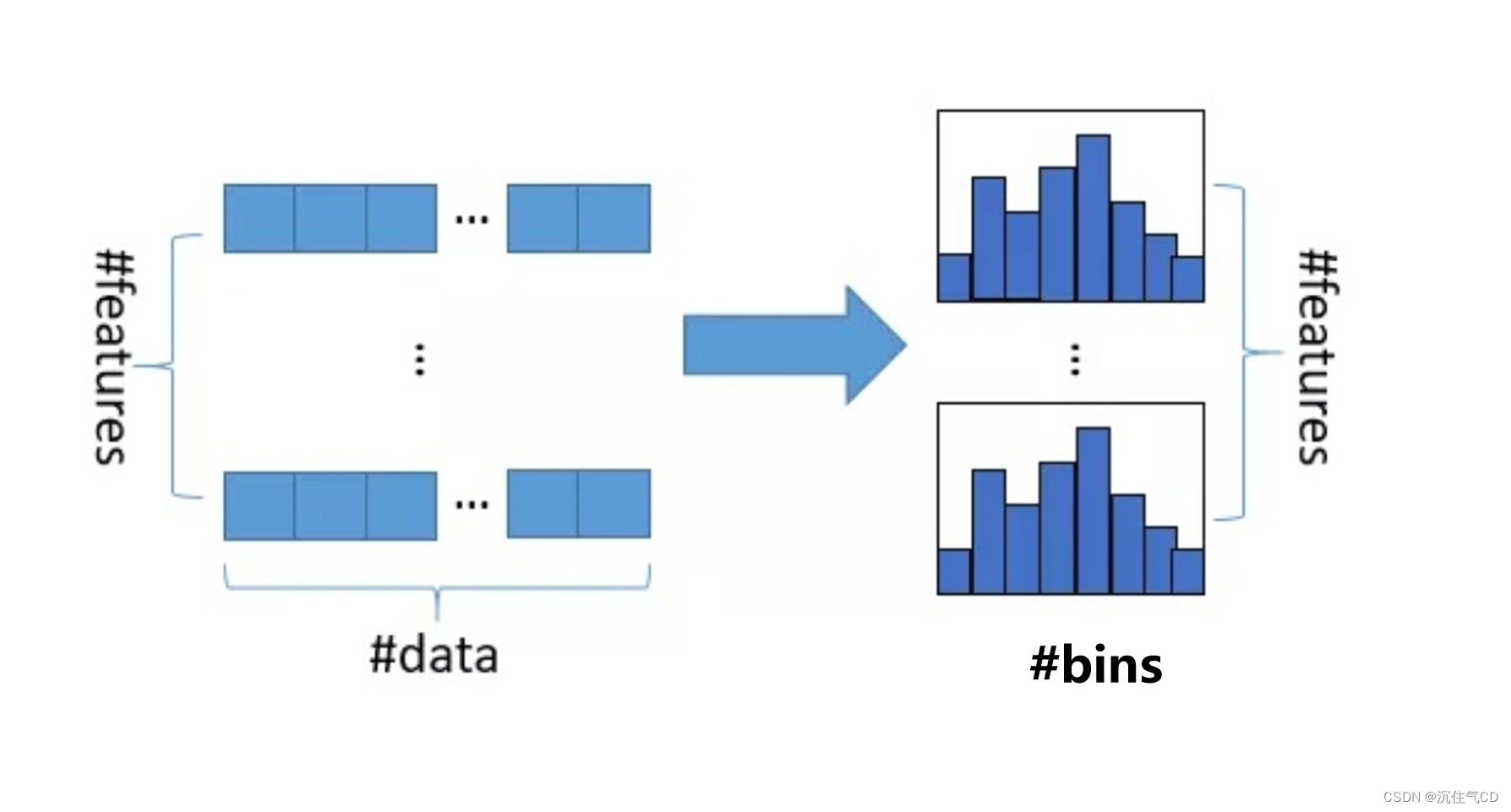
lightGBM
1.sklearn 使用代码
【机器学习基础】XGBoost、LightGBM与CatBoost算法对比与调参
首先,XGBoost、LightGBM和CatBoost都是目前经典的SOTA(state of the art)Boosting算法,都可以归类到梯度提升决策树算法系列。三个模型都是以决策树为支撑的集成学习框架,其中XGBoost是对原始版本的GBDT算法的改进,而LightGBM和CatBoost则是在XGBoost基础上做了进一步的优化,在精度和速度上都有各自的优点
数据处理:
# 导入pandas和sklearn数据划分模块
import pandas as pd
from sklearn.model_selection import train_test_split
# 读取flights数据集
flights = pd.read_csv('flights.csv')
# 数据集抽样1%
flights = flights.sample(frac=0.01, random_state=10)
# 特征抽样,获取指定的11个特征
flights = flights[["MONTH", "DAY", "DAY_OF_WEEK", "AIRLINE",
"FLIGHT_NUMBER","DESTINATION_AIRPORT", "ORIGIN_AIRPORT","AIR_TIME",
"DEPARTURE_TIME", "DISTANCE", "ARRIVAL_DELAY"]]
# 对标签进行离散化,延误10分钟以上才算延误
flights["ARRIVAL_DELAY"] = (flights["ARRIVAL_DELAY"]>10)*1
# 类别特征
cat_cols = ["AIRLINE", "FLIGHT_NUMBER", "DESTINATION_AIRPORT",
"ORIGIN_AIRPORT"]
# 类别特征编码
for item in cat_cols:
flights[item] = flights[item].astype("category").cat.codes +1
# 数据集划分
X_train, X_test, y_train, y_test = train_test_split(
flights.drop(["ARRIVAL_DELAY"], axis=1),
flights["ARRIVAL_DELAY"],
random_state=10, test_size=0.3)
# 打印划分后的数据集大小
print(X_train.shape, y_train.shape, X_test.shape, y_test.shape)
然后三个算法的使用示例,这里贴出lightGBM
# 导入lightgbm模块
import lightgbm as lgb
dtrain = lgb.Dataset(X_train, label=y_train)
params = {
"max_depth": 5,
"learning_rate" : 0.05,
"num_leaves": 500,
"n_estimators": 300
}
# 指定类别特征
cate_features_name = ["MONTH","DAY","DAY_OF_WEEK","AIRLINE",
"DESTINATION_AIRPORT", "ORIGIN_AIRPORT"]
# lightgbm模型拟合
model_lgb = lgb.train(params, d_train,
categorical_feature = cate_features_name)
# 对测试集进行预测
y_pred = model_lgb.predict(X_test)
print('AUC of testset based on XGBoost: 'roc_auc_score(y_test, y_pred))
示例的比较结果:

2.常用的超参数调优方法
机器学习模型中有大量需要事先进行人为设定的参数,比如说神经网络训练的batch-size,XGBoost等集成学习模型的树相关参数,我们将这类不是经过模型训练得到的参数叫做超参数(hyperparameter)。人为的对超参数调整的过程也就是我们熟知的调参。机器学习中常用的调参方法包括
网格搜索法(grid search)、
随机搜索法(random search)和
贝叶斯优化(bayesian optimization)。
### 首先网格搜索
主要是 要有
- param_list
- 使用from sklearn.model_selection import GridSearchCV 模块
- fit 超参数搜索搜索

随机搜索
随机搜索,顾名思义,即在指定的超参数范围或者分布上随机搜索和寻找最优超参数。相较于网格搜索方法,给定超参数分布内并不是所有的超参数都会进行尝试,而是会从给定分布中抽样一个固定数量的参数,实际仅对这些抽样到的超参数进行实验。相较于网格搜索,随机搜索有时候会是一种更高效的调参方法。Sklearn中通过model_selection模块下RandomizedSearchCV方法进行随机搜索。
替换为 RandomizedSearchCV
可以参考:https://blog.csdn.net/m0_55894587/article/details/130577242
贝叶斯调参
除了上述两种调参方法外,本小节介绍第三种,也有可能是最好的一种调参方法,即贝叶斯优化。贝叶斯优化是一种基于高斯过程(gaussian process)和贝叶斯定理的参数优化方法,近年来被广泛用于机器学习模型的超参数调优。
以后再了解
3. Battle of the Boosting Algos: LGB, XGB, Catboost
三种方法的具体评估,很好的示例代码和总结
https://lavanya.ai/2019/06/01/battle-of-the-boosting-algorithms/
https://www.kaggle.com/code/lavanyashukla01/battle-of-the-boosting-algos-lgb-xgb-catboost
4. lightGBM的中文文档
https://www.kaggle.com/code/lavanyashukla01/battle-of-the-boosting-algos-lgb-xgb-catboost
python包的使用:
读取数据:

训练和交叉验证:

提取停止训练和预测:
训练集上的指标在 eraly stop 轮没有提升后,停止训练

和xgboost对比试验:
试验代码demo:https://github.com/guolinke/boosting_tree_benchmarks

5.boosting 和 bagging 大概思想
随机森林 是 bagging算法,同时训练多个弱模型,可以有效减少方差。当 Bagging 方法无法有效发挥作用时,可能会导致所有分类器在同一区域内都产生错误的分类结果。
而Boosting 方法背后的直观理念是,我们需要串行地训练模型,而非并行。每个模型都应专注于之前分类器表现不佳的样本区域。相较于随机森林中各决策树的相互独立性,AdaBoost 展现出一种顺序训练的级联结构。在 AdaBoost 中,后续模型的训练基于前一个模型的预测结果,形成依赖关系。这种级联方式使 AdaBoost 更专注于解决之前未能正确预测的样本,逐步优化预测性能。AdaBoost 充分考虑了每个弱学习器的发言权,不同于随机森林的简单投票或计算平均值。
什么是Boosting?
Boosting是一种迭代的集成学习方法,其基本思想是通过串行训练多个弱学习器,并对每个学习器的预测结果进行加权组合,从而得到一个更强大的模型。与Bagging不同,Boosting是通过不断调整数据集的权重,使得后续的学习器重点关注之前学习器预测错误的样本,从而逐步提高整体模型的性能。
Boosting的步骤
Boosting的基本步骤如下:
初始化权重:开始时,将训练数据集中的每个样本赋予相等的权重。
训练弱学习器:在当前数据权重下训练一个弱学习器,例如决策树、神经网络等。
根据预测错误调整权重:根据当前弱学习器的预测结果,调整每个样本的权重。通常,被错误分类的样本将会获得更高的权重,而被正确分类的样本则会获得较低的权重。
更新模型:将当前学习器的预测结果与之前学习器的预测结果进行加权组合,得到最终的模型预测结果。
重复步骤2至4:重复以上步骤,直到达到预定的迭代次数或模型性能满足要求。
6. learning to rank, lightGBM
一般用在查询搜索应用中,输入一个文档,对数据库中的文档根据相关性进行排序。
L2R算法主要包括三种类别:PointWise,PairWise,ListWise。
什么意思呢?
PointWise 就是只考虑绝对相关度。 {文档的feature, 相关度} 进行训练,可以回归或者分类
PairWise 考虑一对文档的相关度排名, 输入任意一对文档,计算相关度的大小关系,{文档1feature, 文档2feature, 相关度关系}
listWise 考虑所有文档的相关度排名。计算整体的损失
更具体的解释,假如要对一个班级的学生进行排名,需要知道学生的各种特征:

先看
lightGBM用于排序(Learning to Rank )
https://github.com/jiangnanboy/learning_to_rank 里面有代码,博客,项目介绍等。
https://github.com/Ransaka/LTR-with-LIghtGBM
https://developer.baidu.com/article/details/3274567
NDCG指标
NDCG全称为 Normalized Discounted Cumulative Gain(归一化折损累计增益),通常用在搜索排序任务中,在这样的任务里,通常会返回一个list作为搜索排序的结果进行输出,为了验证这个list的合理性,就需要对这个list的排序进行评价。这也是NDCG的由来。

https://www.cnblogs.com/by-dream/p/9403984.html
参考:https://blog.csdn.net/weixin_42327752/article/details/125410386
7. 实例
https://www.kaggle.com/code/lavanyashukla01/battle-of-the-boosting-algos-lgb-xgb-catboost
写的很好,训练预测,参数搜索,以及模型分析等代码。
https://lavanya.ai/2019/06/01/battle-of-the-boosting-algorithms/
调参:
https://cloud.tencent.com/developer/article/1651704