora \
--template qwen \
--flash_attn auto \
--dataset_dir data \
--dataset alpaca_gpt4_data_zh_local\
--cutoff_len 1024 \
--learning_rate 5e-05 \
--num_train_epochs 3.0 \
--max_samples 100000 \
--per_device_train_batch_size 2 \
--gradient_accumulation_steps 8 \
--lr_scheduler_type cosine \
--max_grad_norm 1.0 \
--logging_steps 5 \
--save_steps 100 \
--warmup_steps 0 \
--optim adamw_torch \
--packing False \
--report_to none \
--output_dir saves/Qwen1.5-0.5B_alpaca_gpt4_data_zh/lora/sft \
--fp16 True \
--plot_loss True \
--ddp_timeout 180000000 \
--include_num_input_tokens_seen True \
--lora_rank 8 \
--lora_alpha 16 \
--lora_dropout 0 \
--use_rslora True \
--lora_target all
也可以用yaml文件训练,但是注意 学习率用浮点数,用1e-5 自然对数会报错,1.0e-5就没问题
llamafactory-cli train examples/lora_multi_gpu/llama3_lora_sft.yaml
#llama3_lora_sft.yaml
### model
model_name_or_path: ./models/Qwen1.5-0.5B\
### method
stage: sft
do_train: true
finetuning_type: lora
lora_target: all
### dataset
dataset: alpaca_gpt4_data_zh_local
template: qwen
cutoff_len: 1024
max_samples: 1000
overwrite_cache: true
preprocessing_num_workers: 16
### output
output_dir: saves/Qwen1.5-0.5B_alpaca_gpt4_data_zh/lora/sft
logging_steps: 10
save_steps: 500
plot_loss: true
overwrite_output_dir: true
### train
per_device_train_batch_size: 1
gradient_accumulation_steps: 8
#learning_rate: 1.0e-4
learning_rate: 0.00001
num_train_epochs: 3.0
lr_scheduler_type: cosine
warmup_ratio: 0.1
fp16: true
### eval
val_size: 0.1
per_device_eval_batch_size: 1
eval_strategy: steps
eval_steps: 500

PS:windows 需要安装新版本的
pip uninstall bitsandbytes
pip install https://github.com/jllllll/bitsandbytes-windows-webui/releases/download/wheels/bitsandbytes-0.41.0-py3-none-win_amd64.whl
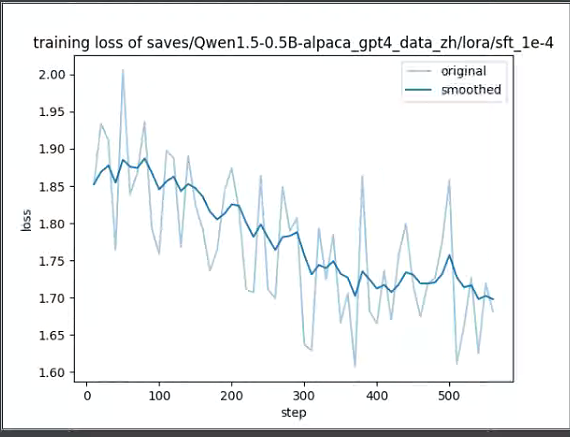
试了 学习率 0.00001、1.0e-4、1.0e-5 三个epoch, 1.0e-4loss 表现最好,又试了1.0e-4五个epoch

6. 使用训练的模型进行推理
CUDA_VISIBLE_DEVICES=7 API_PORT=8030 llamafactory-cli api \
--model_name_or_path .\models\Qwen1.5-0.5B \
--adapter_name_or_path .\saves/Qwen1.5-0.5B_alpaca_gpt4_data_zh/lora/sft\
--finetuning_type lora\
--template qwen

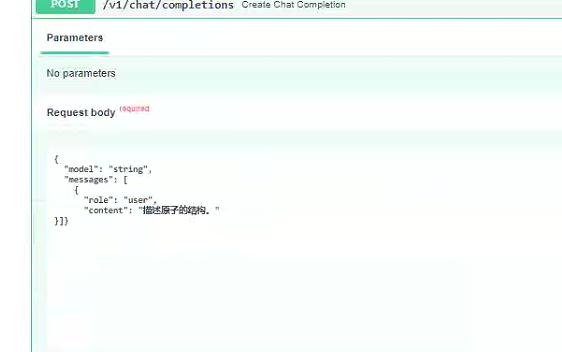
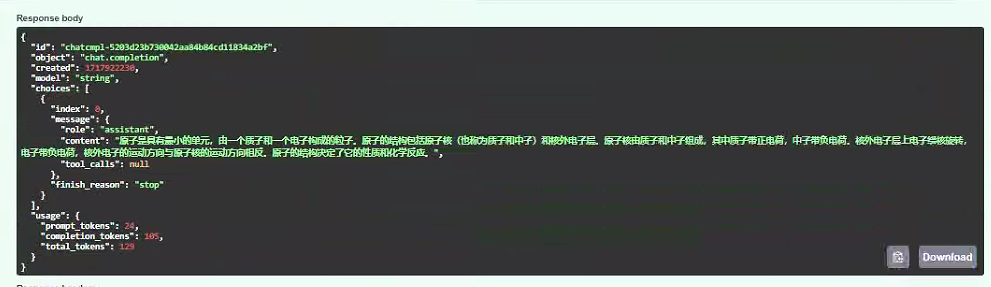
补充,以下先别看,版本有变化,内容待验证更新
lora大模型指令监督微调评测
CUDA_VISIBLE_DEVICES=0 python src/evaluate.py \--model_name_or_path path_to_llama_model \--adapter_name_or_path path_to_checkpoint \--template vanilla \--finetuning_type lora \--task ceval \--split validation \--lang zh \--n_shot 5 \--batch_size 4
大模型指令监督微调预测
CUDA_VISIBLE_DEVICES=0 python src/train_bash.py \--stage sft \--do_predict \--model_name_or_path path_to_llama_model \--adapter_name_or_path path_to_checkpoint \--dataset alpaca_gpt4_zh \--template default \--finetuning_type lora \--output_dir path_to_predict_result \--per_device_eval_batch_size 1 \--max_samples 100 \--predict_with_generate \--fp16
如果使用 fp16 精度进行 LLaMA-2 模型的预测,请使用 --per_device_eval_batch_size=1。
建议在量化模型的预测中使用 --per_device_eval_batch_size=1 和 --max_target_length 128
0、多 GPU 分布式训练
0.1 使用 Huggingface Accelerate
accelerate launch --config_file config.yaml src/train_bash.py # 参数同上
使用 Accelerate 进行 LoRA 训练的 config.yaml 示例
compute_environment: LOCAL_MACHINE
debug: false
distributed_type: MULTI_GPU
downcast_bf16: 'no'
gpu_ids: all
machine_rank: 0
main_training_function: main
mixed_precision: fp16
num_machines: 1
num_processes: 4
rdzv_backend: static
same_network: true
tpu_env: []
tpu_use_cluster: false
tpu_use_sudo: false
use_cpu: false
推荐使用 Accelerate 进行 LoRA 训练。
0.2 使用 DeepSpeed
deepspeed --num_gpus 8 src/train_bash.py \--deepspeed ds_config.json \... # 参数同上
使用 DeepSpeed ZeRO-2 进行全参数训练的 ds_config.json 示例
{
"train_batch_size": "auto",
"train_micro_batch_size_per_gpu": "auto",
"gradient_accumulation_steps": "auto",
"gradient_clipping": "auto",
"zero_allow_untested_optimizer": true,
"fp16": {
"enabled": "auto",
"loss_scale": 0,
"loss_scale_window": 1000,
"initial_scale_power": 16,
"hysteresis": 2,
"min_loss_scale": 1
},
"bf16": {
"enabled": "auto"
},
"zero_optimization": {
"stage": 2,
"allgather_partitions": true,
"allgather_bucket_size": 5e8,
"overlap_comm": true,
"reduce_scatter": true,
"reduce_bucket_size": 5e8,
"contiguous_gradients": true,
"round_robin_gradients": true
}
}
更多训练脚本请查看 examples
合并 LoRA 权重并导出模型
CUDA_VISIBLE_DEVICES=0 python src/export_model.py \--model_name_or_path path_to_llama_model \--adapter_name_or_path path_to_checkpoint \--template default \--finetuning_type lora \--export_dir path_to_export \--export_size 2 \--export_legacy_format False
尚不支持量化模型的 LoRA 权重合并及导出。
仅使用 --model_name_or_path path_to_export 来加载导出后的模型。
合并 LoRA 权重之后可再次使用 --export_quantization_bit 4 和 --export_quantization_dataset data/c4_demo.json 基于 AutoGPTQ 量化模型。
参考
原文:非一般程序员第三季——大模型PEFT(二) 之 大模型LoRA指令微调实践
peft 笔记
适配器微调笔记
如何使用peft中的LoRA