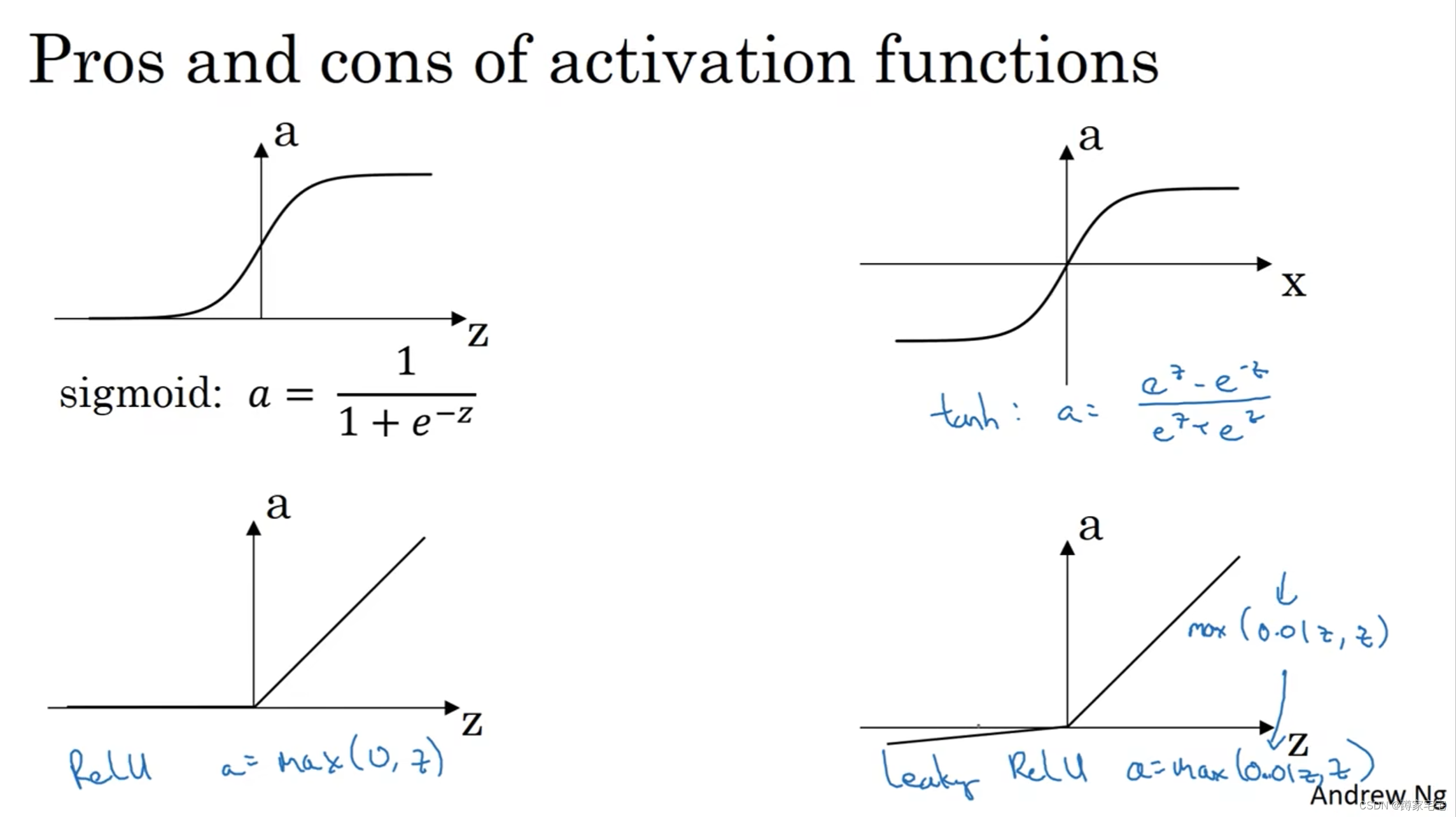
指数加权移动平均(exponentially weighted moving averages)
如何对杂乱的数据进行拟合?
通过指数加权平均可以把数据图近似拟合成一条曲线

公式:
其中
表示第t个平均数,
表示第t-1个平均数,
表示第t个数据,
表示变化参数
下图为拟合结果()
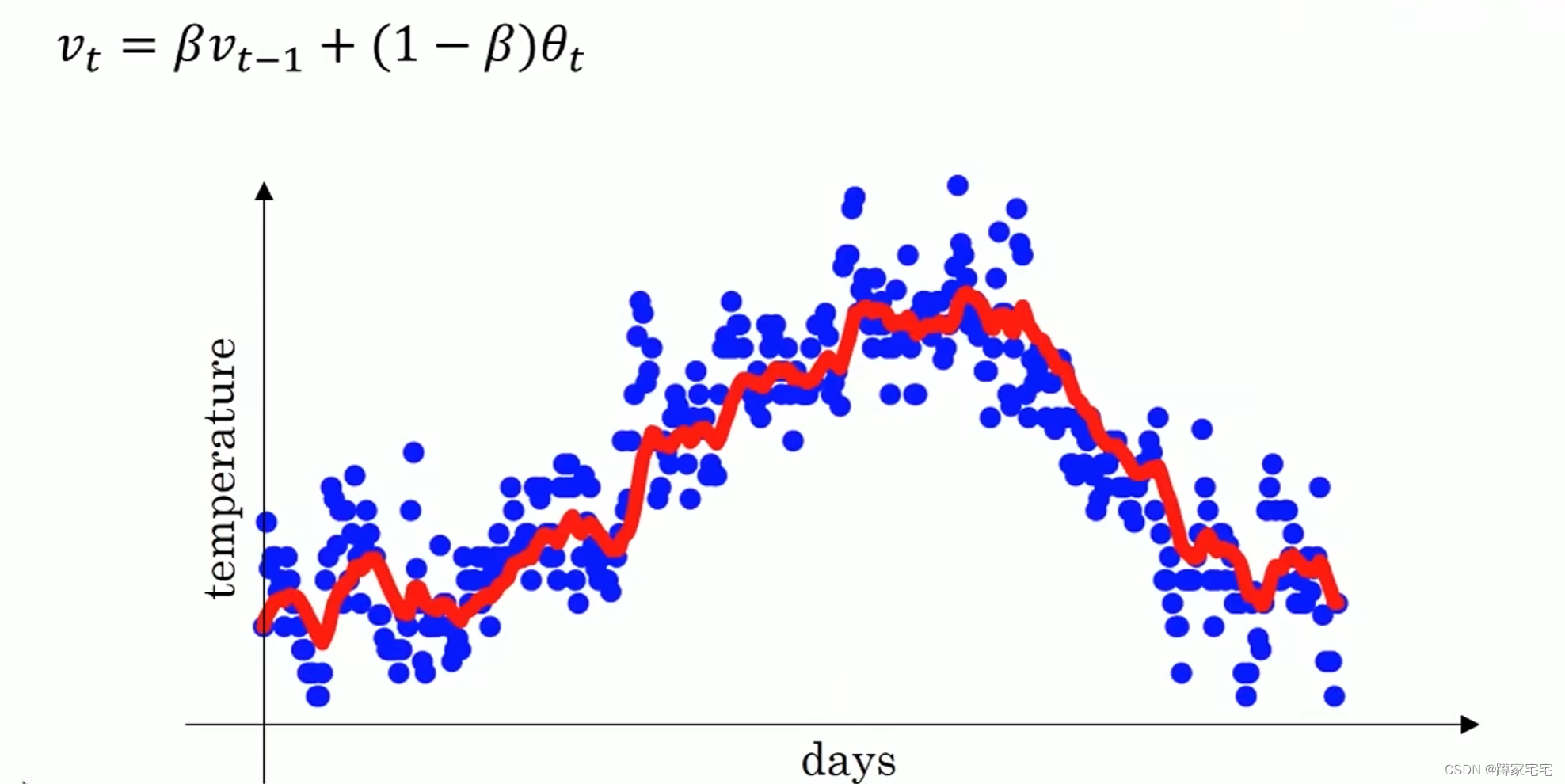
当参数
例子:
时,近似取10个数据平均值(红色曲线)
时,近似取50个数据平均值(绿色曲线)
时,近似取2个数据平均值(黄色曲线)
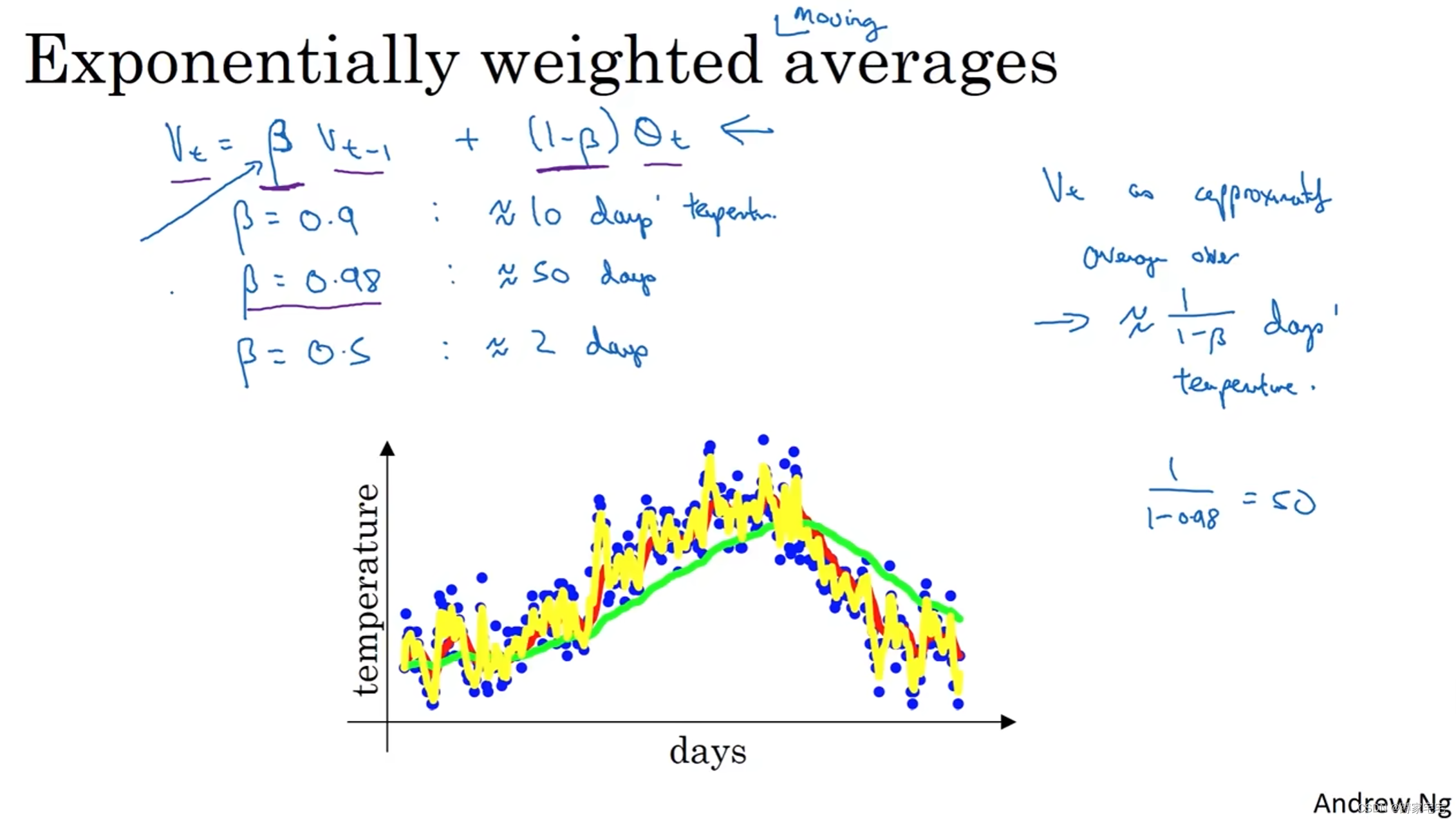
从上图三条曲线可知
参数
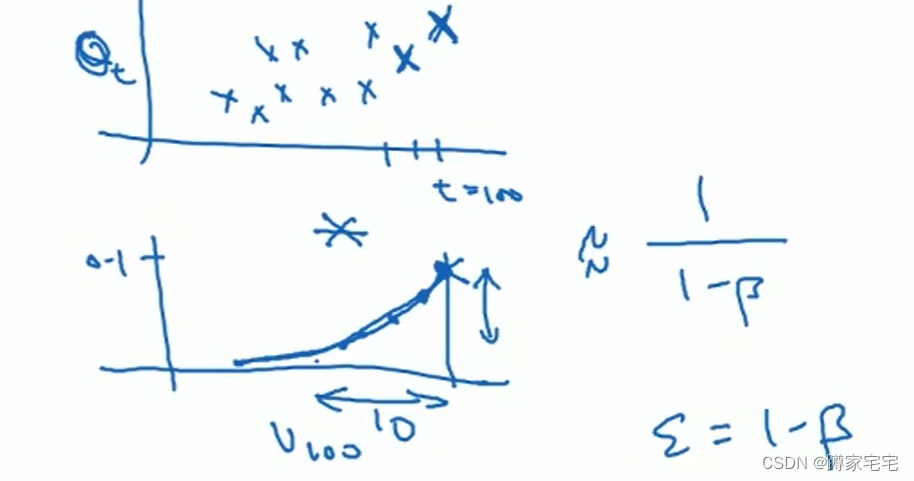
公式:
这个公式可以用来计算采样数据的数量
当
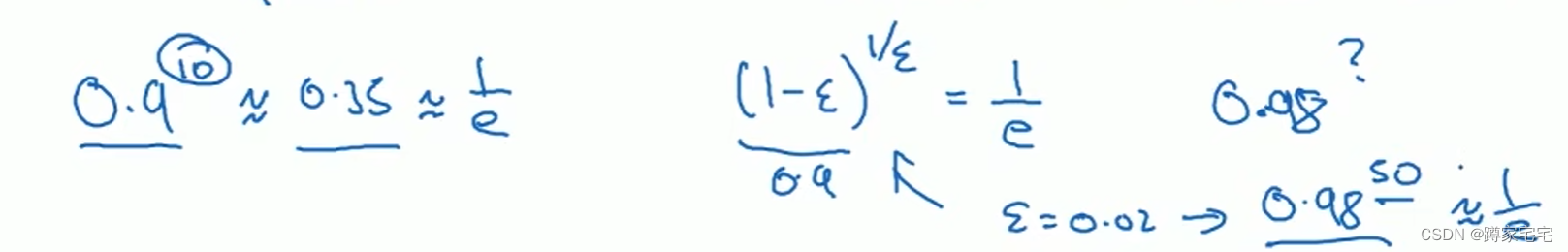
优点:
减少内存占用,只需一行代码实现重复更新
v=0
beta=0.9
theta=[1,2,4,5,6,8,10,14,18,22]
# theta[i]代表当前数据
for i in range(0,10):
v=beta*v+(1-beta)*theta[i]
print("v",i+1," = ",v)
偏差修正(bias correction)
当较大时,初期数据拟合可能偏差较大,为了更好地拟合初期的数据,故采用偏差修正
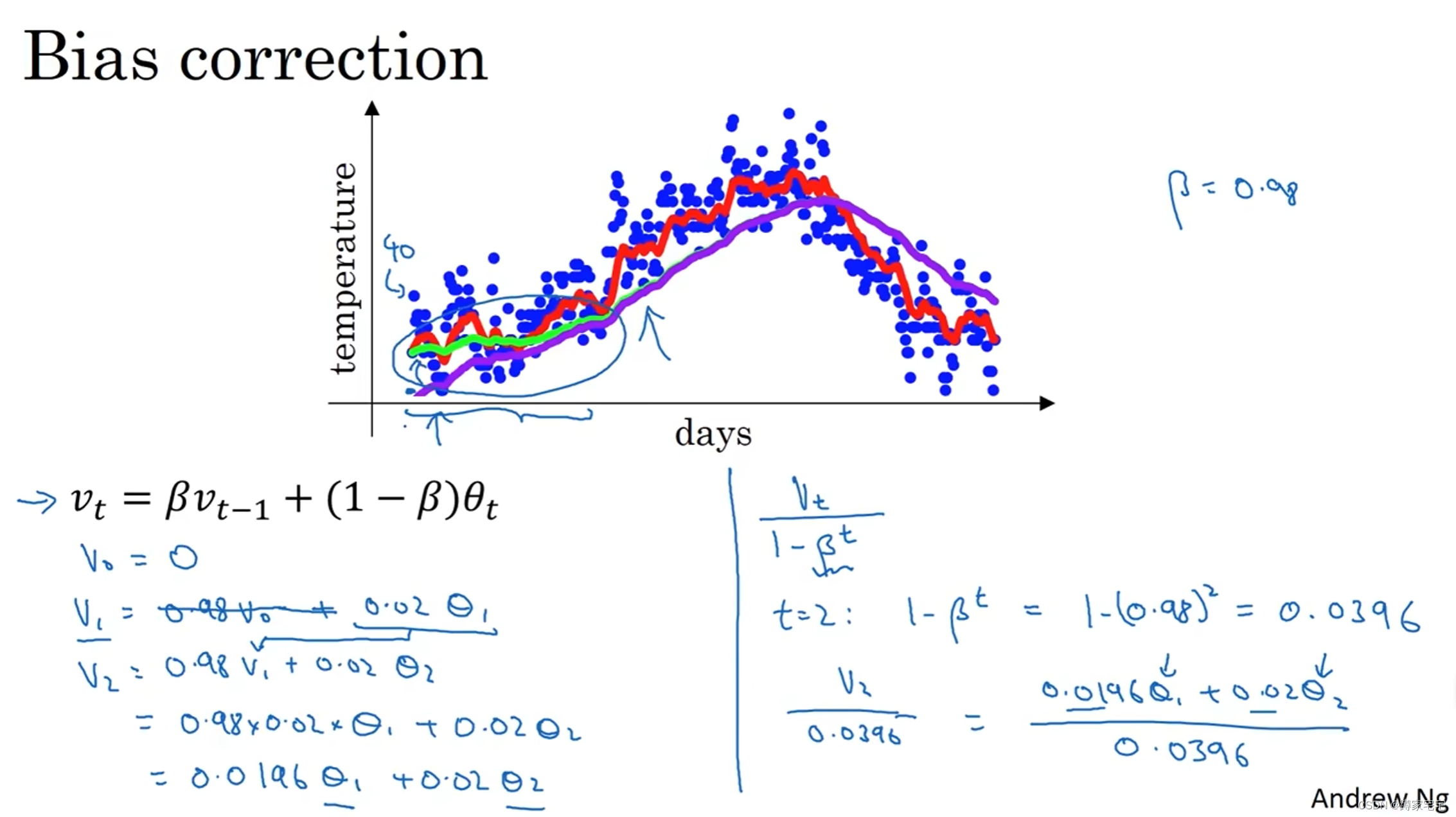
所得到的v值进行进一步的处理:
,其中t为天数
故当t较小时,可以被适当放大,更加拟合数据
当t变大,分母逐渐趋于1,所以后阶段偏差修正作用不大
总而言之,偏差修正是一种针对初期数据的修正偏差的方法