一、基础知识
自然语言处理:能够让计算理解人类的语言。
检测计算机是否智能化的方法:图灵测试
自然语言处理相关基础点:
基础点1——词表示问题:
1、词表示:把自然语言中最基本的语言单位——词,将它转换成我们机器可以理解的对应词的意思。(即让机器理解这个词是什么意思)
2.词表示的目标:
计算词的相识度;
找出词和词的语义关系;
3.词表示方法的演变过程:
①使用词的近义词或与这个词有关的词表示这个词; (缺点:表示这个词的相关,实际上是有细微差异的,可能会错失一些新的词义,存在主观性)
②目前最常用的方案:将每个词表示为一个独立的符号,这种方法叫做:one-hot representation。(缺点:内存需求会随着词表增大而变大,词义的表示会依赖于词表出现频率)
③建立一个低维的稠密的空间,将每一个词学到这个空间里面,用空间里面的位置所对应的那个向量表示这个词。代表性的方法:word2vec
自然语言处理基础点2——语言模型(language model)
语言模型目的:语言模型其实就是要去能有能力根据前文去预测下一个词的能力。
语言模型主要完成的两个工作: (1)能够计算一个序列的词,它成为一句话的概率到底是什么。(比如:给出多个中文汉字,根据这些汉字出现的顺序组成一句合法的中文语句的概率)
(2)根据前面已经说的话,预测出下一个词是什么。
怎么实现根据前文预测下一个?
原理:一个词出现的概率是只受到它前面出现的这些词的影响。计算公式是:联合概率=累乘(条件概率)
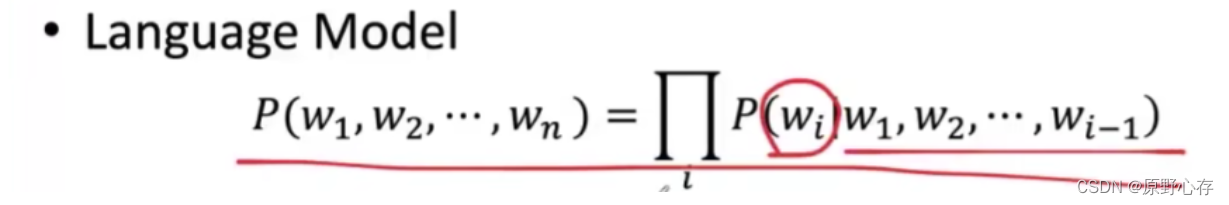
构建语言模型的方法:
过去的方法是:N-gram——前面出现了几个词之后,后面出现的那个词他的频度到底是怎么样的。(原理:马尔科夫假设; 缺点:无法理解相似的词造成什么)
现在的方法是:Neural Language Model——将每个词表示成低维向量,则词性相似对应的向量相似,就可以推出在语境中可能有相似的作用。