一、关于 Unsloth
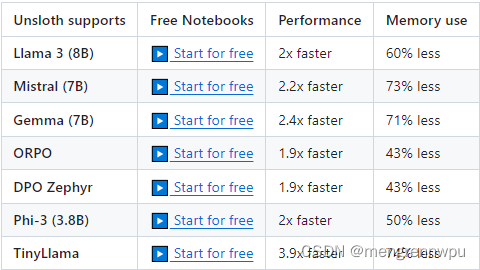
Finetune Llama 3, Mistral, Phi & Gemma LLMs 2-5x faster with 80% less memory
主要特点⭐
- 所有内核用OpenAI的Triton语言编写。手动反推引擎。
- 0%的精度损失-没有近似方法-全部精确。
- 硬件不变。自2018年以来支持NVIDIA GPU。
最低CUDA能力7.0(V100、T4、Titan V、RTX 20、30、40x、A100、H100、L40等)检查您的GPU!
GTX 1070、1080工作正常,但速度很慢。 - 通过WSL在Linux和Windows上工作。
- 通过bitsandbytes支持4bit和16bit QLoRA/LoRA微调。
- 开源训练速度快5倍 – 请参阅Unslth Pro,训练速度快30倍!
- 如果你训练了一个模型与🦥树懒,你可以使用这个很酷的贴纸!
二、安装说明 💾
1、使用 Conda
选择pytorch-cuda=11.8用于CUDA 11.8 或 pytorch-cuda=12.1用于CUDA 12.1。如果您有mamba,请使用mamba而不是conda以更快地解决。有关调试Conda安装的帮助,请参阅此Github问题。
conda create --name unsloth_env \
python=3.10 \
pytorch-cuda=<11.8/12.1> \
pytorch cudatoolkit xformers -c pytorch -c nvidia -c xformers \
-y
conda activate unsloth_env
pip install "unsloth[colab-new] @ git+https://github.com/unslothai/unsloth.git"
pip install --no-deps "trl<0.9.0" peft accelerate bitsandbytes
2、使用 Pip安装
如果你有蟒蛇,不要使用这个。你必须使用Conda安装方法,否则东西会坏掉。
1、通过以下方式查找您的CUDA版本
import torch; torch.version.cuda
2、对于Pytorch2.1.0:您可以通过Pip 更新 Pytorch(交换cu121/cu118)。转到https://pytorch.org/了解更多信息。
为CUDA 11.8选择cu118 或 为CUDA 12.1选择cu121。
如果您有RTX 3060或更高版本(A100、H100等),请使用"ampere"路径。
对于 Pytorch 2.1.1:转到步骤3。
对于Pytorch2.2.0:转到步骤4。
pip install --upgrade --force-reinstall --no-cache-dir torch==2.1.0 triton \
--index-url https://download.pytorch.org/whl/cu121
pip install "unsloth[cu118] @ git+https://github.com/unslothai/unsloth.git"
pip install "unsloth[cu121] @ git+https://github.com/unslothai/unsloth.git"
pip install "unsloth[cu118-ampere] @ git+https://github.com/unslothai/unsloth.git"
pip install "unsloth[cu121-ampere] @ git+https://github.com/unslothai/unsloth.git"
3、对于Pytorch2.1.1:将"ampere"路径用于较新的RTX 30xx GPU或更高版本。
pip install --upgrade --force-reinstall --no-cache-dir torch==2.1.1 triton \
--index-url https://download.pytorch.org/whl/cu121
pip install "unsloth[cu118-torch211] @ git+https://github.com/unslothai/unsloth.git"
pip install "unsloth[cu121-torch211] @ git+https://github.com/unslothai/unsloth.git"
pip install "unsloth[cu118-ampere-torch211] @ git+https://github.com/unslothai/unsloth.git"
pip install "unsloth[cu121-ampere-torch211] @ git+https://github.com/unslothai/unsloth.git"
4、对于Pytorch2.2.0:将"ampere"路径用于较新的RTX 30xx GPU或更高版本。
pip install --upgrade --force-reinstall --no-cache-dir torch==2.2.0 triton \
--index-url https://download.pytorch.org/whl/cu121
pip install "unsloth[cu118-torch220] @ git+https://github.com/unslothai/unsloth.git"
pip install "unsloth[cu121-torch220] @ git+https://github.com/unslothai/unsloth.git"
pip install "unsloth[cu118-ampere-torch220] @ git+https://github.com/unslothai/unsloth.git"
pip install "unsloth[cu121-ampere-torch220] @ git+https://github.com/unslothai/unsloth.git"
5、如果出现错误,请先尝试以下操作,然后返回步骤1:
pip install --upgrade pip
6、对于Pytorch2.2.1:
# RTX 3090, 4090 Ampere GPUs:
pip install "unsloth[colab-new] @ git+https://github.com/unslothai/unsloth.git"
pip install --no-deps packaging ninja einops flash-attn xformers trl peft accelerate bitsandbytes
# Pre Ampere RTX 2080, T4, GTX 1080 GPUs:
pip install "unsloth[colab-new] @ git+https://github.com/unslothai/unsloth.git"
pip install --no-deps xformers "trl<0.9.0" peft accelerate bitsandbytes
7、对于Pytorch2.3.0:将"ampere"路径用于较新的RTX 30xx GPU或更高版本。
pip install "unsloth[cu118-torch230] @ git+https://github.com/unslothai/unsloth.git"
pip install "unsloth[cu121-torch230] @ git+https://github.com/unslothai/unsloth.git"
pip install "unsloth[cu118-ampere-torch230] @ git+https://github.com/unslothai/unsloth.git"
pip install "unsloth[cu121-ampere-torch230] @ git+https://github.com/unslothai/unsloth.git"
8、要对安装进行故障排除,请尝试以下操作(所有操作都必须成功)。
nvcc
python -m xformers.info
python -m bitsandbytes
三、文档📜
- 转到我们的Wiki页面保存到GGUF,检查点,评估和更多!
- 我们支持Huggingface的TRL、Trainer、Seq2SeqTrainer甚至Pytorch代码!
- 我们在🤗拥抱脸的官方文档中!查看SFT文档和DPO文档!
from unsloth import FastLanguageModel
from unsloth import is_bfloat16_supported
import torch
from trl import SFTTrainer
from transformers import TrainingArguments
from datasets import load_dataset
max_seq_length = 2048 # Supports RoPE Scaling interally, so choose any!
# Get LAION dataset
url = "https://huggingface.co/datasets/laion/OIG/resolve/main/unified_chip2.jsonl"
dataset = load_dataset("json", data_files = {"train" : url}, split = "train")
# 4bit pre quantized models we support for 4x faster downloading + no OOMs.
fourbit_models = [
"unsloth/mistral-7b-v0.3-bnb-4bit", # New Mistral v3 2x faster!
"unsloth/mistral-7b-instruct-v0.3-bnb-4bit",
"unsloth/llama-3-8b-bnb-4bit", # Llama-3 15 trillion tokens model 2x faster!
"unsloth/llama-3-8b-Instruct-bnb-4bit",
"unsloth/llama-3-70b-bnb-4bit",
"unsloth/Phi-3-mini-4k-instruct", # Phi-3 2x faster!
"unsloth/Phi-3-medium-4k-instruct",
"unsloth/mistral-7b-bnb-4bit",
"unsloth/gemma-7b-bnb-4bit", # Gemma 2.2x faster!
] # More models at https://huggingface.co/unsloth
model, tokenizer = FastLanguageModel.from_pretrained(
model_name = "unsloth/llama-3-8b-bnb-4bit",
max_seq_length = max_seq_length,
dtype = None,
load_in_4bit = True,
)
# Do model patching and add fast LoRA weights
model = FastLanguageModel.get_peft_model(
model,
r = 16,
target_modules = ["q_proj", "k_proj", "v_proj", "o_proj",
"gate_proj", "up_proj", "down_proj",],
lora_alpha = 16,
lora_dropout = 0, # Supports any, but = 0 is optimized
bias = "none", # Supports any, but = "none" is optimized
# [NEW] "unsloth" uses 30% less VRAM, fits 2x larger batch sizes!
use_gradient_checkpointing = "unsloth", # True or "unsloth" for very long context
random_state = 3407,
max_seq_length = max_seq_length,
use_rslora = False, # We support rank stabilized LoRA
loftq_config = None, # And LoftQ
)
trainer = SFTTrainer(
model = model,
train_dataset = dataset,
dataset_text_field = "text",
max_seq_length = max_seq_length,
tokenizer = tokenizer,
args = TrainingArguments(
per_device_train_batch_size = 2,
gradient_accumulation_steps = 4,
warmup_steps = 10,
max_steps = 60,
fp16 = not is_bfloat16_supported(),
bf16 = is_bfloat16_supported(),
logging_steps = 1,
output_dir = "outputs",
optim = "adamw_8bit",
seed = 3407,
),
)
trainer.train()
# Go to https://github.com/unslothai/unsloth/wiki for advanced tips like
# (1) Saving to GGUF / merging to 16bit for vLLM
# (2) Continued training from a saved LoRA adapter
# (3) Adding an evaluation loop / OOMs
# (4) Customized chat templates
四、DPO支持
DPO(直接偏好优化)、PPO、奖励建模似乎都符合骆驼工厂的第三方独立测试。我们有一个初步的谷歌Colab笔记本,用于在特斯拉T4上复制Zephy r:笔记本。
我们在🤗拥抱脸的官方文档里!我们在SFT文档和DPO文档里!
from unsloth import FastLanguageModel, PatchDPOTrainer
from unsloth import is_bfloat16_supported
PatchDPOTrainer()
import torch
from transformers import TrainingArguments
from trl import DPOTrainer
model, tokenizer = FastLanguageModel.from_pretrained(
model_name = "unsloth/zephyr-sft-bnb-4bit",
max_seq_length = max_seq_length,
dtype = None,
load_in_4bit = True,
)
# Do model patching and add fast LoRA weights
model = FastLanguageModel.get_peft_model(
model,
r = 64,
target_modules = ["q_proj", "k_proj", "v_proj", "o_proj",
"gate_proj", "up_proj", "down_proj",],
lora_alpha = 64,
lora_dropout = 0, # Supports any, but = 0 is optimized
bias = "none", # Supports any, but = "none" is optimized
# [NEW] "unsloth" uses 30% less VRAM, fits 2x larger batch sizes!
use_gradient_checkpointing = "unsloth", # True or "unsloth" for very long context
random_state = 3407,
max_seq_length = max_seq_length,
)
dpo_trainer = DPOTrainer(
model = model,
ref_model = None,
args = TrainingArguments(
per_device_train_batch_size = 4,
gradient_accumulation_steps = 8,
warmup_ratio = 0.1,
num_train_epochs = 3,
fp16 = not is_bfloat16_supported(),
bf16 = is_bfloat16_supported(),
logging_steps = 1,
optim = "adamw_8bit",
seed = 42,
output_dir = "outputs",
),
beta = 0.1,
train_dataset = YOUR_DATASET_HERE,
# eval_dataset = YOUR_DATASET_HERE,
tokenizer = tokenizer,
max_length = 1024,
max_prompt_length = 512,
)
dpo_trainer.train()
伊织 + NMT
2024-07-12(五)