Spark系列文章:
大数据 - Spark系列《一》- 从Hadoop到Spark:大数据计算引擎的演进-CSDN博客
大数据 - Spark系列《二》- 关于Spark在Idea中的一些常用配置-CSDN博客
大数据 - Spark系列《三》- 加载各种数据源创建RDD-CSDN博客
大数据 - Spark系列《四》- Spark分布式运行原理-CSDN博客
大数据 - Spark系列《五》- Spark常用算子-CSDN博客
大数据 - Spark系列《六》- RDD详解-CSDN博客
大数据 - Spark系列《七》- 分区器详解-CSDN博客
大数据 - Spark系列《十》- rdd缓存详解-CSDN博客
大数据 - Spark系列《十一》- Spark累加器详解-CSDN博客
目录
5. 🧀spark的coalesce和repartition的区别
1. 🥙Task(任务描述)和Task实例(真正运行)
Task(任务描述)指的是由Driver程序发送给Executor程序的逻辑单元,用于执行作业中的某个阶段。
Task实例(任务实例)是指Executor上真正运行的任务,它们根据Task描述执行相应的计算逻辑。
每个Task实例在Executor上运行时,会按照Task描述中的逻辑,处理相应的数据分区,并且执行对应的计算操作。一个Task描述可以有多个Task实例并行执行,每个Task实例独立处理数据分区,最终将计算结果返回给Driver程序。
Task在spark内部共有2种: shuffleMapTask 和 resultTask
最后一个stage所产生的task,是resultTask , 最后后一个阶段为ResultStage
其他stage所产生的task,都属于shuffleMapTask , 其他的阶段为ShuffleMapStage
2. 🥙Stage(阶段)
以shuffle为分界线,将DAG转换逻辑从整体划分成段,每一段就称之为一个Stage
一个阶段对应一个TaskSet
task任务的个数和阶段的最后一个rdd的分区数一致
3.🥙TaskSet和Task
一个阶段对应一个TaskSet
最后一个rdd有四个分区,则会创建4个task实例。这4个task实例会放在这个TaskSet里面。
Task: 执行计算的任务单元
4. 🥙DAG
DAG(Directed Acyclic Graph)叫做有向无环图,是的一系列RDD转换关系的描述,阶段的描述

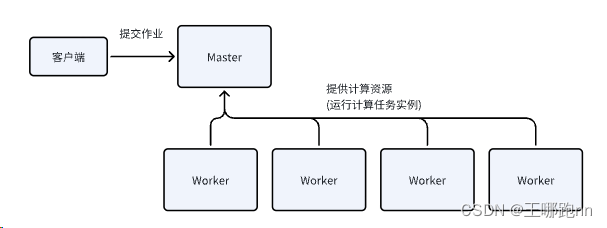
5. 🥙Driver端
提交程序的客户端
初始化作业的客户端(阶段的划分,DAG的创建,任务的创建,任务的调度都是在Driver端执行的)

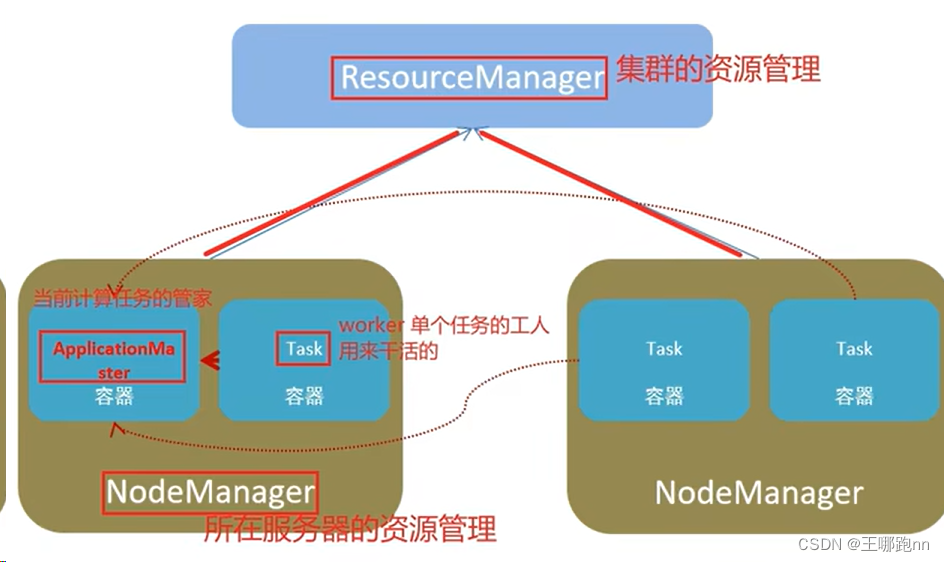
6. 🥙Executor
执行具体Task的远程端口
7.🥙job
具体的任务作业
一个行动算子就触发了一个job(此说法:直观但不精确)
有些行动算子,可能触发多个job,比如take( ) ;
有些transformation算子,也可能会触发job,比如sortByKey()算子[因为它要用rangepartitioner]
一个job就是一个dag的运算流程(触发了一次sc.runJob() 就是一次job)

8.🥙Application(应用)
创建一个sparkContext,就生成了一个application
目前Spark系列文章已经更新到第十二篇,Spark第二阶段学习也已经完成。对此,特对知识点做了一个汇总如下
对于第一阶段面试题的整理可参考如下链接:
大数据 - Spark系列《四》- Spark分布式运行原理_spark的哪些操作是分布式并行的,哪些是串行的,如何知道-CSDN博客
?Spark面试题总结:
1. 🧀什么是闭包引用?
算子使用了一个算子外的变量,这就是闭包引用
2. 🧀什么是广播变量?
它是spark共享数据的一种机制,它会在整个集群中缓存一份数据,每个节点去复制一份,不需要在每个task实例中创建数据对象,从而提升数据的传输效率。
3. 🧀什么是累加器?
它是一个全局的共享可写变量。它可以在每一个任务实例中进行计数,然后进行汇总,最后输出在driver端
4. 🧀有哪些常见的分区器?
常见的分区器包括HashPartitioner和RangePartitioner等。
5. 🧀spark的coalesce和repartition的区别
repartition一般用于增加rdd的分区数量,它通过shuffle对数据重新进行分区
coalesce一般用于减少rdd的分区数量,它可以在不触发shuffle的情况下,将数据从多个分区合并成较少的分区。
6. 🧀spark的cache和persist的区别
cache():
cache()是RDD的一个方法,用于将RDD缓存到内存中。它是persist()方法的一种特殊情况,使用默认的存储级别MEMORY_ONLY。
cache()方法是一个懒加载操作,调用后并不会立即触发计算,而是等到第一次调用action操作时才会执行。
persist():
persist()方法是RDD的通用持久化方法,它允许指定不同的存储级别(如MEMORY_ONLY、MEMORY_AND_DISK、MEMORY_ONLY_SER等)。
与cache()方法不同,persist()方法是一个动作,调用后会立即触发计算,并将计算结果持久化到指定的存储级别。
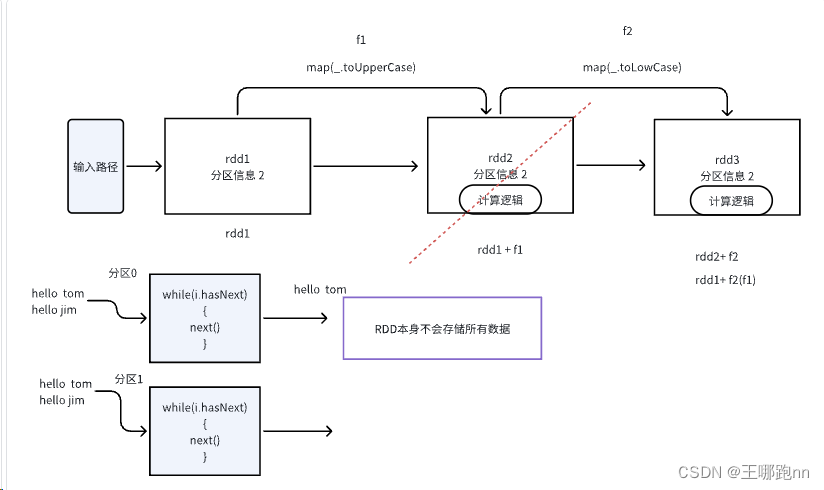
7. 🧀说一下宽依赖和窄依赖
窄依赖
上游RDD的任意一个分区的数据只会被下游某一个分区引用
宽依赖
会产生shuffle,上游RDD的任意一个分区的数据可能会被下游所有分区引用