系列文章目录
前言
Dynamically Weighted Balanced Loss: ClassImbalanced Learning and Confidence Calibration of Deep Neural Networks
下载地址:DOI: 10.1109/tnnls.2020.3047335
一、研究目的
解决深度学习中的类分布不平衡问题,提出了一种基于类平衡动态加权损失函数的类再平衡策略,其中权重是根据类频率和地面真实类的预测概率分配的。动态加权方案根据预测分数自适应其权重的能力允许模型调整具有不同难度的实例,从而导致由硬少数类样本驱动的梯度更新。在网络入侵检测(CICIDS2017数据集)和医学成像(ISIC2019数据集)的不同应用中对高度不平衡的数据进行的实验显示出强大的泛化能力。支持上级经验性能的理论结果提供了理由的有效性,建议动态加权平衡(DWB)损失函数。
二、研究方法
我们提出了一种动态策略来分配类权重,重点放在难以训练的实例上,并提出了一种称为动态加权平衡(DWB)损失的新型损失函数,该损失函数能够自然处理类不平衡,同时还可以提高校准性能。为了说明所提出的方法的一般性,在网络入侵检测和皮肤病变诊断中具有挑战性的现实应用进行了实验。
创新点
分配的权重不是固定的权重方案,而是根据数据实例的预测难度自适应其规模;我们将类别不平衡和置信度估计的可靠性联系起来。据我们所知,以前的研究还没有解决这两个问题在一个统一的方法在DL的上下文中。
因此,本文提出了以下主要创新:
1)基于类再平衡策略的可微分损失公式,其中权重在训练过程中动态变化,
2)允许学习已经良好校准的模型的框架,从而同时解决DNN中的类不平衡和类成员概率的可靠性。
处理类不平衡的大多数方法
处理类不平衡的大多数方法可以分为两类:数据级方法和算法级方法。
数据级方法:通过采用重新分配策略来平衡数据集,从而改变原始数据中的类分布。
- 随机过采样:复制少数类中的实例来处理类不平衡,从而增加少数类。
- 随机欠采样: 随机删除多数类中的实例以匹配少数类的基数。
- 抽样方法来人工平衡数据。
过采样可能会导致过拟合,并可能加重计算负担,而欠采样可能会消除有用的信息,
算法级方法:算法级方法涉及调整分类器,并可进一步分为集成方法和成本敏感方法。
- 集成方法:最广泛使用的方法包括bagging和boosting基于集成的方法。
- 代价敏感学习:重新缩放数据,通过为不同类别的训练示例分配不同的权重(重新加权),重新分配训练实例,或基于其误分类成本移动决策阈值来执行
不同于以前的方法,需要手工制作的成本矩阵,分配固定的权重,或涉及算法修改,我们提出了一个损失函数,其中包含在训练过程中调整的动态加权因子,以解决不平衡数据的训练偏差,这也会导致校准良好的置信度估计。它不需要任何额外的超参数调优,可以迅速应用于任何DNN架构。
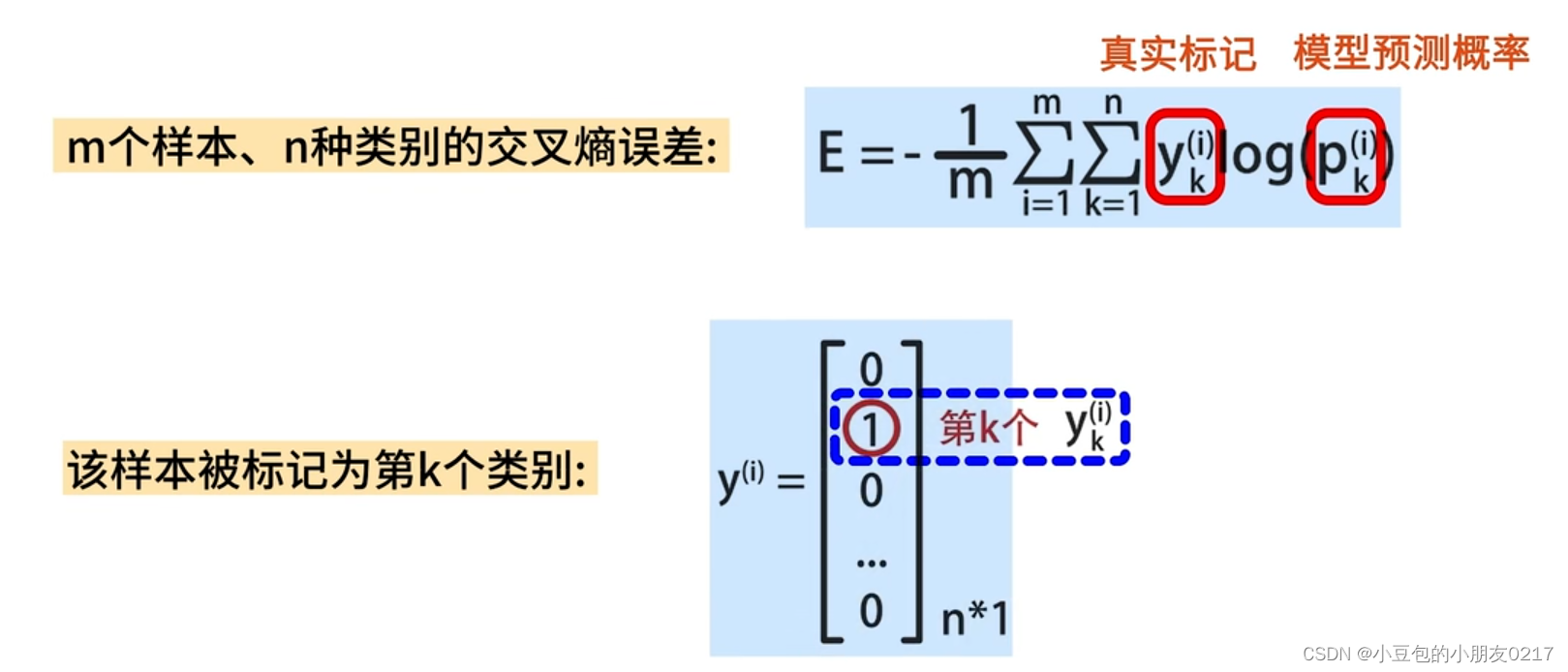
交叉熵损失函数


Brier Score
用于衡量概率校准的一种评价函数。
包含了三部分:均方误差(mean squared error, MSE)、方差(variance)和熵(entropy)
三、DWB Loss
DWB Loss 结合了动态加权的交叉熵损失项和正则化组件,以及对类别权重的灵活设置,旨在更好地处理严重倾斜的类别分布,使得模型能够更好地适应不平衡的情况,并获得更好的训练效果。
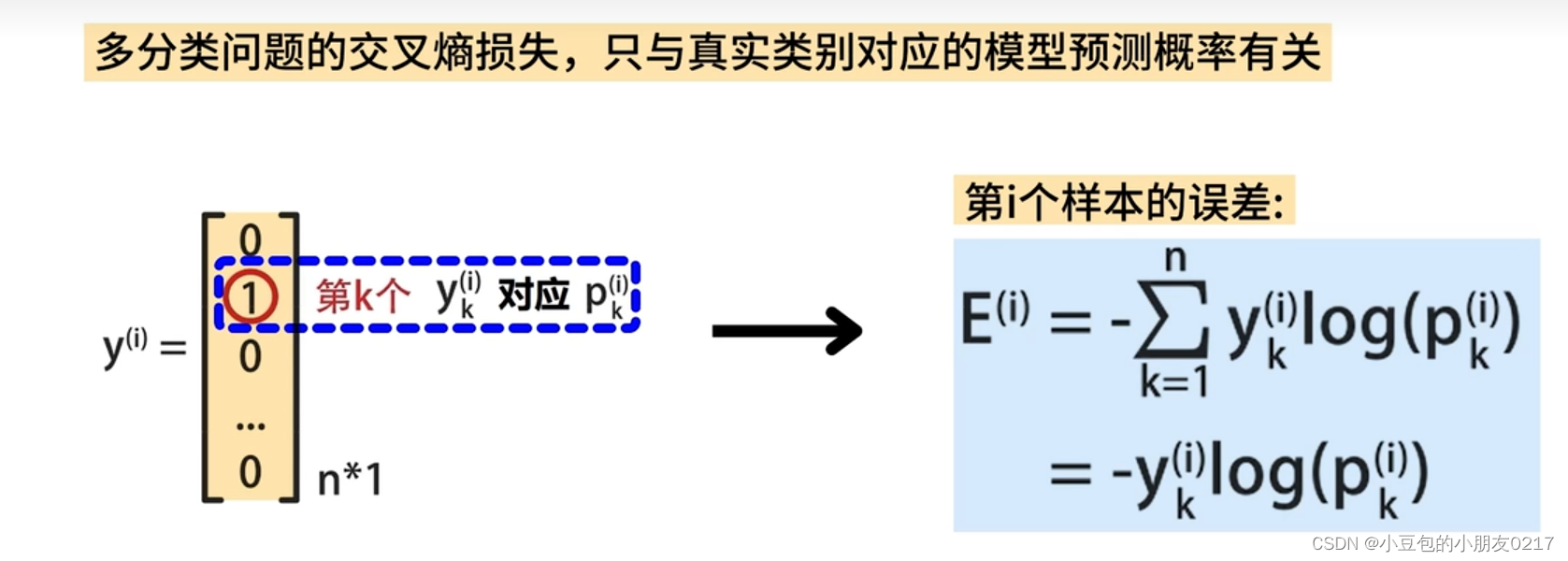
引入了一个基于动态加权的分类器目标函数,该目标函数基于地面真值类的预测概率,为难以训练的实例分配更高的权重,我们称之为DWB损失。为方便起见,设fj(Xi ; θ)用pij表示。因此,pij是实例Xi的类j的预测概率。
所提出的损失函数由两个项组成:动态加权CE和等于Brier评分(BS)熵的正则化分量,其可以被认为是导致更好校准的可靠性分量。

- ( n ) 是训练样本的数量
- ( c ) 是类别的数量
- ( w_j ) 是类别 ( j ) 的权重
- ( p_{ij} ) 是样本 ( i ) 属于类别 ( j ) 的预测概率
- ( y_{ij} ) 是样本 ( i ) 的标签,使用了 one-hot 编码
第一项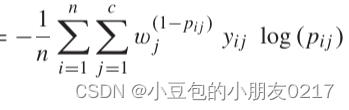
交叉熵损失项,其中 yij log(pij)表示模型对类别 (j) 的预测与实际标签的交叉熵损失,乘以 (w_j (1-p_{ij})) 来调整权重,使得难以分类的样本获得更高的权重。
第二项
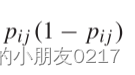
是正则化组件,它等于 Brier score 的熵,用于提高模型的校准性能。
类权重wj可以被处理为通过交叉验证从数据中学习的超参数,或者与类频率的倒数成比例地设置。我们设置wj等于多数类的类频率和类频率nj(在训练数据集上计算)的对数比,如下所示:
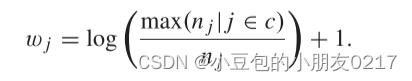
类别权重设置:
类别权重 (w_j) 可以根据实际情况进行设置,文中提到的一种设置方法是将 (w_j) 设为最多类别的频率与类别 (j) 的频率的对数比例加1。这样,对于具有 (w_j) 类别代价的类别 (j),其分类错误将比具有权重为1的多数类别的错误受到 (w_j) 倍的惩罚。
总体来说,DWB Loss 结合了动态加权的交叉熵损失项和正则化组件,以及对类别权重的灵活设置,旨在更好地处理严重倾斜的类别分布,使得模型能够更好地适应不平衡的情况,并获得更好的训练效果。
总结
DWB损失函数通过动态加权的方式,更注重难以训练的实例,从而提高模型在类别不平衡和难易样本实例方面的性能表现。

![[机器<span style='color:red;'>学习</span>] Stable Diffusion初体验——基于<span style='color:red;'>深度</span><span style='color:red;'>学习</span>通过<span style='color:red;'>神经</span><span style='color:red;'>网络</span><span style='color:red;'>的</span>强大AI<span style='color:red;'>平台</span>](https://img-blog.csdnimg.cn/direct/6380a455313e4ce987b4c7e44e9041c5.png)