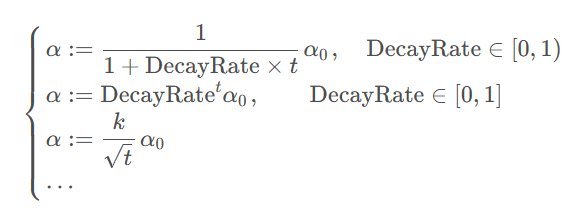文章目录
1 神经网络的编程基础
1.1 二分分类
Logistic回归是一个用于二分分类的算法
计算机保存一张图片,要保存三个独立的矩阵,分别对应图片中的红绿黄三种像素的亮度。要把这些像素亮度值放入一个特征向量中,就要把这些像素值都提出来放入一个特征向量x。
如果图片是64×64的,那么向量x的总维度是64×64×3,因为这是三个矩阵的元素数量。即用其来表示输入特征向量的维度。
二分分类的目标是为了训练出一个分类器,它以图片的特征向量x作为输入,预测输出的结果标签y是1还是0,表示这张图片上是否存在目标物体。
训练样本作为行向量堆叠,而不是列向量堆叠。

1.2 Logistic回归

相当于sigmoid,如果z趋于无穷大,那么z的sigmoid函数得到的结果是1,如果z趋于负无穷大,那么z的sigmoid函数得到的结果是0.
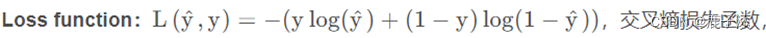
当y=1时,则L(y冒,y)=-log(y帽),则此时y帽要尽可能得大,那么损失函数才能尽可能的小,因此y帽趋近于1
当y=0时,L(y帽,y)=log(1-y帽),则此时y帽要尽可能得小,那么损失函数才能尽可能的小,因此y帽趋近于0。
所有样本的损失函数的平均值:
1.3 梯度下降法

1.4 导数运算
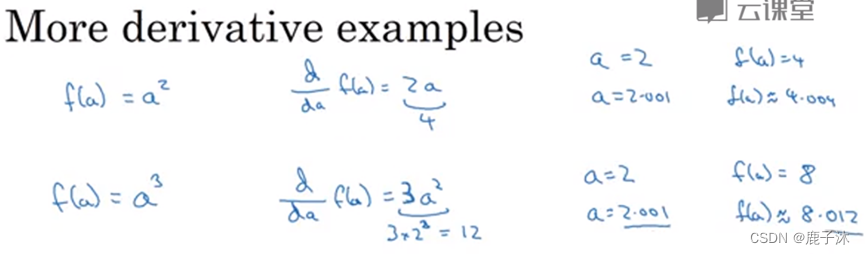
a3:由于a=2,则其导数为12,即其斜率为12,则当a=2.001时,f(a)约等于8.012。
函数的导数就是函数的斜率。
函数的斜率在不同的点是不同的。
计算的流程图:
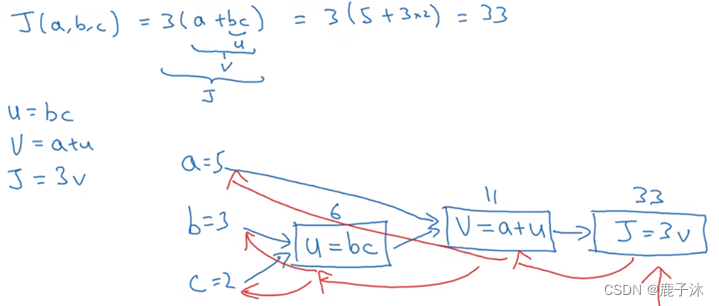
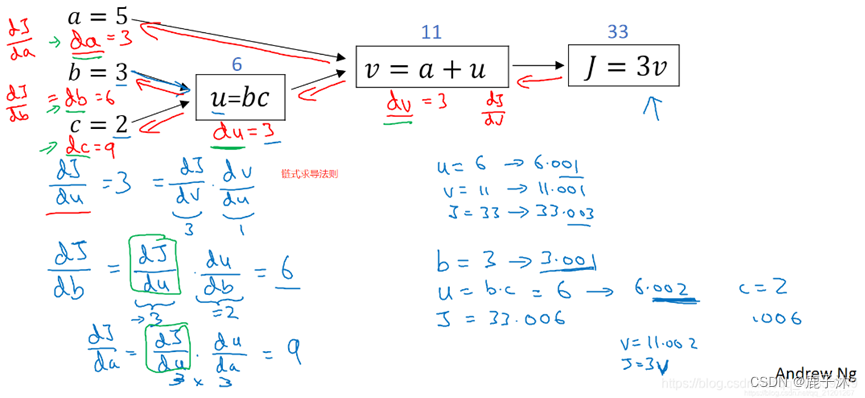
正向为正向传播。反向为反向传播。
1.5 logistic回归中的梯度下降法
单个样本实例的一次梯度更新步骤:

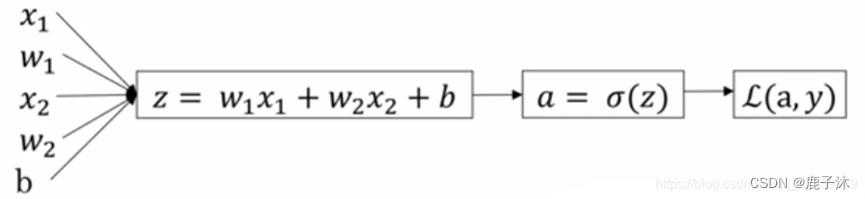
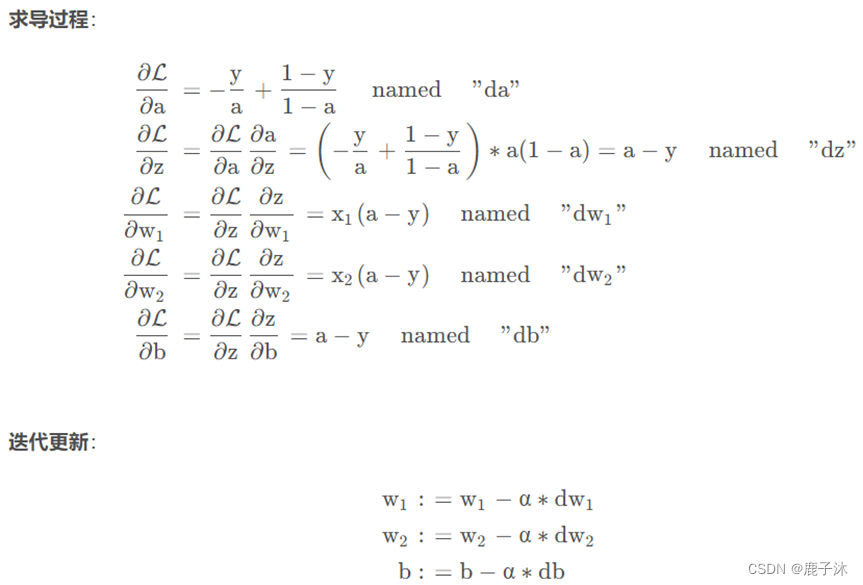
应用到m个样本,需要编写两个for循环,第一个for循环是遍历m个训练样本的小循环,第二个for循环是遍历所有特征的循环。由于这个例子中只有两个特征,因此只有dw1及dw2,如果还有更多特征则继续写下去。
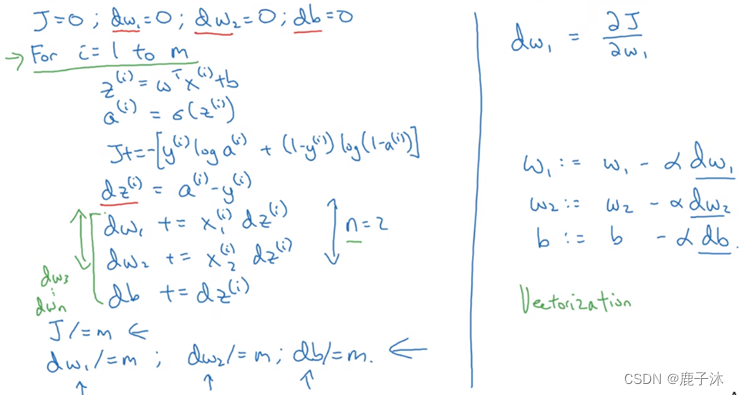
即
J=0; dw1=0; dw2=0; db=0;
for i = 1 to m
z(i) = wx(i)+b;
a(i) = sigmoid(z(i));
J += -[y(i)log(a(i))+(1-y(i))log(1-a(i))];
dz(i) = a(i)-y(i);
dw1 += x1(i)dz(i); // 全部样本的梯度累加
dw2 += x2(i)dz(i);
db += dz(i);
// 求平均值
J /= m;
dw1 /= m;
dw2 /= m;
db /= m;
// 更新参数 w, b
w = w - alpha*dw
b = b - alpha*db
1.6 向量化
向量化可以加快计算的速度。
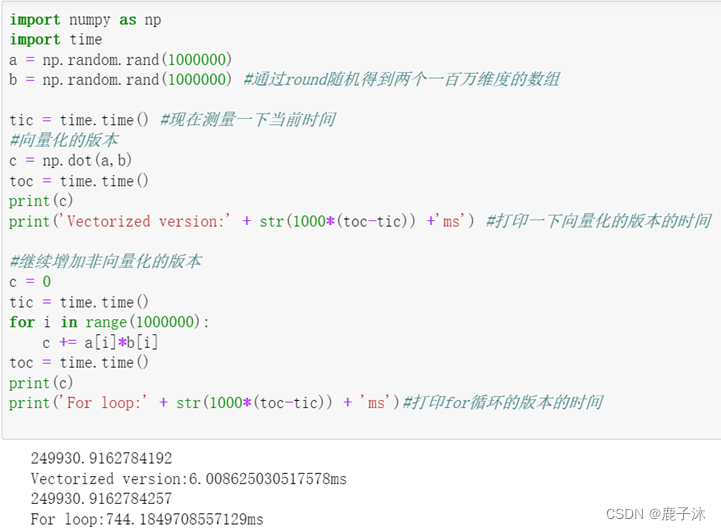
将两个循环简化为一个循环:dw += x(i)dz(i) 表示向量化,全部样本的梯度相加。


完成逻辑回归的一次迭代,那么则可以将两个循环都省略掉。

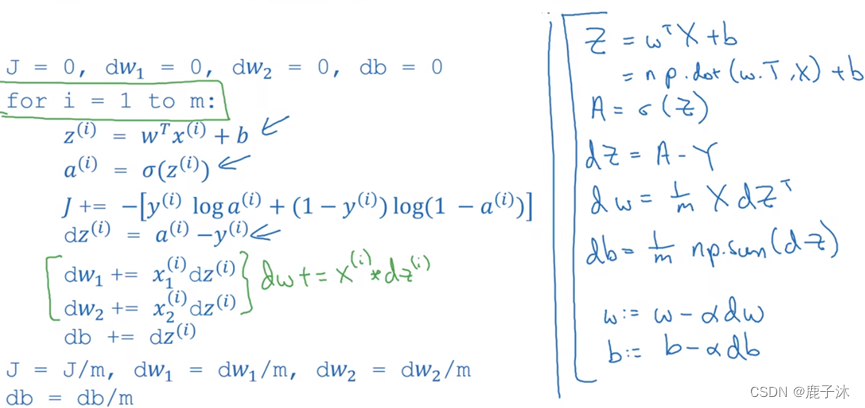
1.7 广播机制
axis指明运算沿着哪个轴执行,在numpy中,0轴是垂直的,也就是列,而1轴是水平的,也就是行。


注:广播机制与执行的运算种类无关
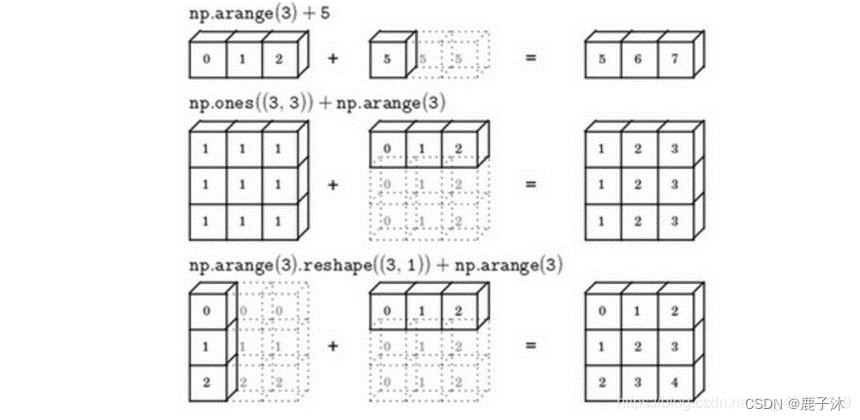
关于python_numpy向量的说明

总是使用n1维矩阵(列向量),或者1n维矩阵(行向量),要经常使用reshape操作来确保所需要的维数。
2 浅层神经网络
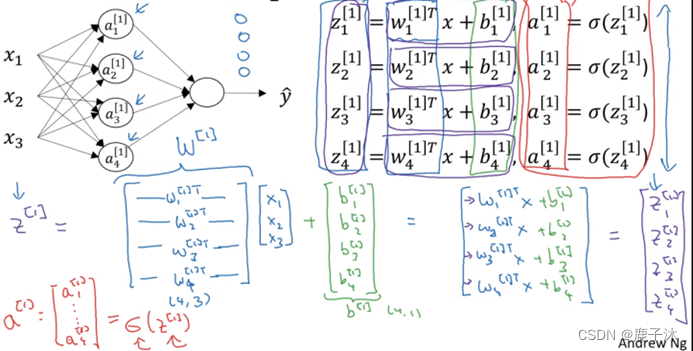
2.1 神经网络的输出
上标括号内表示层数,下标表示层中的第几个节点

看的是第一隐层中的第一个节点
2.2 多个样本的向量化
圆括号里的i指的是训练样本i
方括号指的是第二层
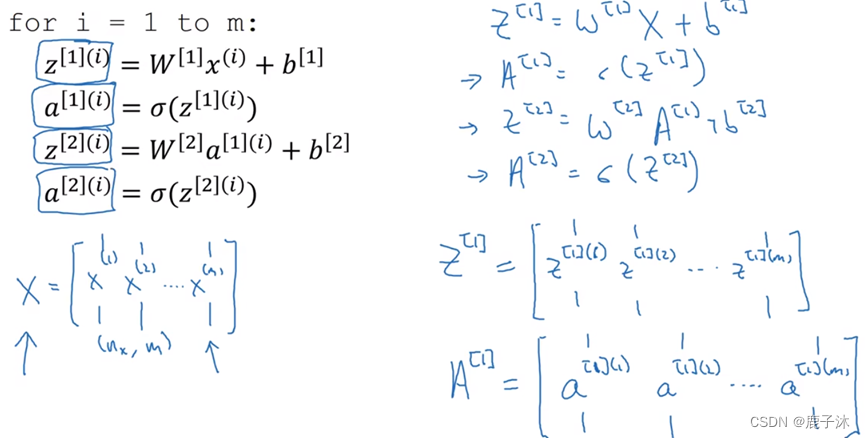
2.3 激活函数
Sigmoid函数除非用在二元分类的输出层,不然绝对不要用。
Tanh函数在所有情况几乎都很优越
最常用的默认激活函数是ReLU
带泄露的ReLu函数中可以把0.01设成学习函数的另一个参数。
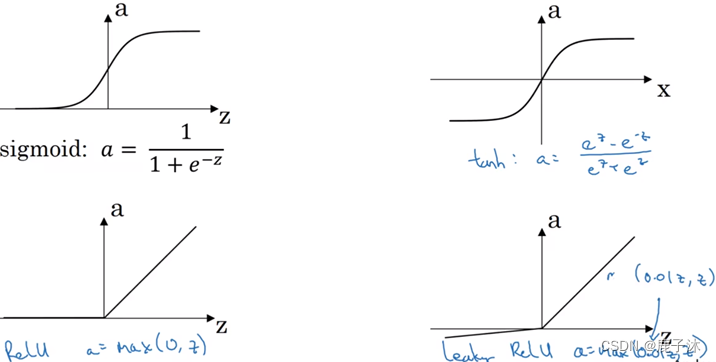
2.4 激活函数的导数
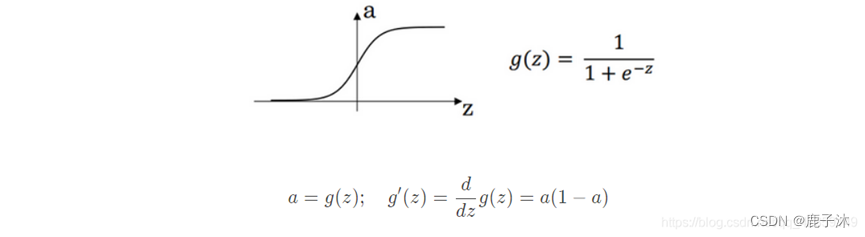
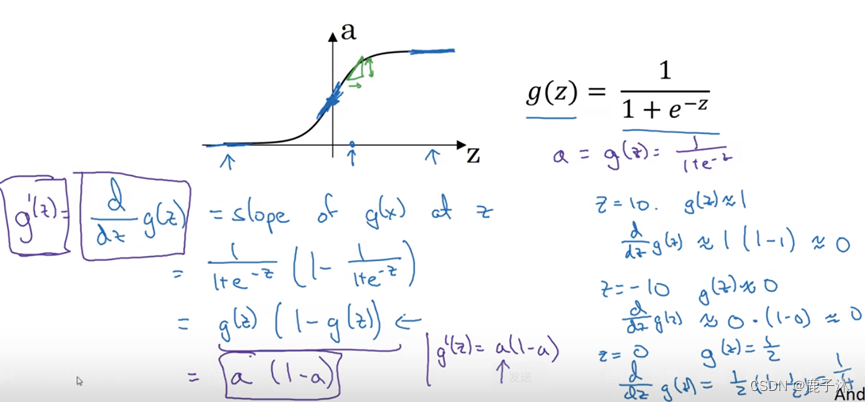
对g(Z)求导,当z=正无穷大时,导数为0,为负无穷大导数也为0。
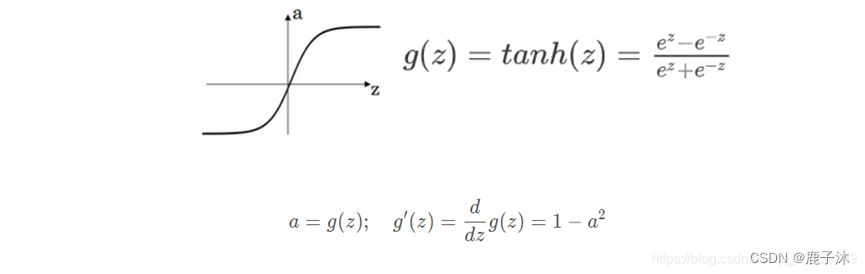
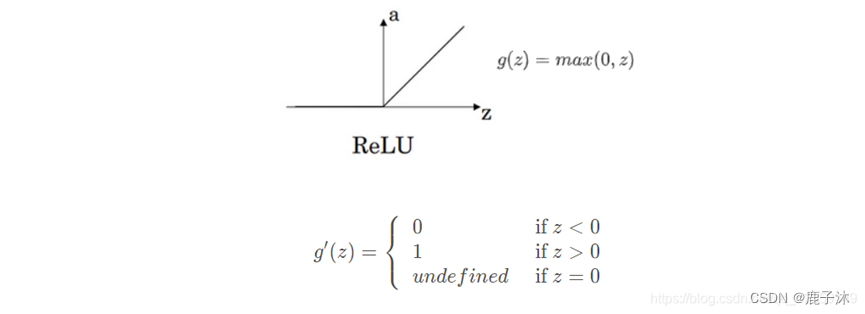
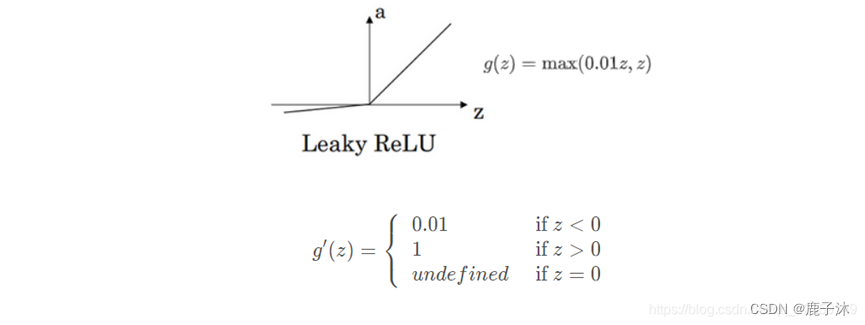
但在实际中,在0处的导数可以取0或者取1.
2.5 神经网络的梯度下降法<反向传播>

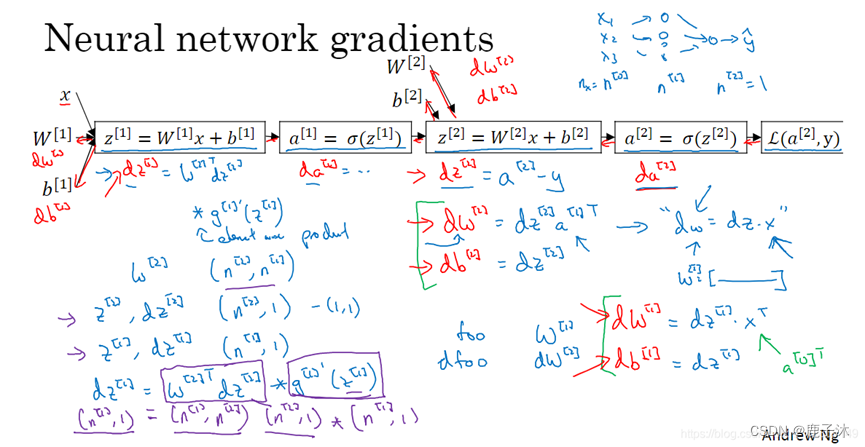

左边是梯度下降,右边是向量化
3 深层神经网络
3.1 核对矩阵的维数

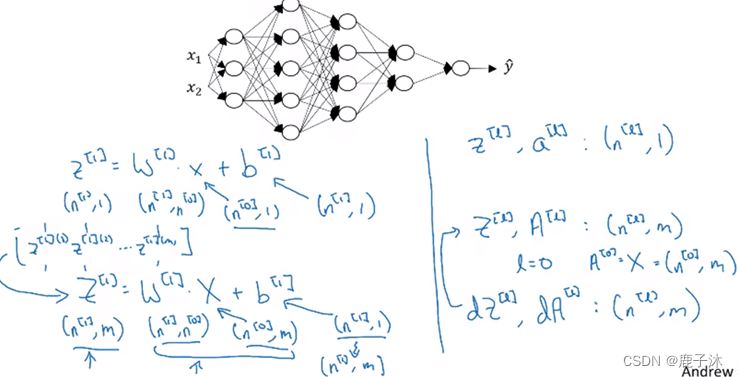
3.2 搭建深层神经网络块
正向传播的过程中缓存了所有的z值
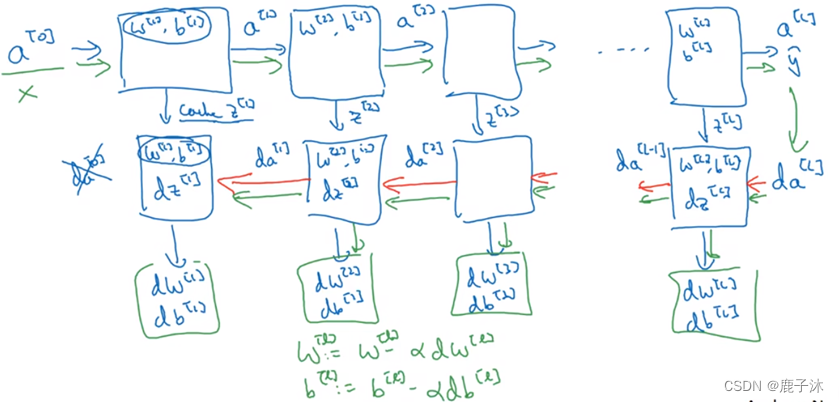
反向传播过程中也可以计算出输出值即da[0]其实就是输入特征的导数,并不重要
神经网络的一步训练包含了也就是x经过了一系列正向传播得到了y帽,之后再用输出值计算da[l],再实现反向传播。这就是神经网络一个下降梯度循环。
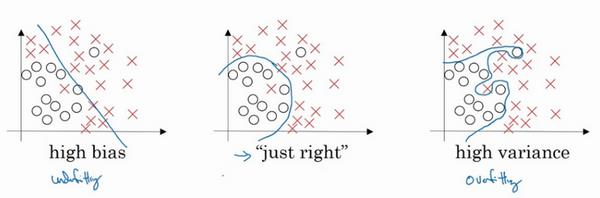
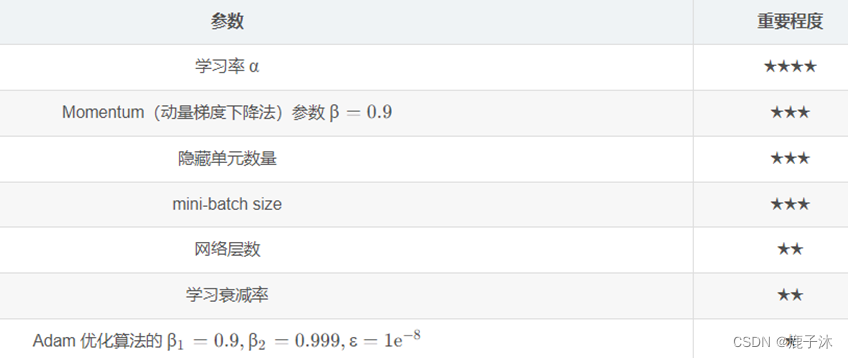
3.3 参数与超参数
参数:模型可以根据数据可以自动学习出的变量,应该就是参数。比如,深度学习的权重w,偏差b等。
超参数:就是用来确定模型的一些参数,超参数不同,模型是不同的,超参数一般就是根据经验确定的变量。在深度学习中,超参数有:学习速率α,梯度下降的迭代次数,隐藏层数量,隐藏层单元数量以及激活函数选择等等。即这些超参数可以决定参数的取值。
正反向传播: