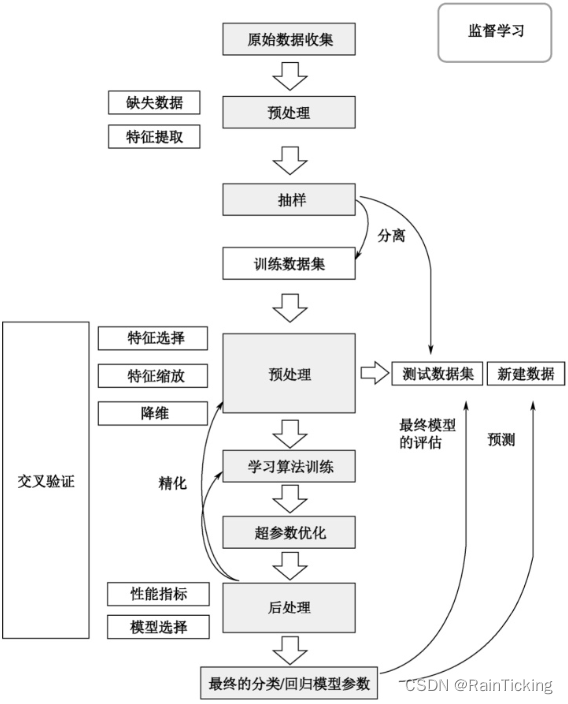
模型
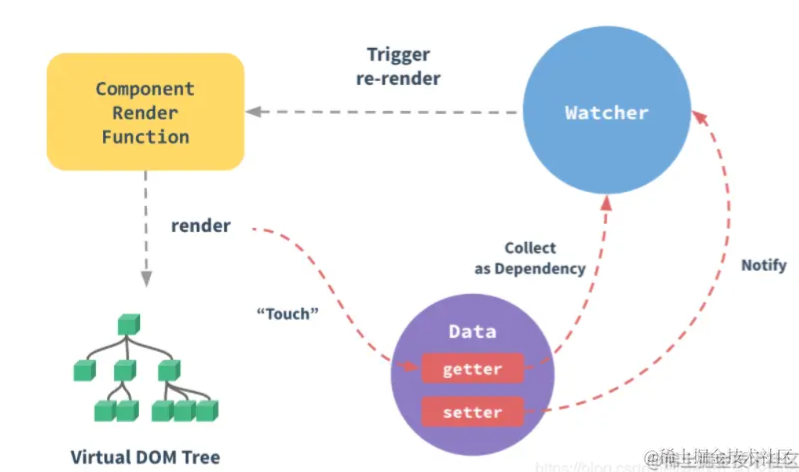
神经网络采用下图

我使用之后发现迭代多了之后一直最高是正确率65%左右,然后我自己添加了一些Relu激活函数和正则化,现在正确率可以有80%左右。
模型代码
import torch
from torch import nn
class YmModel(nn.Module):
def __init__(self):
super(YmModel, self).__init__()
self.model = nn.Sequential(
nn.Conv2d(3, 32, kernel_size=5, stride=1, padding=2),
nn.BatchNorm2d(32),
nn.ReLU(),
nn.MaxPool2d(2),
nn.Conv2d(32, 32, kernel_size=5, stride=1, padding=2),
nn.BatchNorm2d(32),
nn.ReLU(),
nn.MaxPool2d(2),
nn.Conv2d(32, 64, kernel_size=5, stride=1, padding=2),
nn.BatchNorm2d(64),
nn.ReLU(),
nn.MaxPool2d(2),
nn.Flatten(),
nn.Linear(64 * 4 * 4, 512),
nn.ReLU(),
nn.Dropout(0.5),
nn.Linear(512, 64),
nn.ReLU(),
nn.Dropout(0.5),
nn.Linear(64, 10),
)
def forward(self, x):
return self.model(x)
训练
有一点要说明的是,数据集中并没有验证集,你可以从训练集扣个1w张出来
import torch
import torchvision
from torchvision import transforms
from models.YMModel import YmModel
from torch.utils.data import DataLoader
transform_train = transforms.Compose([
transforms.RandomCrop(32, padding=4),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)),
])
# 数据集
train_dataset = torchvision.datasets.CIFAR10(root='./data', train=True, transform=transform_train, download=True)
test_dataset = torchvision.datasets.CIFAR10(root='./data', train=False, transform=torchvision.transforms.ToTensor(), download=True)
train_loader = DataLoader(train_dataset, batch_size=64, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=64)
print(len(train_loader), len(test_loader))
print(len(train_dataset), len(test_dataset))
model = YmModel()
#迭代次数
train_epochs = 300
#优化器
optimizer = torch.optim.Adam(model.parameters(), lr=1e-3)
# 损失函数
loss_fn = torch.nn.CrossEntropyLoss()
train_epochs_step = 0
best_accuracy = 0.
for epoch in range(train_epochs):
model.train()
print(f'Epoch is {epoch}')
for images, labels in train_loader:
outputs = model(images)
loss = loss_fn(outputs, labels)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if train_epochs_step % 100 == 0:
print(f'Train_Epoch is {train_epochs_step}\t Loss is {loss.item()}')
train_epochs_step += 1
train_epochs_step = 0
with torch.no_grad():
loss_running_total = 0.
acc_running_total = 0.
for images, labels in test_loader:
outputs = model(images)
loss = loss_fn(outputs, labels)
loss_running_total += loss.item()
acc_running_total += (outputs.argmax(1) == labels).sum().item()
acc_running_total /= len(test_dataset)
if acc_running_total > best_accuracy:
best_accuracy = acc_running_total
torch.save(model.state_dict(), './best_model.pth')
print('accuracy is {}'.format(acc_running_total))
print('total loss is {}'.format(loss_running_total))
print('best accuracy is {}'.format(best_accuracy))
验证
import os
import numpy as np
import torch
import torchvision
from PIL import Image
from torch.utils.data import DataLoader
from torchvision import transforms
from models.TestColor import TextColor
from models.YMModel import YmModel
test_dataset = torchvision.datasets.CIFAR10(root='./data', train=False, transform=torchvision.transforms.ToTensor(), download=True)
test_loader = DataLoader(test_dataset, batch_size=64, shuffle=False)
classes = ('airplane', 'automobile', 'bird', 'cat', 'deer','dog', 'frog', 'horse', 'ship', 'truck')
model = YmModel()
model.load_state_dict(torch.load('best_model.pth'))
model.eval()
with torch.no_grad():
correct = 0.
for images, labels in test_loader:
outputs = model(images)
_, predicted = torch.max(outputs, 1)
correct += (predicted == labels).sum().item()
print('Accuracy : {}'.format(100 * correct / len(test_dataset)))
folder_path = './images'
files_names = os.listdir(folder_path)
transform_test = transforms.Compose([
transforms.Resize((32, 32)),
transforms.ToTensor(),
])
for file_name in files_names:
image_path = os.path.join(folder_path, file_name)
image = Image.open(image_path)
image = transform_test(image)
image = np.reshape(image, [1, 3, 32, 32])
output = model(image)
_, predicted = torch.max(output, 1)
source_name = os.path.splitext(file_name)[0]
predicted_class = classes[predicted.item()]
colors = TextColor.GREEN if predicted_class == source_name else TextColor.RED
print(f"Source is {TextColor.BLUE}{source_name}{TextColor.RESET}, and predicted is {colors}{predicted_class}{TextColor.RESET}")
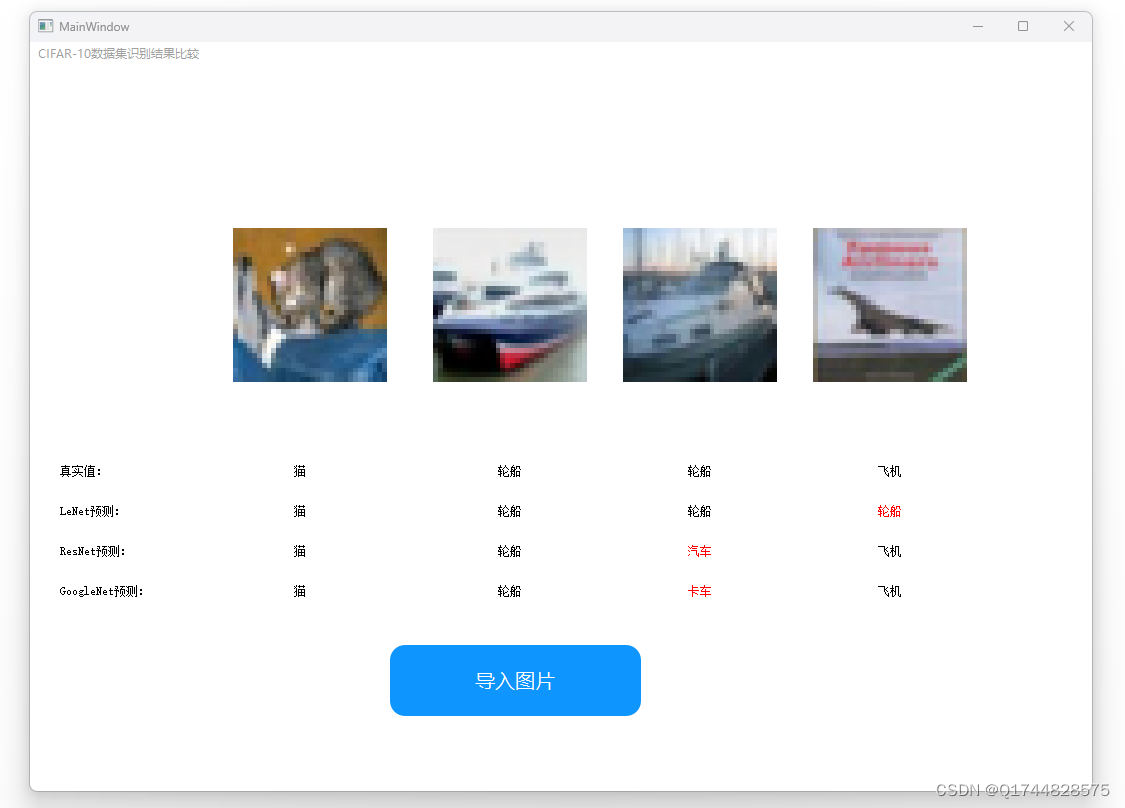
结果
TextColor是自定义字体颜色的类,
image中就是自己的图片。
结果如下:测试集的正确率有82.7%