【Datawhale AI 夏令营】CV图像竞赛——Deepfake攻防
从零入门CV图像竞赛(Deepfake攻防) 是 Datawhale 2024 年 AI 夏令营第二期 的学习活动(“CV图像”方向),基于蚂蚁集团举办的“外滩大会-全球Deepfake攻防挑战赛”开展的实践学习
这几天参加了Datawhale AI 夏令营的CV图像竞赛,跟随DataWhale的学习指南,跑通Baseline,在Kaggle平台完成整个Deepfake攻防挑战赛。下面来介绍本次活动的内容及收获。
1 Deepfake攻防任务介绍
随着人工智能技术的迅猛发展,深度伪造技术(Deepfake)正成为数字世界中的一把双刃剑。Deepfake技术可以通过人工智能算法生成高度逼真的图像、视频和音频内容,这些内容看起来与真实的毫无二致。
1.1 赛题任务
Deepfake是一种使用人工智能技术生成的伪造媒体,特别是视频和音频,它们看起来或听起来非常真实,但实际上是由计算机生成的。这种技术通常涉及到深度学习算法,特别是生成对抗网络(GANs),它们能够学习真实数据的特征,并生成新的、逼真的数据。
深度伪造技术通常可以分为四个主流研究方向:
- 面部交换专注于在两个人的图像之间执行身份交换;
- 面部重演强调转移源运动和姿态;
- 说话面部生成专注于在角色生成中实现口型与文本内容的自然匹配;
- 面部属性编辑旨在修改目标图像的特定面部属性;
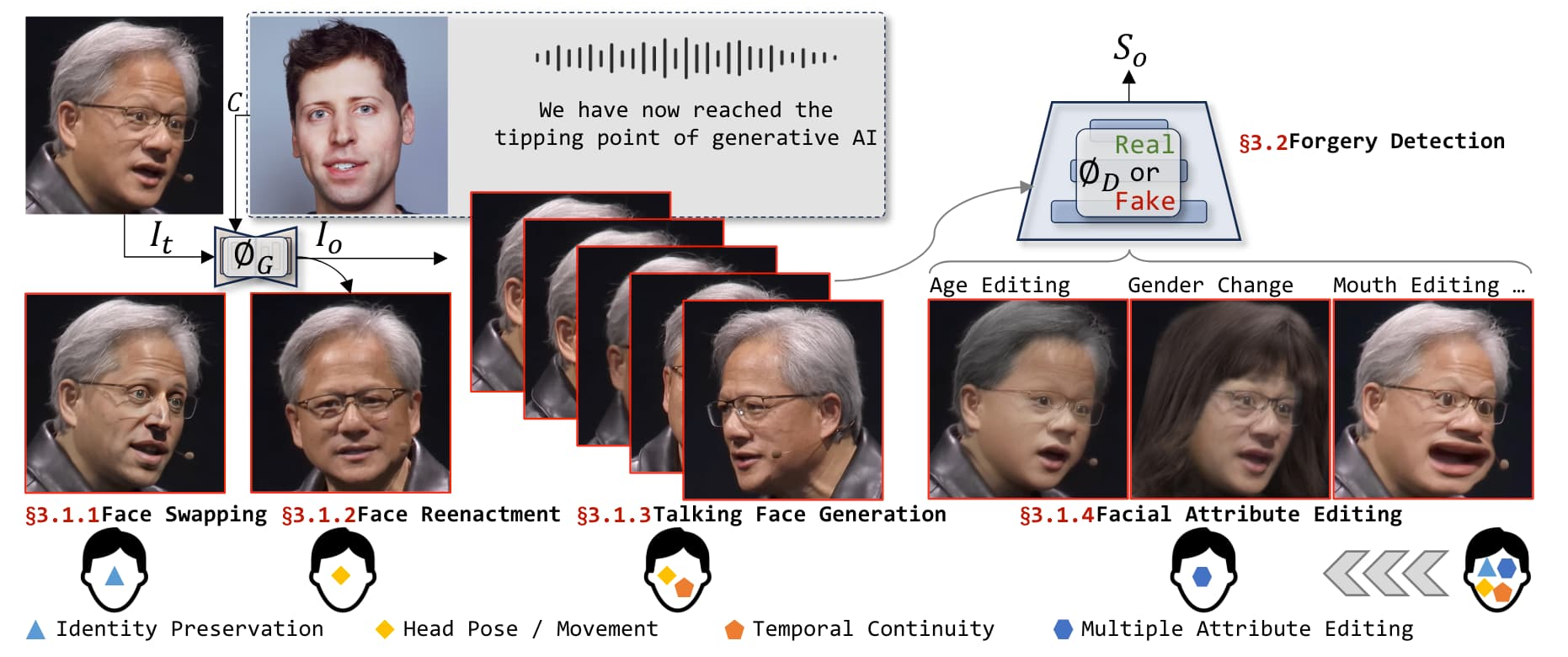
本次Deepfake任务目标即为训练模型,判断一张人脸图像是否为Deepfake图像,并输出其为Deepfake图像的概率评分。

1.2 赛题数据集
第一阶段
在第一阶段,主办方将发布训练集和验证集。参赛者将使用训练集 (train_label.txt) 来训练模型,而验证集 (val_label.txt) 仅用于模型调优。文件的每一行包含两个部分,分别是图片文件名和标签值(label=1 表示Deepfake图像,label=0 表示真实人脸图像)。例如:
train_label.txt
img_name,target 3381ccbc4df9e7778b720d53a2987014.jpg,1 63fee8a89581307c0b4fd05a48e0ff79.jpg,0 7eb4553a58ab5a05ba59b40725c903fd.jpg,0 …val_label.txt
img_name,target cd0e3907b3312f6046b98187fc25f9c7.jpg,1 aa92be19d0adf91a641301cfcce71e8a.jpg,0 5413a0b706d33ed0208e2e4e2cacaa06.jpg,0 …第二阶段
在第一阶段结束后,主办方将发布测试集。在第二阶段,参赛者需要在系统中提交测试集的预测评分文件 (prediction.txt),主办方将在线反馈测试评分结果。文件的每一行包含两个部分,分别是图片文件名和模型预测的Deepfake评分(即样本属于Deepfake图像的概率值)。例如:
prediction.txt
img_name,y_pred cd0e3907b3312f6046b98187fc25f9c7.jpg,1 aa92be19d0adf91a641301cfcce71e8a.jpg,0.5 5413a0b706d33ed0208e2e4e2cacaa06.jpg,0.5 …第三阶段
在第二阶段结束后,前30名队伍将晋级到第三阶段。在这一阶段,参赛者需要提交代码docker和技术报告。Docker要求包括原始训练代码和测试API(函数输入为图像路径,输出为模型预测的Deepfake评分)。主办方将检查并重新运行算法代码,以重现训练过程和测试结果。
1.3 评价指标
比赛的性能评估主要使用ROC曲线下的AUC(Area under the ROC Curve)作为指标。AUC的取值范围通常在0.5到1之间。若AUC指标不能区分排名,则会使用TPR@FPR=1E-3作为辅助参考。
真阳性率 (TPR):
T P R = T P / ( T P + F N ) TPR = TP / (TP + FN) TPR=TP/(TP+FN)假阳性率 (FPR):
F P R = F P / ( F P + T N ) FPR = FP / (FP + TN) FPR=FP/(FP+TN)
其中:- TP:攻击样本被正确识别为攻击;
- TN:真实样本被正确识别为真实;
- FP:真实样本被错误识别为攻击;
- FN:攻击样本被错误识别为真实。
2 Baseline实现
本次项目在Kaggle平台进行,DataWhale为学习者提供了跑通整个项目的 baseline 代码,并给出了详细的学习指南。下面结合学习指南内容,介绍基础Baseline代码及训练步骤。
2.1 代码介绍
Baseline代码,采用了 timm 库来进行图像模型的训练和推理。
指标计算与显示
AverageMeter类AverageMeter类用于计算和存储指标的平均值和当前值。它通常用于跟踪训练过程中每个epoch或batch的损失值、精度等。class AverageMeter(object): """计算和存储指标的平均值和当前值""" def __init__(self, name, fmt=':f'): self.name = name self.fmt = fmt self.reset() # 重置所有值 def reset(self): self.val = 0 self.avg = 0 self.sum = 0 self.count = 0 # 更新当前值 def update(self, val, n=1): self.val = val self.sum += val * n self.count += n self.avg = self.sum / self.count # 返回格式化字符串,显示当前值和平均值 def __str__(self): fmtstr = '{name} {val' + self.fmt + '} ({avg' + self.fmt + '})' return fmtstr.format(**self.__dict__)ProgressMeter类ProgressMeter类用于显示训练过程中各个batch的进度和指标。它通常与AverageMeter类一起使用,方便地显示和跟踪多个指标。class ProgressMeter(object): def __init__(self, num_batches, *meters): self.batch_fmtstr = self._get_batch_fmtstr(num_batches) self.meters = meters self.prefix = "" # 打印当前batch的进度和所有指标的状态 def pr2int(self, batch): entries = [self.prefix + self.batch_fmtstr.format(batch)] entries += [str(meter) for meter in self.meters] print('\t'.join(entries)) # 根据总batch数生成格式字符串 def _get_batch_fmtstr(self, num_batches): num_digits = len(str(num_batches // 1)) fmt = '{:' + str(num_digits) + 'd}' return '[' + fmt + '/' + fmt.format(num_batches) + ']'
验证、预测和训练神经网络模型
validate函数validate函数用于在验证集上评估模型性能。def validate(val_loader, model, criterion): # 使用AverageMeter类创建计量器,用于跟踪时间、损失和准确度 batch_time = AverageMeter('Time', ':6.3f') losses = AverageMeter('Loss', ':.4e') top1 = AverageMeter('Acc@1', ':6.2f') progress = ProgressMeter(len(val_loader), batch_time, losses, top1) # 切换到评估模式 model.eval() with torch.no_grad(): end = time.time() # 遍历验证集中的每个batch,计算输出和损失,并更新计量器 for i, (input, target) in tqdm_notebook(enumerate(val_loader), total=len(val_loader)): input = input.cuda() target = target.cuda() # 计算输出与loss output = model(input) loss = criterion(output, target) # 计算accuracy并更新loss acc = (output.argmax(1).view(-1) == target).float().mean() * 100 losses.update(loss.item(), input.size(0)) top1.update(acc, input.size(0)) # 计算运行时间 batch_time.update(time.time() - end) end = time.time() print(' * Acc@1 {top1.avg:.3f}' .format(top1=top1)) return top1predict函数predict函数用于在测试集上进行预测,支持Test-Time Augmentation (TTA)。def predict(test_loader, model, tta=10): # 切换到评估模式 model.eval() test_pred_tta = None for _ in range(tta): test_pred = [] with torch.no_grad(): for i, (input, target) in tqdm_notebook(enumerate(test_loader), total=len(test_loader)): input = input.cuda() target = target.cuda() # 计算输出 output = model(input) output = F.softmax(output, dim=1) output = output.data.cpu().numpy() test_pred.append(output) test_pred = np.vstack(test_pred) if test_pred_tta is None: test_pred_tta = test_pred else: test_pred_tta += test_pred return test_pred_tta / ttatrain函数train函数用于在训练集上训练模型。def train(train_loader, model, criterion, optimizer, epoch): # 使用AverageMeter类创建计量器 batch_time = AverageMeter('Time', ':6.3f') losses = AverageMeter('Loss', ':.4e') top1 = AverageMeter('Acc@1', ':6.2f') progress = ProgressMeter(len(train_loader), batch_time, losses, top1) # 切换到训练模式 model.train() end = time.time() for i, (input, target) in enumerate(train_loader): input = input.cuda(non_blocking=True) target = target.cuda(non_blocking=True) # 计算输出 output = model(input) loss = criterion(output, target) # 计算accuracy并更新loss losses.update(loss.item(), input.size(0)) acc = (output.argmax(1).view(-1) == target).float().mean() * 100 top1.update(acc, input.size(0)) # 计算梯度并更新模型参数 optimizer.zero_grad() loss.backward() optimizer.step() # 计算运行时间 batch_time.update(time.time() - end) end = time.time() if i % 100 == 0: progress.pr2int(i)
自定义数据集类
用于加载图像数据及其对应的标签,并在获取数据时进行必要的转换。
class FFDIDataset(Dataset): def __init__(self, img_path, img_label, transform=None): self.img_path = img_path self.img_label = img_label if transform is not None: self.transform = transform else: self.transform = None # 根据索引获取图像及其对应的标签 def __getitem__(self, index): img = Image.open(self.img_path[index]).convert('RGB') if self.transform is not None: img = self.transform(img) return img, torch.from_numpy(np.array(self.img_label[index])) # 返回数据集的大小 def __len__(self): return len(self.img_path)使用预训练模型进行训练
创建模型
创建一个预训练的ResNet-18模型,用于二分类任务,并将其移动到GPU上。
model = timm.create_model('resnet18', pretrained=True, num_classes=2) model = model.cuda()创建数据加载器
# 定义训练集的数据加载器 train_loader = torch.utils.data.DataLoader( FFDIDataset( train_label['path'].head(1000), train_label['target'].head(1000), transforms.Compose([ transforms.Resize((256, 256)), transforms.RandomHorizontalFlip(), transforms.RandomVerticalFlip(), transforms.ToTensor(), transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]) ]) ), batch_size=40, shuffle=True, num_workers=4, pin_memory=True ) # 定义验证集的数据加载器 val_loader = torch.utils.data.DataLoader( FFDIDataset( val_label['path'].head(1000), val_label['target'].head(1000), transforms.Compose([ transforms.Resize((256, 256)), transforms.ToTensor(), transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]) ]) ), batch_size=40, shuffle=False, num_workers=4, pin_memory=True )定义损失函数、优化器和学习率调度器
# 定义损失函数,并将其移动到GPU上 criterion = nn.CrossEntropyLoss().cuda() # 定义优化器 optimizer = torch.optim.Adam(model.parameters(), lr=0.005) # 定义学习率调度器,每4个epoch后学习率乘以0.85 scheduler = optim.lr_scheduler.StepLR(optimizer, step_size=4, gamma=0.85)训练和验证模型
best_acc = 0.0 for epoch in range(2): # 进行2个epoch的训练 scheduler.step() # 更新学习率 print('Epoch: ', epoch) # 训练模型 train(train_loader, model, criterion, optimizer, epoch) # 在验证集上验证模型 val_acc = validate(val_loader, model, criterion) # 如果当前验证准确率超过最佳准确率,保存模型参数 if val_acc.avg.item() > best_acc: best_acc = round(val_acc.avg.item(), 2) torch.save(model.state_dict(), f'./model_{best_acc}.pt')预测并保存结果
# 定义测试集的数据加载器 test_loader = torch.utils.data.DataLoader( FFDIDataset( val_label['path'], val_label['target'], transforms.Compose([ transforms.Resize((256, 256)), transforms.ToTensor(), transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]) ]) ), batch_size=40, shuffle=False, num_workers=4, pin_memory=True ) # 进行预测,并将预测结果存储在val_label的y_pred列中 val_label['y_pred'] = predict(test_loader, model, 1)[:, 1] # 将结果保存为CSV文件 val_label[['img_name', 'y_pred']].to_csv('submit.csv', index=None)
2.2 Baseline训练
本项目利用Kaggle平台进行训练,训练过程与提交结果在DataWhale学习手册 从零入门CV图像竞赛(Deepfake攻防) 中详细给出。
训练过程
按照手册进行训练,跑通基础的baseline代码。
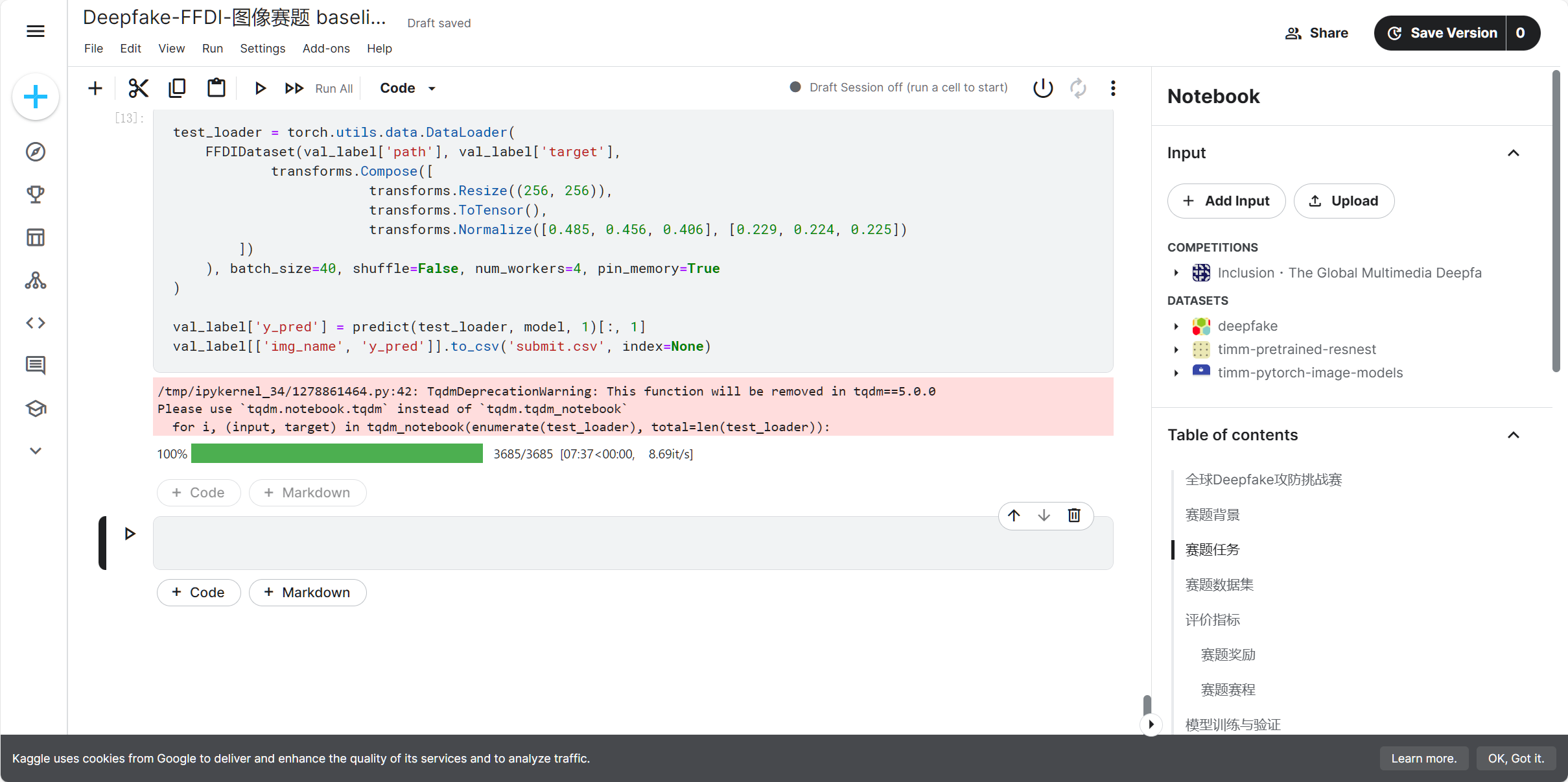
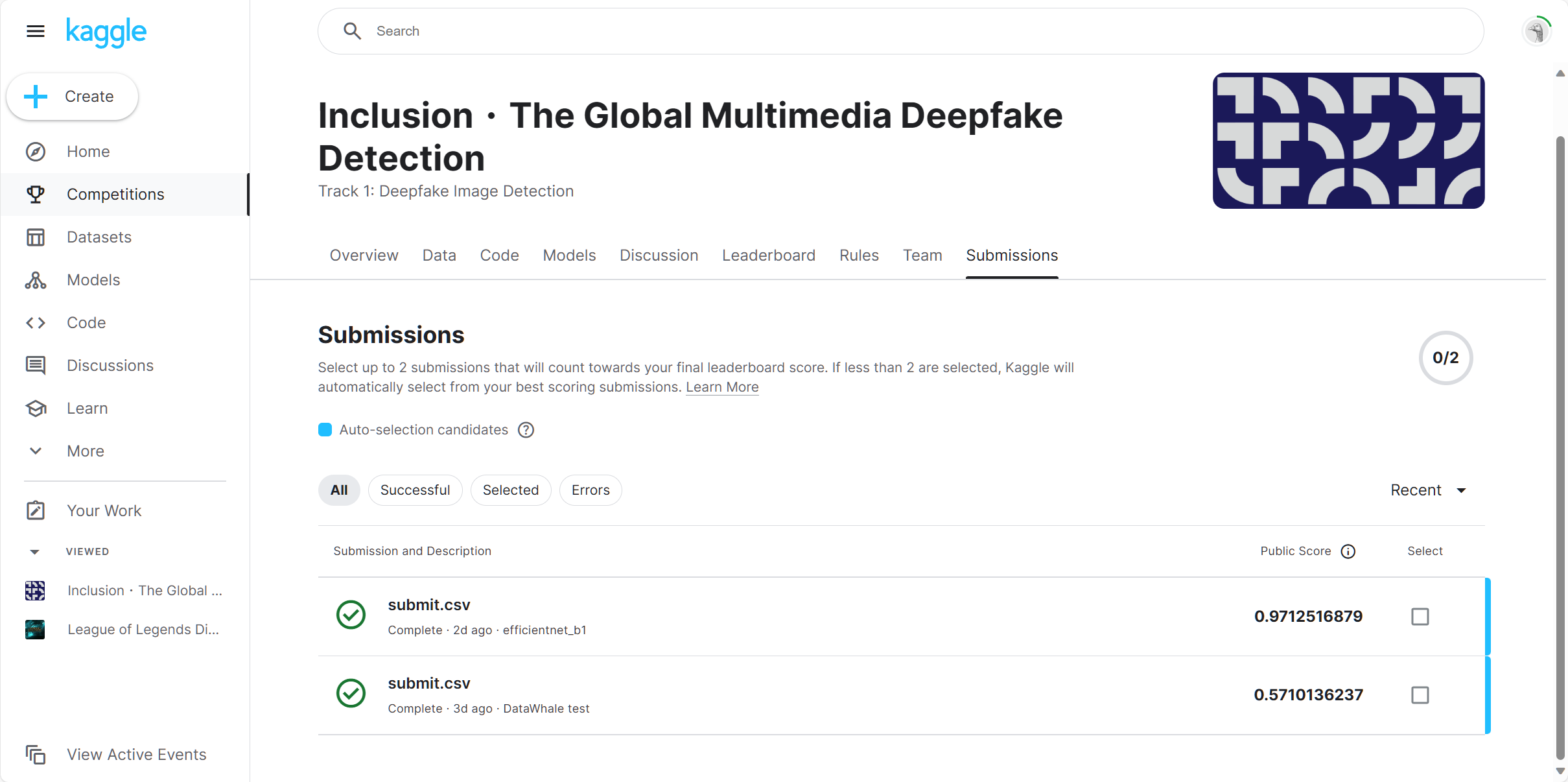
训练结果
在Kaggle平台提交训练结果,跑通Baseline得到0.571的得分。
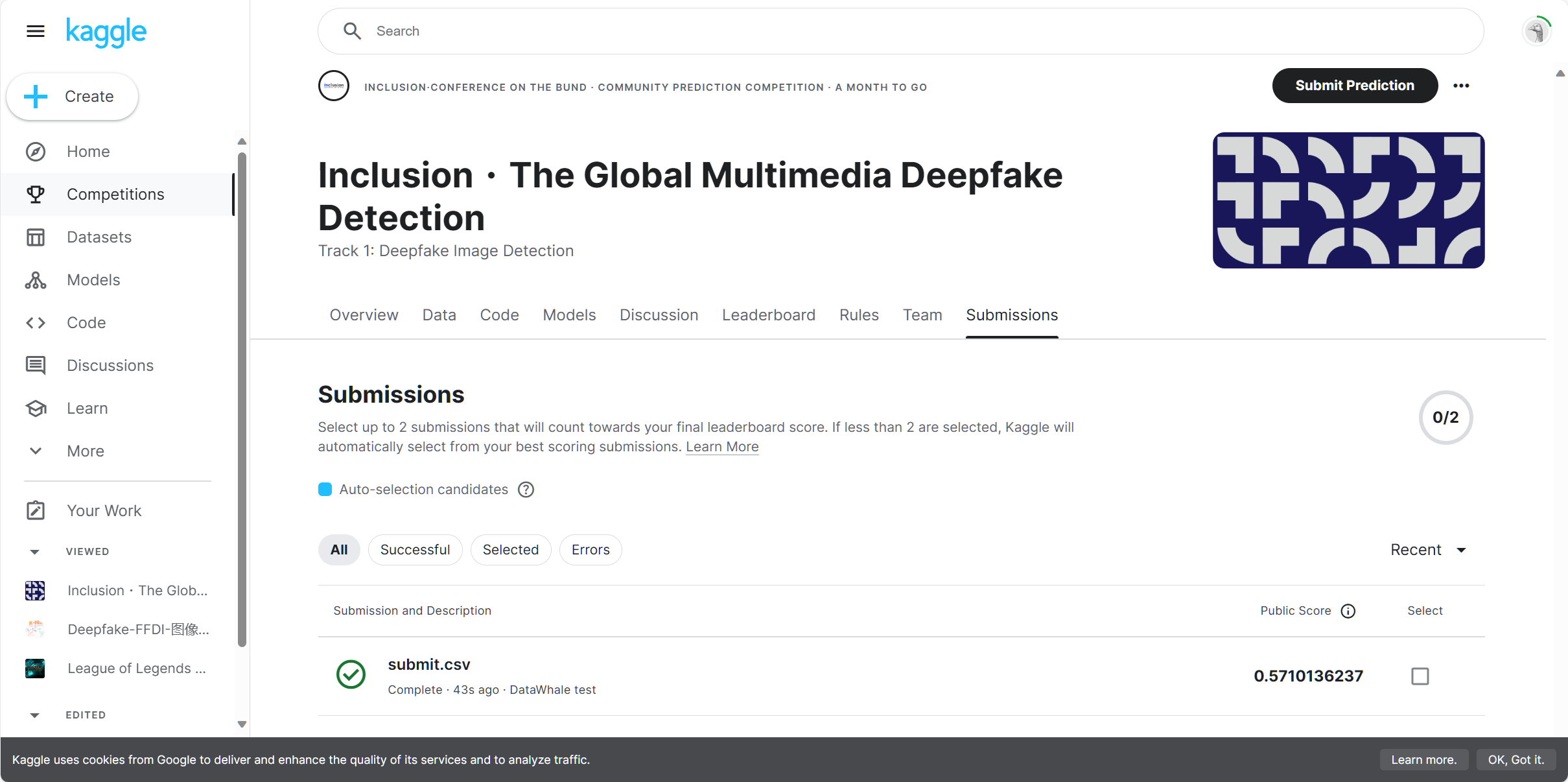
3 代码优化
通过学习九月大佬的代码 九月0.98\Deepfake-FFDI-Ways to Defeat 0.86 Beseline (kaggle.com),来学习代码优化。
更换预训练模型
import timm model = timm.create_model('efficientnet_b1', pretrained=True, num_classes=2) model = model.cuda() batch_size_value = 32 epochs = 2将Baseline的预训练模型从
resnet18模型改为efficientnet_b1,训练效果提升明显得到0.97的得分。