From:一场关于深度学习技术的在线直播。为大家讲解了基于深度学习的deep fake检测模型。主要内容包括baseline精讲、预测训练模型的使用、模型训练、性能评估与优化等。
背景
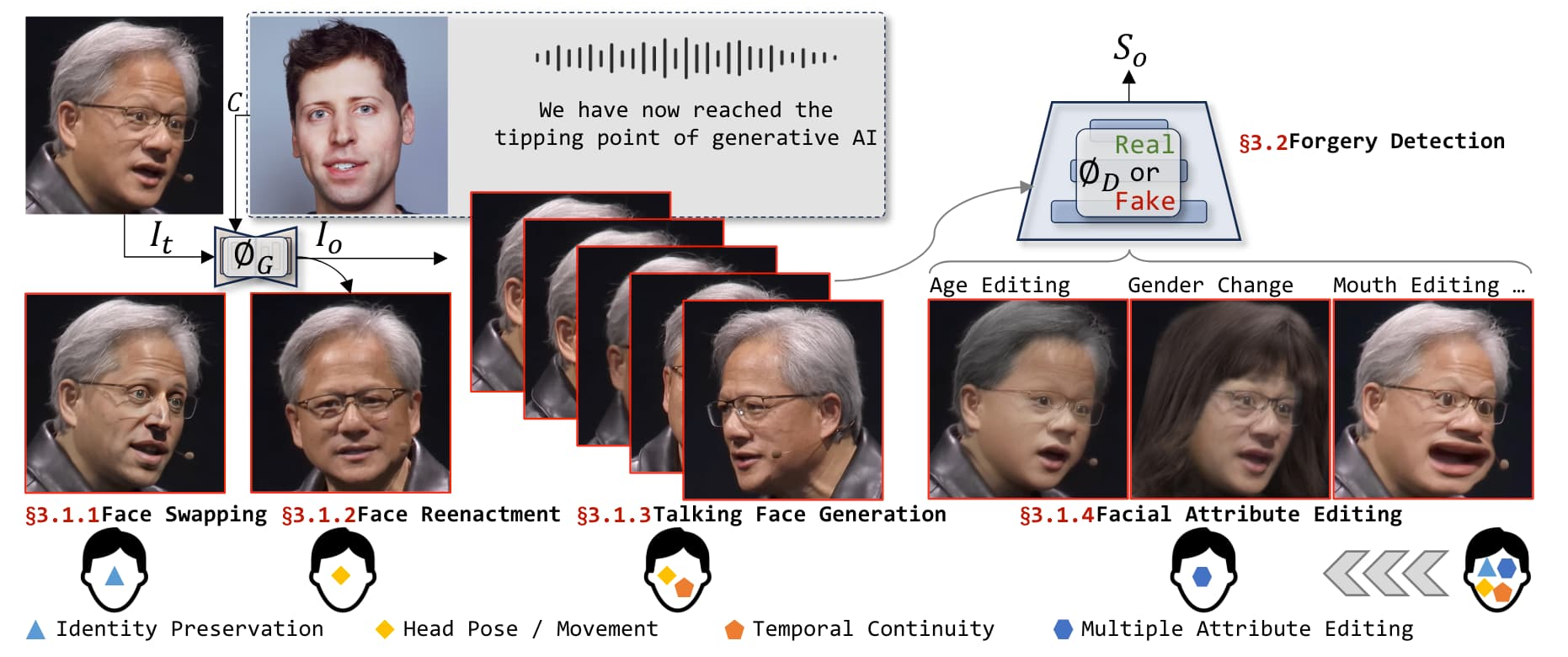
Deepfake技术介绍:Deepfake是一种利用深度学习技术生成逼真假视频的技术。可用于娱乐、教育等领域,但也存在被滥用的风险。可能被用于制造假新闻、误导公众等。
Deepfake检测模型的实现:
- 数据集准备:需要收集和准备用于训练和测试的数据集。
- 模型训练:包括前向传播、损失计算、反向传播和参数更新等步骤。
- 性能评估与优化:通过准确率等指标评估模型性能,并进行优化。
- 加载和微调预训练模型可以加快训练过程并提高模型性能。
基础知识补课
深度学习是机器学习的一个分支,使用神经网络模拟人脑的学习方式。依赖于多层神经网络,每一层神经元接受前一层神经元的输出,并通过权重和激活函数进行计算。
神经元模型模拟生物神经元行为的计算模型,在人工智能和机器学习领域扮演核心角色。包括输入、权重、激活函数和输出。

神经网络由基础神经元模型层层堆叠形成的复杂结构。网络的最底层接收输入数据,通过每一层的处理,逐渐提取出更高级别的特征,最后在顶层输出结果。根据任务需求选择适当的深度学习模型,如卷积神经网络(CNN)用于图像处理,循环神经网络(RNN)用于文本或序列处理。

模型训练流程:
- 前向传播:输入数据通过神经网络的每层,逐步进行处理,生成预测输出。
- 损失计算:计算模型预测输出与实际标签之间的差异,得到损失值。
- 反向传播:根据损失值反向更新网络中每一层的权重,调整网络参数,以减少预测误差。
- 参数更新:通过优化算法(如梯度下降)更新网络的权重和偏置。
梯度下降pytorch训练代码:
回顾训练一个分类模型:
def train(train_loader, model, criterion, optimizer, epoch):
# switch to train mode
model.train()
end = time.time()
for i, (input, target) in enumerate(train_loader):
input = input.cuda(non_blocking=True)
target = target.cuda(non_blocking=True)
# compute output
output = model(input)
loss = criterion(output, target)
optimizer.zero_grad()
loss.backward()
optimizer.step()
首先,我们需要准备一批图片数据(通过train_loader)和这些图片对应的正确标签(target)。
在开始训练之前,将模型设置为训练模式( model.train() ),这样模型就知道现在是学习时间了。
接着,开始喂给模型图片数据,并让它尝试预测这些图片的内容。
模型会基于它目前的学习给出预测结果(output),而会计算这些预测结果与实际标签之间的差异,这个差异就是损失(loss)。
为了让模型学会准确预测,需要指出它的错误,并更新它的内部参数来减少这些错误(通过loss.backward()和optimizer.step())。
这个过程就像是模型在自我调整,以便在下一次遇到类似图片时能够做出更准确的预测。
性能评估:
使用准确率、召回率、F1分数等指标来评估模型的性能。
可以通过交叉验证等方法提高评估的可靠性。
各种优化技术和算法:根据性能评估的结果,调整模型结构或参数,如增加或减少网络层、调整激活函数、改变学习率等。使用正则化技术(如L1、L2正则化)减少过拟合。
- 激活函数Activation Fuction的改进、
- 权重初始化Weight Initilization方法、
- 正则化技术Normalization以及
- 梯度下降的变种Gradient Gescent Optimization Algoritms 。
- 他们还开发了新的网络结构Network Structure,如卷积神经网络(CNN)和循环神经网络( RNN ),以适应不同类型的数据和任务。
demo
参考:https://www.kaggle.com/code/gmyelims/deepfake-ffdi-ch2/edit
- 创建/导入数据的格式:

Tensor格式:


自动求梯度
# x = torch.ones(2, 2, requires_grad=True)
x = torch.tensor([[1, 2], [3, 4]], dtype=float, requires_grad=True)
print(x)
y = x + 2
print(y)
print(y.grad_fn) # y就多了一个AddBackward
z = y * y * 3
out = z.mean()
print(z) # z多了MulBackward
print(out) # out多了MeanBackward
# out = 0.25 ((x+2) * (x+2) * 3)
tensor([[1., 2.],
[3., 4.]], dtype=torch.float64, requires_grad=True)
tensor([[3., 4.],
[5., 6.]], dtype=torch.float64, grad_fn=AddBackward0>)
<AddBackward0 object at 0x7ab248320160>
tensor([[ 27., 48.],
[ 75., 108.]], dtype=torch.float64, grad_fn=MulBackward0/>)
tensor(64.5000, dtype=torch.float64, grad_fn=MeanBackward0>)
add Codeadd Markdown
out.backward()
# 0.25 * 3 * 2 * (x+2)
arrow_upwardarrow_downwarddelete
print(x.grad) # out=0.25*Σ3(x+2)^2
tensor([[4.5000, 6.0000],
[7.5000, 9.0000]], dtype=torch.float64)
拟合函数
import matplotlib.pyplot as plt
from IPython.display import set_matplotlib_formats
set_matplotlib_formats('svg')
# 画图就展示到notebook
%matplotlib inline
# numpy 数值计算、矩阵运算,CPU计算
# tensor 数值计算、矩阵运算 CPU 或 GPU计算
# 准备数据
x = np.linspace(0, 10, 100)
y = -3 * x + 4 + np.random.randint(-2, 2, size=100)
# y = -3x + 4
# y = wx + b
plt.scatter(x, y)

# 需要计算得到的参数
w = torch.ones(1, requires_grad=True)
b = torch.ones(1, requires_grad=True)
# 数据
x_tensor = torch.from_numpy(x)
y_tensor = torch.from_numpy(y)
# y = wx + b
def mse(label, pred):
diff = label - pred
return torch.sqrt((diff ** 2).mean())
pred = x_tensor * w + b
loss = mse(y_tensor, pred)
loss # 误差
tensor(21.0650, dtype=torch.float64, grad_fn=SqrtBackward0>)
# 执行20次参数更新,计算梯度及更新
for _ in range(20):
# 重新定义一下,梯度清空
w = w.clone().detach().requires_grad_(True)
b = b.clone().detach().requires_grad_(True)
# 正向传播
pred = x_tensor * w + b
loss = mse(y_tensor, pred)
print(loss)
loss.backward() # 反向传播
w = w - w.grad * 0.05 # 学习率
b = b - b.grad * 0.05
# 正向传播、计算损失、计算梯度、参数更新
# 多步的训练,随机梯度下降
tensor(21.0650, dtype=torch.float64, grad_fn=SqrtBackward0>)
tensor(19.3673, dtype=torch.float64, grad_fn=SqrtBackward0>)
tensor(17.6724, dtype=torch.float64, grad_fn=SqrtBackward0>)
LOSS下降中

使用预训练模型:
import timm
from PIL import Image
model = timm.create_model('resnet18', pretrained=True)
transform = timm.data.create_transform(
**timm.data.resolve_data_config(model.pretrained_cfg)
)
image_tensor = transform(image)
output = model(image_tensor.unsqueeze(0))
probabilities = torch.nn.functional.softmax(output[0], dim=0)
values, indices = torch.topk(probabilities, 5)
IMAGENET_1k_LABELS = open('imagenet_classes.txt').readlines()
[{'label': IMAGENET_1k_LABELS[idx], 'value': val.item()} for val, idx in zip(values, indices)]
如何使用PyTorch和timm库来加载一个预训练的ResNet-18模型,并用它对一张图片进行分类。
- import timm:导入timm库,这是一个包含多种预训练模型和实用工具的库。
- from PIL import Image: 从PIL库导入Image模块,用于图像处理
- model = timm.create_model(‘resnet18’, pretrained=True): 使用timm库创建一个名为’resnet18’的预训练模型。pretrained=True参数表示加载在ImageNet数据集上预训练的权重。
- transform=timm.data.create_transform(**timm.data.resolve_data_config(model.pretrained_cfg)): 创建一个图像转换对象,这个对象包含了将图像转换为模型输入所需的所有步骤,如缩放、裁剪、归一化等。转换配置是根据模型的预训练配置自动解析得到的。
- image_tensor = transform(image): 将PIL图像对象image通过转换对象transform进行转换,得到一个适合模型输入的张量image_tensor。
- output =model(image_tensor.unsqueeze(0)):将转换后的图像张量增加一个维度(因为模型预期的输入是批量数据),然后将其传入模型进行前向传播,得到分类结果output。
- probabilities = torch.nn.functional.softmax(output[0], dim=0):使用softmax函数对模型输出进行归一化,得到每个类别的概率分布。output[0]是因为output是一个元组,我们只关心第一个元素,即模型的原始输出
- values, indices = torch.topk(probabilities, 5):从概率分布中获取概率最高的5个类别的索引和对应的值。values是概率值,indices是对应的类别索引。
- IMAGENET_1k_LABELS = open(‘imagenet_classes.txt’).readlines():读取包含ImageNet数据集1000个类别名称的文件,每个类别名称占一行。
- [{‘label’: IMAGENET_1k_LABELS[idx], ‘value’: val.item()} for val, idx in zip(values, indices)]: 将概率值和类别索引转换为一个列表,列表中的每个元素是一个字典,包含类别名称和对应的归一化概率值。这是通过将values和indices与IMAGENET_1k_LABELS中读取的类别名称进行映射实现的。
代码运行结果: