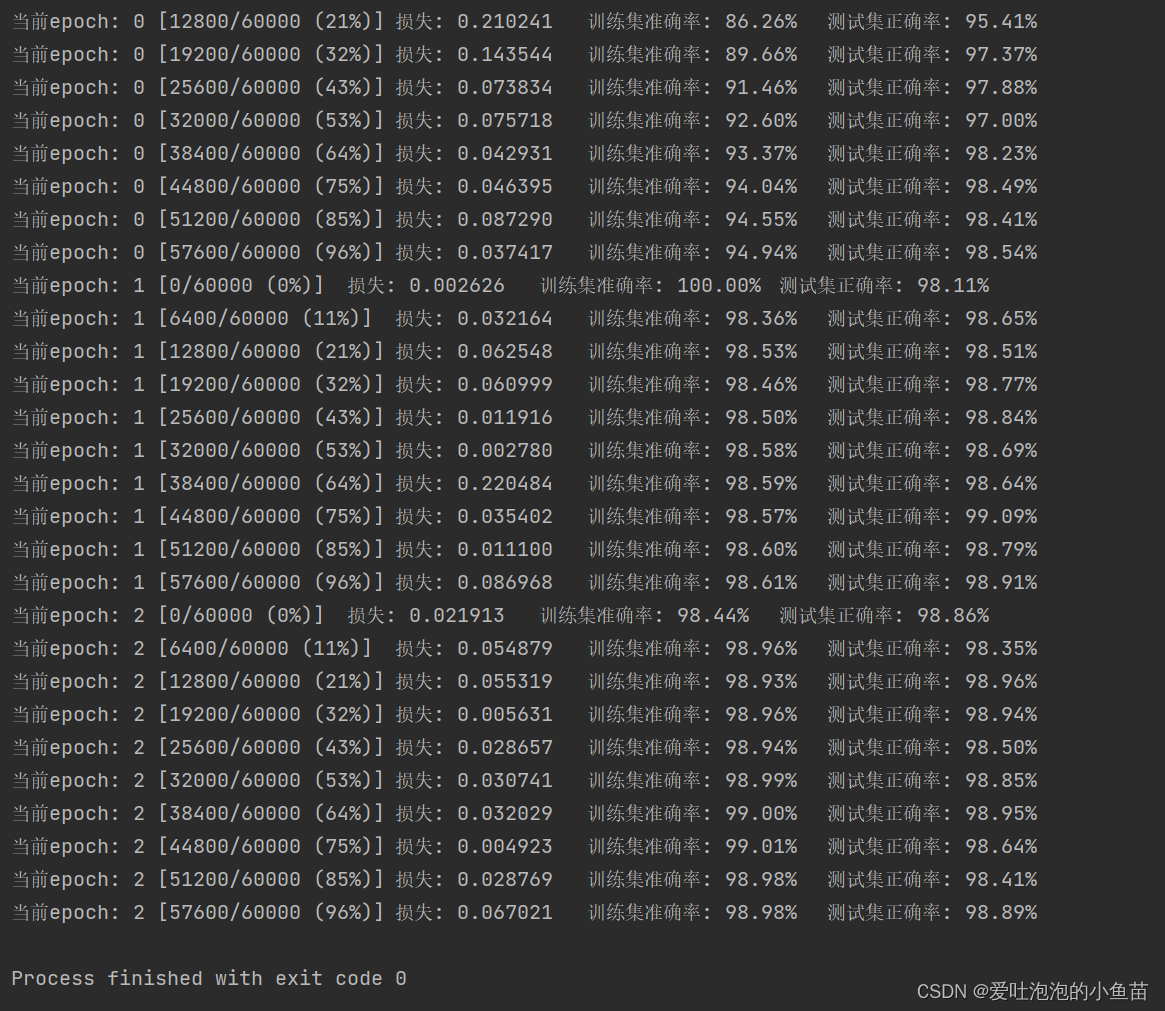
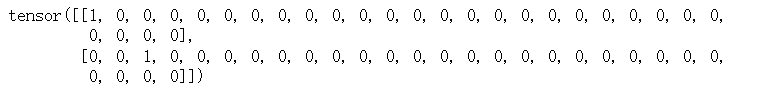1.训练神经网络模型
首先使用GPU训练且保存好神经网络模型:
# encoding=gbk
# 开发时间:2024/3/10 19:51
# 使用GPU进行训练:
'''
网络模型
数据
损失函数
三者调用cuda()
'''
import torch
import torchvision
from torch import nn
from torch.nn import MaxPool2d
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
from nn_mode import *
#准备数据集
train_data=torchvision.datasets.CIFAR10(root='../chap4_Dataset_transforms/dataset',train=True,transform=torchvision.transforms.ToTensor())
test_data=torchvision.datasets.CIFAR10(root='../chap4_Dataset_transforms/dataset',train=False,transform=torchvision.transforms.ToTensor())
#输出数据集的长度
train_data_size=len(train_data)
test_data_size=len(test_data)
print(train_data_size)
print(test_data_size)
#加载数据集
train_loader=DataLoader(dataset=train_data,batch_size=64)
test_loader=DataLoader(dataset=test_data,batch_size=64)
#创建神经网络
sjnet=Sjnet()
sjnet=sjnet.cuda()#网络模型调用cuda
#损失函数
loss_fn=nn.CrossEntropyLoss()
loss_fn=loss_fn.cuda()#损失函数调用cuda
#优化器
learn_lr=0.01#便于修改
YHQ=torch.optim.SGD(sjnet.parameters(),lr=learn_lr)
#设置训练网络的参数
train_step=0#训练次数
test_step=0#测试次数
epoch=20#训练轮数
writer=SummaryWriter('wanzheng_GPU_logs')
for i in range(epoch):
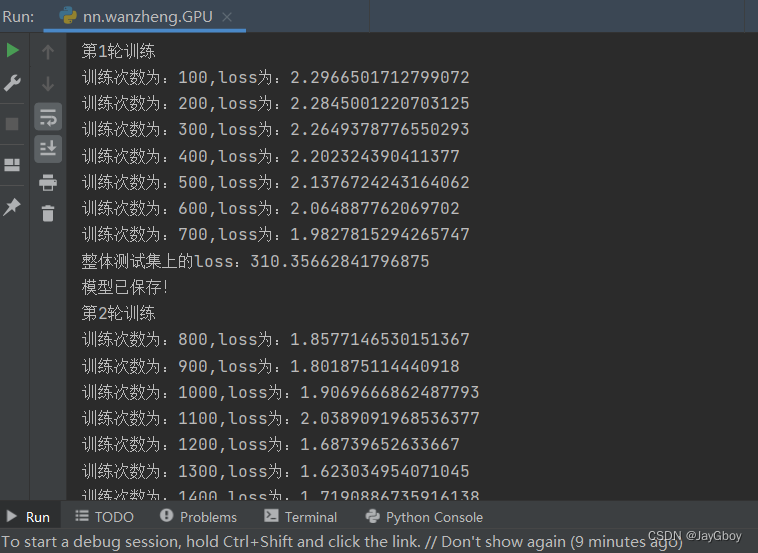
print("第{}轮训练".format(i+1))
#开始训练
for data in train_loader:
imgs,targets=data
imgs=imgs.cuda()
targets=targets.cuda()#数据调用cuda
outputs=sjnet(imgs)
loss=loss_fn(outputs,targets)
#优化器
YHQ.zero_grad() # 将神经网络的梯度置零,以准备进行反向传播
loss.backward() # 执行反向传播,计算神经网络中各个参数的梯度
YHQ.step() # 调用优化器的step()方法,根据计算得到的梯度更新神经网络的参数,完成一次参数更新
train_step =train_step+1
if train_step%100==0:
print('训练次数为:{},loss为:{}'.format(train_step,loss))
writer.add_scalar('train_loss',loss,train_step)
#开始测试
total_loss=0
with torch.no_grad():#上下文管理器,用于指示在接下来的代码块中不计算梯度。
for data in test_loader:
imgs,targets=data
imgs = imgs.cuda()
targets = targets.cuda()#数据调用cuda
outputs = sjnet(imgs)
loss = loss_fn(outputs, targets)#使用损失函数 loss_fn 计算预测输出与目标之间的损失。
total_loss=total_loss+loss#将当前样本的损失加到总损失上,用于累积所有样本的损失。
print('整体测试集上的loss:{}'.format(total_loss))
writer.add_scalar('test_loss', total_loss, test_step)
test_step = test_step+1
torch.save(sjnet,'sjnet_GPU_{}.pth'.format(i))
print("模型已保存!")
writer.close()本次神经网络模型共训练20次:
2.提供完整待测试的神经网络
以下是完整的神经网络:
# encoding=gbk
# 开发时间:2024/3/10 20:38
from PIL import Image
import torch
import torchvision
from torch.nn import Conv2d,MaxPool2d,Flatten,Linear,Sequential
from torch import nn
#准备图片
img_path='../data/测试图片/kache.png'
img=Image.open(img_path)
#print(img)
#调整图片
img=img.convert('RGB')
#print(img)
transform=torchvision.transforms.Compose([torchvision.transforms.Resize((32,32)),
torchvision.transforms.ToTensor()])
#将图片转换为tensor数据类型
img=transform(img)
#print(img.shape)
#网络模型
class Sjnet(nn.Module):
def __init__(self):
super(Sjnet, self).__init__()
self.mode=Sequential(
Conv2d(3,32,5,padding=2),
MaxPool2d(2),
Conv2d(32, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 64, 5, padding=2),
MaxPool2d(2),
Flatten(),
Linear(1024,64),
Linear(64,10)
)
def forward(self,x):
x=self.mode(x)
return x
img = img.to('cuda')#将输入图像张量移动到GPU上进行计算
mode=torch.load('sjnet_GPU_19.pth')
img=torch.reshape(img,(1,3,32,32))#重新调整输入图像张量的形状,将其变为一个四维张量,形状为(1, 3, 32, 32)
mode.eval()#将模型设置为评估模式
with torch.no_grad():#上下文管理器,用于禁用梯度计算,以减少内存消耗
output=mode(img)
#print(output)
#print(output.argmax(1))#计算输出结果中每个样本的最大值索引,并打印出来
#print(output.argmax(1).item())#只输出类别编号
i=output.argmax(1).item()
if i==0:
print("飞机")
elif i==1:
print("汽车")
elif i==2:
print("鸟")
elif i==3:
print("猫")
elif i==4:
print("鹿")
elif i==5:
print("狗")
elif i==6:
print("蛙")
elif i==7:
print("马")
elif i==8:
print("船")
elif i==9:
print("卡车")
else:
print('未识别出类别!')3.注意事项
根据提供的代码,有几个问题需要注意:
模型加载:在代码中,尝试加载名为'sjnet_GPU_19.pth'的模型文件。请确保该文件存在,并且在正确的路径下。如果文件不存在或路径不正确,将无法成功加载模型。
模型实例化:在代码中,定义了一个名为'Sjnet'的模型类,但在加载模型时使用了一个名为'mode'的变量。请确保这两个名称一致,以便正确加载和使用模型。
图像尺寸调整:在代码中,使用了
torchvision.transforms.Resize((32,32))将图像调整为大小为32x32像素的张量。请确保输入的图像尺寸与调整后的尺寸匹配。如果图像的原始尺寸不是32x32像素,则需要调整此处的目标大小。输出处理:在代码的最后,打印了模型的输出,并使用
output.argmax(1)获取最大值的索引。请确保模型输出的维度和类别数目匹配,以便正确计算最大值索引。
4. 遇到的问题:
1.错误代码:
Input type (torch.FloatTensor) and weight type (torch.cuda.FloatTensor) should be the same
根据错误信息,遇到了输入类型与权重类型不匹配的问题。这是因为模型权重是在GPU上训练的,而输入张量是在CPU上计算的。
要解决这个问题,可以将输入张量移动到GPU上,以与模型权重的类型匹配。可以使用.to(device)方法将张量移动到特定的设备上,其中device可以是'cuda'或'cuda:0',表示使用第一个GPU设备。
请在加载模型之前添加以下代码行,将输入张量移动到GPU上:
img = img.to('cuda')
这将把img张量移动到GPU上,使其与模型权重的类型匹配。
请注意,为了在GPU上运行代码,系统必须具有可用的GPU,并且已正确安装了PyTorch GPU版本。如果系统不具备这些条件,可以考虑将代码修改为在CPU上运行,即将模型权重加载到CPU上并将输入张量保留在CPU上。
2.为什么会输出:tensor([0], device='cuda:0')
输出 tensor([0], device='cuda:0') 表示推断的结果是一个形状为 (1,) 的张量,其中包含一个元素。该张量位于 cuda:0 设备上,即第一个 GPU 设备。
具体来说,tensor([0]) 表示推断的结果是一个包含一个元素的张量,该元素的值为 0。这意味着模型预测输入图像的类别为 0。请注意,类别的编号从 0 开始,因此这里的类别标签是 0。
输出结果的设备信息 'device='cuda:0' 表示该张量位于 GPU 上进行计算。这是因为在加载模型时,您将模型和输入图像都移动到了 GPU 上进行计算,因此输出结果也位于 GPU 上。
如果您希望在 CPU 上获取输出结果,可以使用 output.cpu() 将其移动到 CPU 上。例如,您可以将 print(output.argmax(1)) 修改为 print(output.argmax(1).cpu()),这样输出结果将位于 CPU 上。
3.怎么才能只输出类别编号
已知训练的数据集只有以下10中类别:

我们在测试时需要直观的去了解输入图片的类别,故可以利用其输出的tensor类型中的类别编号来进行分类输出,即:
i=output.argmax(1).item()
if i==0:
print("飞机")
elif i==1:
print("汽车")
elif i==2:
print("鸟")
elif i==3:
print("猫")
elif i==4:
print("鹿")
elif i==5:
print("狗")
elif i==6:
print("蛙")
elif i==7:
print("马")
elif i==8:
print("船")
elif i==9:
print("卡车")
else:
print('未识别出类别!')要只输出类别编号,可以使用 .item() 方法来提取张量中的单个元素的值。这将返回一个 Python 数值,而不是一个张量。
在代码中,将 print(output.argmax(1)) 修改为 print(output.argmax(1).item()) 即可只输出类别编号。
这样修改后,输出将只显示一个整数,表示推断的类别编号,而不再包含其他张量信息。
5.开始测试
首先我们从百度下载在十种类别中的图片,例如:
将复制的图片粘贴至测试文件夹中:

将图片的地址导入,点击运行:

其运行结果:
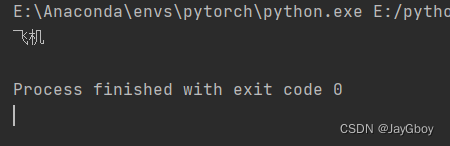
由于训练次数过少或者数据集内容匮乏,可能会导致识别时出现错误。
6.如何改进
要提高神经网络的识别能力,可以尝试以下几种方法:
1. 增加训练数据量:更多的训练数据有助于网络学习更广泛的特征和模式,从而提高其泛化能力。可以尝试收集更多的训练样本,或者通过数据增强技术来生成更多的训练样本。
2. 调整网络架构:尝试使用更深、更宽的网络架构,增加网络的容量。更深的网络可以捕捉更复杂的特征,而更宽的网络可以提供更多的参数来拟合数据。可以尝试使用预训练的网络架构,如ResNet、Inception、EfficientNet等,或者进行自定义的网络设计。
3. 调整超参数:优化神经网络的超参数可以显著影响其性能。例如,学习率、批量大小、正则化参数等。尝试使用交叉验证或自动调参工具来寻找最佳的超参数组合。
4. 使用正则化技术:正则化技术有助于减少过拟合,并提高网络的泛化能力。常见的正则化技术包括L1和L2正则化、Dropout、批量归一化等。通过在训练过程中应用适当的正则化技术,可以提高网络的鲁棒性和泛化能力。
5. 进行模型集成:将多个模型的预测结果进行集成可以提高整体的识别能力。常见的模型集成方法包括投票集成、平均集成、堆叠集成等。通过结合多个模型的预测结果,可以减少预测的偏差,并提高整体的准确性。
6. 进行迁移学习:利用预训练的模型在相关任务上进行迁移学习可以加速模型的训练过程,并提高模型的性能。通过在预训练模型的基础上微调网络参数,可以将模型的先前知识应用于新任务,从而提高识别能力。
7. 考虑数据预处理:对输入数据进行适当的预处理可以帮助网络更好地学习特征。例如,对图像进行标准化、裁剪、旋转等操作,对文本进行分词、词向量化等操作。合适的数据预处理可以提高数据的可比性和可学习性。
8. 调整优化算法:优化算法对于神经网络的训练至关重要。尝试使用不同的优化算法,如随机梯度下降(SGD)、动量优化、自适应学习率算法(如Adam、RMSprop)等,并调整其超参数。
9. 进行模型调试和验证:定期进行模型调试和验证,以确保模型的正确性和稳定性。通过监控模型的性能指标和损失曲线,及时发现问题并进行调整和改进。
10. 持续学习和探索新技术:深度学习领域发展迅速,不断涌现出新的技术和方法。保持学习和探索的态度,关注最新的研究成果和技术进展,可以帮大家不断提高神经网络的识别能力。
提高神经网络的识别能力是一个迭代和复杂的过程。可能需要尝试多种方法,并根据具体问题和数据集的特点进行调整和优化。同时,理解和分析模型的性能指标和结果,以及对错误分类的样本进行深入分析,也是提高识别能力的重要步骤。