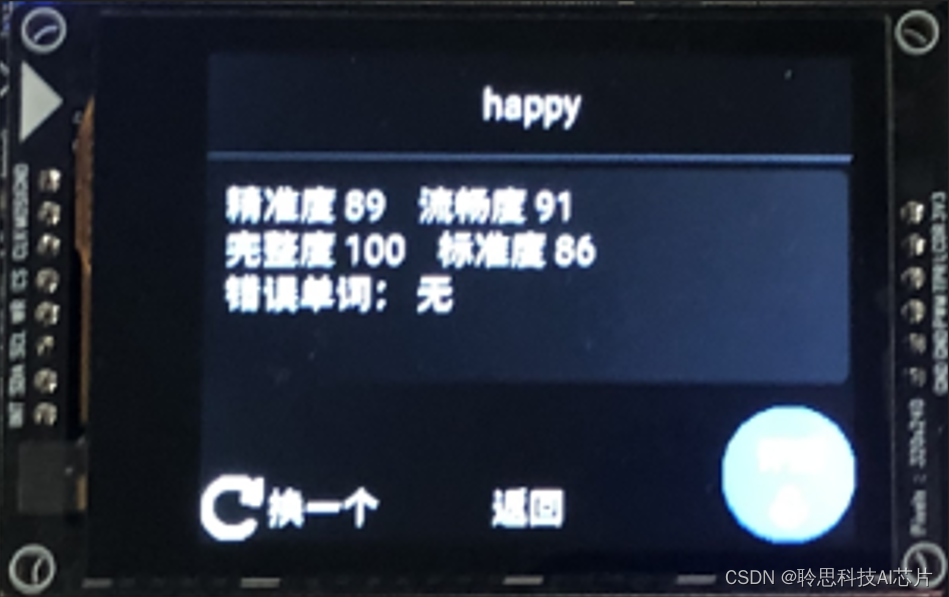
CV之Nougat:Nougat(一种基于神经网络实现OCR功能的视觉转换器模型)的简介、安装和使用方法、案例应用之详细攻略
目录
《Nougat: Neural Optical Understanding for Academic Documents》的翻译与解读
最后,创建一个包含所有图像路径、markdown文本和元信息的jsonl文件:
相关论文
《Nougat: Neural Optical Understanding for Academic Documents》的翻译与解读
地址 |
|
时间 |
2023年8月25日 |
作者 |
Meta AI |
摘要 |
科学知识主要存储在书籍和科学期刊中,通常以PDF格式存在。然而,PDF格式会导致语义信息的丢失,特别是对于数学表达式。我们提出了Nougat(Neural Optical Understanding for Academic Documents),这是一种视觉转换器模型,用于执行光学字符识别(OCR)任务,将科学文档处理成标记语言,并在新的科学文档数据集上展示了我们模型的有效性。所提出的方法为增强数字时代科学知识的可访问性提供了一个有前景的解决方案,通过弥合人类可读文档与机器可读文本之间的差距。我们发布了模型和代码,以加速未来对科学文本识别的工作。 |
总结 |
这篇文章提出了一种新的神经网络模型Nougat,它可以将学术论文转换为结构化标记文本。 背景:目前大多数科学知识都是以PDF格式存储在书籍或学术期刊中,但PDF格式会丧失一定的语义信息,尤其是数学表达式。 现有的OCR识别引擎,如Tesseract,可以识别和分类个别字符和词语,但因为它采用的是行识别的方式,因此无法理解字符之间的关系,对数学表达式识别效果不佳。 解决方案: >> Nougat模型采用视觉变换器架构,可以直接从论文页面图像输入进行识别,无需依赖OCR预处理。 >> 它使用Swin Transformer编码器提取论文图像特征,再通过解码器在自回归方式生成标记文本序列。 >> 训练时采用各种数据增强技术来提升泛化能力,如模糊、噪声等。 核心特点: >> 端到端学习,不需要任何OCR输入,直接使用论文页面图像进行识别。 >> 可以识别数字出版物以外的扫描书刊和教材。 >> 与现有方法相比,可以更好地还原数学表达式及其语义关系。 优势: >> 公开了预训练模型和代码,可促进相关领域未来工作。 >> 能够有效提升科学知识在数字时代的可访问性。 总之,Nougat提出了一种新的端到端神经网络方法来将学术论文转化为结构化标记文本,它直接使用论文图像作为输入,通过视觉变换器架构实现自动识别,解决了现有OCR方法在数学表达式识别上的不足,同时也提升了泛化能力。 |
Nougat的简介
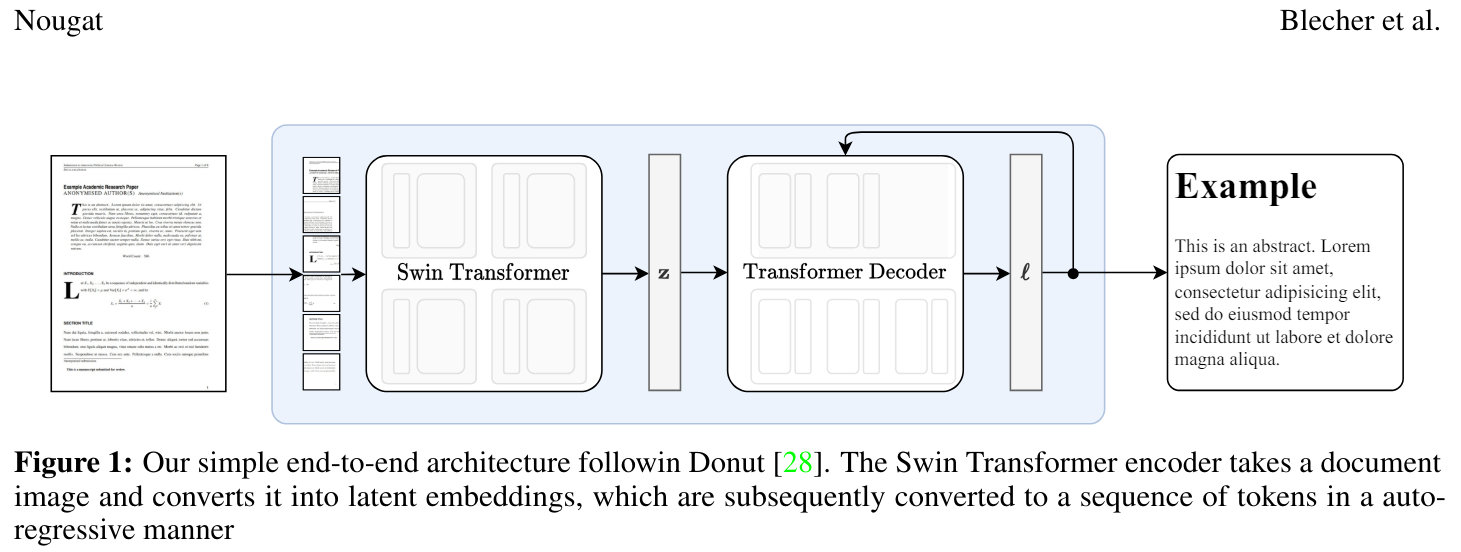
Nougat是学术文档的神经光学理解。这是Nougat的官方仓库,一个能够理解LaTeX数学和表格的学术文档PDF解析器。
GitHub地址:https://github.com/facebookresearch/nougat
项目页面: Nougat
Nougat的安装和使用方法
1、安装
通过pip安装:
pip install nougat-ocr
通过仓库安装:
pip install git+https://github.com/facebookresearch/nougat
注意,在Windows上:如果你想使用GPU,确保首先安装正确版本的PyTorch。按照此处的说明进行操作。
如果你想从API调用模型或生成数据集,需要额外的依赖项。通过以下方式安装:
pip install "nougat-ocr[api]" 或 pip install "nougat-ocr[dataset]"2、使用方法
(1)、获取PDF的预测
T1、命令行接口(CLI)
要获取PDF的预测,请运行:
$ nougat path/to/file.pdf -o output_directory
也可以传递一个目录的路径或每行是PDF路径的文件路径作为位置参数:
$ nougat path/to/directory -o output_directory
使用方法
nougat [-h] [--batchsize BATCHSIZE] [--checkpoint CHECKPOINT] [--model MODEL] [--out OUT]
[--recompute] [--markdown] [--no-skipping] pdf [pdf ...]
位置参数:
- pdf:要处理的PDF文件。
选项:
- -h, --help:显示帮助信息并退出
- --batchsize BATCHSIZE, -b BATCHSIZE:使用的批处理大小。
- --checkpoint CHECKPOINT, -c CHECKPOINT:检查点目录的路径。
- --model MODEL_TAG, -m MODEL_TAG:使用的模型标签。
- --out OUT, -o OUT:输出目录。
- --recompute:重新计算已计算的PDF,丢弃以前的预测。
- --full-precision:使用float32而不是bfloat16。在某些设置中可以加速CPU转换。
- --no-markdown:不添加markdown兼容性的后处理步骤。
- --markdown:添加markdown兼容性的后处理步骤(默认)。
- --no-skipping:不应用失败检测启发式方法。
- --pages PAGES, -p PAGES:提供页码,例如'1-4,7'表示第1到4页和第7页。仅适用于单个PDF。
默认的模型标签是0.1.0-small。如果你想使用基础模型,请使用0.1.0-base。
$ nougat path/to/file.pdf -o output_directory -m 0.1.0-base在输出目录中,每个PDF将保存为.mmd文件,这是一种轻量级标记语言,大部分兼容Mathpix Markdown(我们使用LaTeX表格)。
注意:在某些设备上,失败检测启发式方法工作不正常。如果你遇到大量的[MISSING_PAGE]响应,尝试使用--no-skipping标志运行。相关问题:#11, #67
T2、API
使用额外的依赖项,你可以使用app.py启动一个API。调用:
$ nougat_api通过向http://127.0.0.1:8503/predict/发送POST请求来获取PDF文件的预测。它还接受start和stop参数来限制计算的页码(包含边界)。
响应是文档的markdown文本字符串。
curl -X 'POST' \
'http://127.0.0.1:8503/predict/' \
-H 'accept: application/json' \
-H 'Content-Type: multipart/form-data' \
-F 'file=@<PDFFILE.pdf>;type=application/pdf'
要将转换限制在第1到5页,请在请求URL中使用start/stop参数:http://127.0.0.1:8503/predict/?start=1&stop=5
(2)、数据集
生成数据集
要生成数据集,你需要:
>> 包含PDF的目录
>> 包含.html文件(由LaTeXML处理的.tex文件)的目录,具有相同的文件夹结构
>> pdffigures2的二进制文件和相应的环境变量 export PDFFIGURES_PATH="/path/to/binary.jar"
然后运行:
python -m nougat.dataset.split_htmls_to_pages --html path/html/root --pdfs path/pdf/root --out path/paired/output --figure path/pdffigures/outputs其他参数包括:
| 参数 | 描述 |
|---|---|
| --recompute | 重新计算所有拆分 |
| --markdown | MARKDOWN 输出目录 |
| --workers | WORKERS 使用的进程数 |
| --dpi | DPI 保存页面的分辨率 |
| --timeout | TIMEOUT 每篇论文的最大时间 |
| --tesseract | Tesseract 每页的OCR预测 |
最后,创建一个包含所有图像路径、markdown文本和元信息的jsonl文件:
python -m nougat.dataset.create_index --dir path/paired/output --out index.jsonl
对于每个jsonl文件,你还需要生成一个快速数据加载的索引映射:
python -m nougat.dataset.gen_seek file.jsonl生成的目录结构可以如下所示:
root/
├── images
├── train.jsonl
├── train.seek.map
├── test.jsonl
├── test.seek.map
├── validation.jsonl
└── validation.seek.map
注意,路径/配对/输出中的.mmd和.json文件(此处为images)不再需要。这对于通过减少一半文件数量推送到S3存储桶很有用。
(3)、训练
要训练或微调Nougat模型,运行:
python train.py --config config/train_nougat.yaml
(4)、评估
运行:
python test.py --checkpoint path/to/checkpoint --dataset path/to/test.jsonl --save_path path/to/results.json
要获取不同文本模式的结果,运行:
python -m nougat.metrics path/to/results.json3、常见问题
为什么我只得到[MISSING_PAGE]?
Nougat是在arXiv和PMC上找到的科学论文上训练的。你正在处理的文档是否与此相似?文档的语言是什么?Nougat对英文论文效果最佳,其他拉丁语系语言可能也有效。中文、俄文、日文等则无效。如果这些要求都满足,可能是由于CPU或较旧的GPU上失败检测的误报(#11)。目前尝试传递--no-skipping标志。
我可以从哪里下载模型检查点?
它们已上传到GitHub的发布部分。你也可以在程序第一次执行时下载它们。通过传递--model 0.1.0-{base,small}选择首选模型。
Nougat的案例应用
持续更新中……
























![[经验] 白怎么写好看-如何优美地书写白色字体 #微信#笔记#媒体](https://img-home.csdnimg.cn/images/20230724024159.png?origin_url=https%3A%2F%2Fwww.hao123rr.com%2Fzb_users%2Fcache%2Fly_autoimg%2F%25E7%2599%25BD%25E6%2580%258E%25E4%25B9%2588%25E5%2586%2599%25E5%25A5%25BD%25E7%259C%258B-%25E5%25A6%2582%25E4%25BD%2595%25E4%25BC%2598%25E7%25BE%258E%25E5%259C%25B0%25E4%25B9%25A6%25E5%2586%2599%25E7%2599%25BD%25E8%2589%25B2%25E5%25AD%2597%25E4%25BD%2593.jpg&pos_id=H57BsgYx)