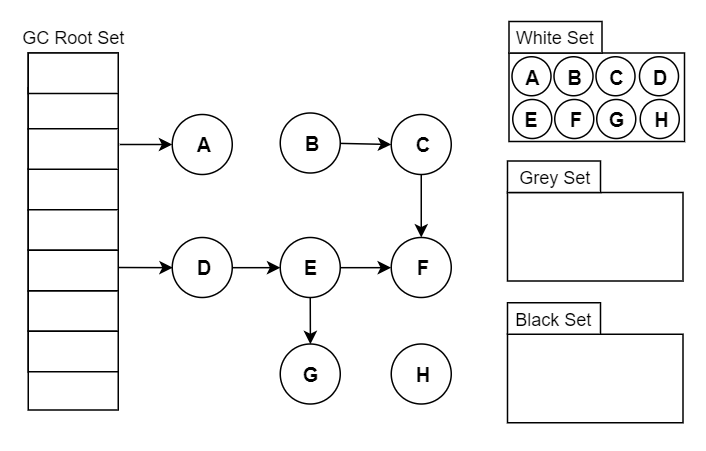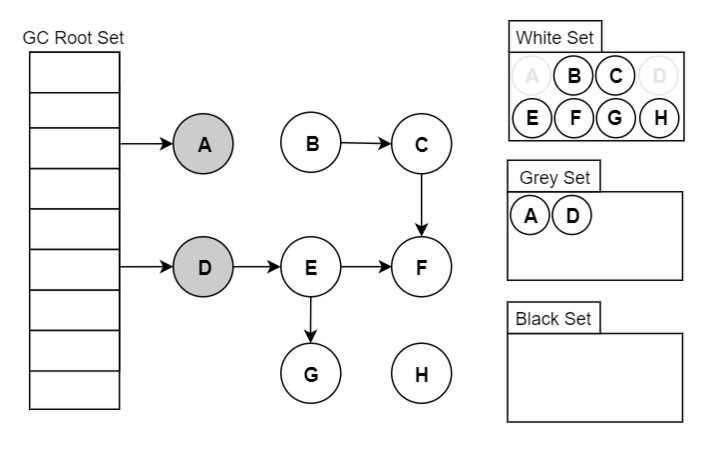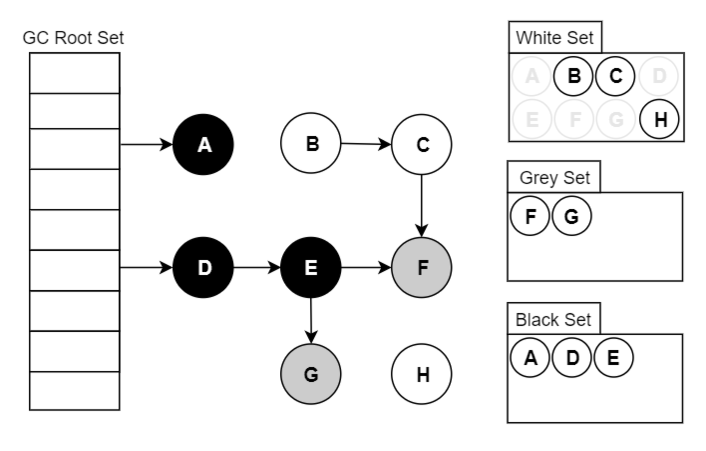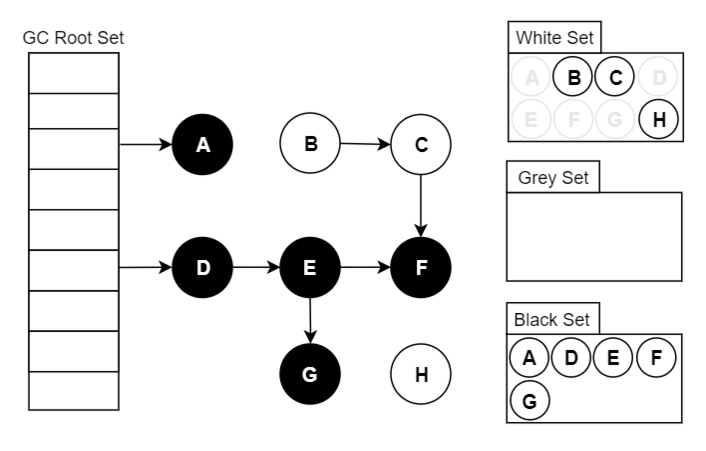
前言
最近在学习的过程中遇到如何应对海量幂等 Key 所消耗的内存的问题,在网上查找资料了解到Cassandra或许是解决方式之一,所以查找了Cassandra的相关资料及其Cassandra和redis的区别。
什么是Cassandra
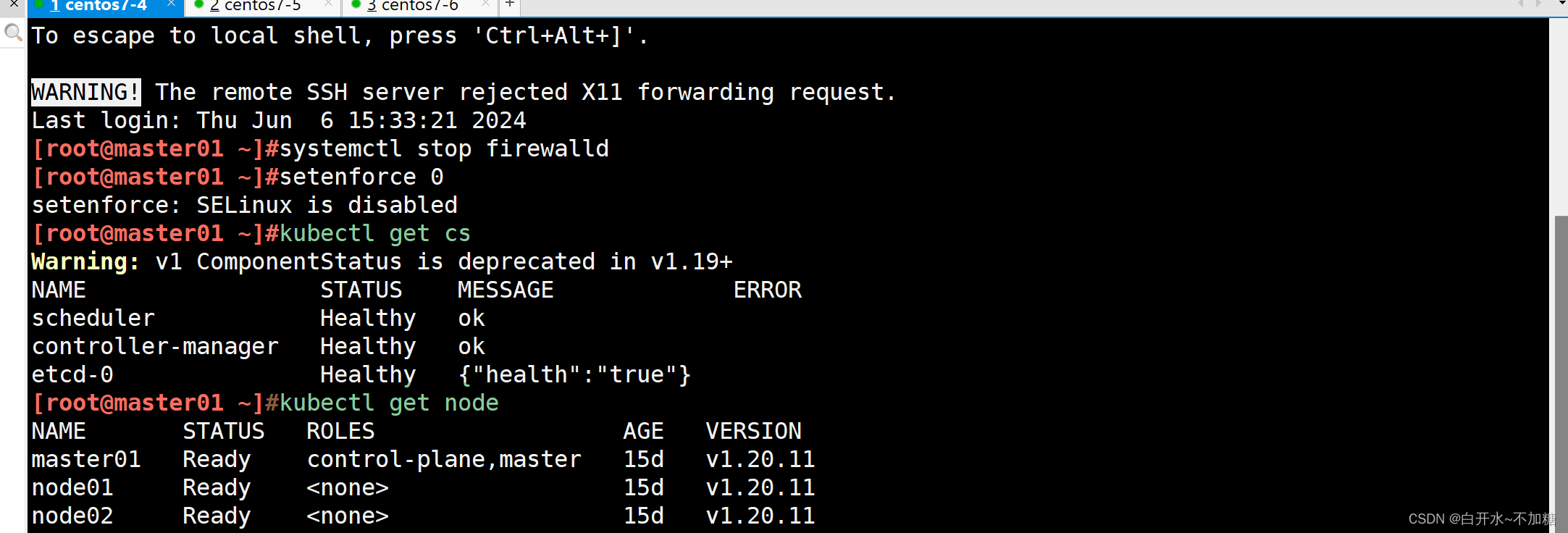
Cassandra 是一个开源的分布式 NoSQL 数据库管理系统,由 Apache 软件基金会开发。它专为处理大量数据而设计,具有高可用性、无单点故障、可横向扩展等特点,非常适合用于大规模、高并发的应用场景。以下是对 Cassandra 的详细介绍:
核心特点
高可用性和无单点故障
- Cassandra 采用分布式架构,每个节点都是对等的,没有主节点和从节点的区别。
- 数据通过分片和复制分布在多个节点上,即使某些节点发生故障,数据仍然可以通过其他节点访问。
线性可扩展性
- Cassandra 可以通过添加更多的节点来水平扩展。新增节点后,数据会自动重新分布,不会影响系统的正常运行。
灵活的数据模型
- Cassandra 支持基于表的模式,类似于关系型数据库,但没有严格的模式要求。
- 它支持动态添加列,非常适合处理半结构化和非结构化数据。
高写入吞吐量
- Cassandra 采用 LSM-Tree(Log-Structured Merge-Tree)存储结构,优化了写操作的性能。
- 数据写入首先进入内存,然后定期刷新到磁盘,减少了写操作的磁盘 I/O 负担。
强一致性与最终一致性
- Cassandra 允许配置数据一致性级别,可以在强一致性和最终一致性之间进行权衡。
架构与数据分布
集群和节点
- 一个 Cassandra 集群包含多个节点,节点之间通过 Gossip 协议进行通信,交换元数据和状态信息。
- 集群中的数据通过一致性哈希算法分布到各个节点上,每个节点存储一部分数据。
数据复制
- Cassandra 支持多副本机制,每份数据会复制到多个节点上,以确保数据的高可用性。
- 复制因子(Replication Factor)决定了每份数据的副本数量。
数据模型
- 数据模型由键空间(Keyspace)和表(Table)组成。
- 键空间是逻辑上管理数据的容器,类似于关系数据库中的数据库。
- 表是数据存储的基本单位,类似于关系数据库中的表。
数据读写流程
写操作
- 写操作首先写入内存表(Memtable)和提交日志(Commit Log)。
- 当 Memtable 达到一定大小时,会将数据刷入 SSTable(Sorted String Table),即磁盘上的数据文件。
读操作
- 读操作会优先从缓存(Row Cache、Key Cache)中读取数据。
- 如果缓存未命中,会从 Memtable 和 SSTable 中查找数据。
- SSTable 的数据按顺序存储,查找效率高。
配置与管理
一致性级别
- Cassandra 提供多种一致性级别,如
ONE、QUORUM、ALL等,用户可以根据需求选择合适的一致性级别。
- Cassandra 提供多种一致性级别,如
故障检测与恢复
- Cassandra 采用 Gossip 协议进行故障检测,节点间定期交换状态信息。
- 当检测到节点故障时,Cassandra 会自动将数据请求路由到其他可用节点。
负载均衡
- 新增节点后,Cassandra 会自动进行负载均衡,将部分数据迁移到新节点上。
使用场景
Cassandra 非常适合以下应用场景:
高写入和高读取需求
- 例如,实时分析、日志管理、物联网数据收集等。
大规模分布式系统
- 例如,内容管理系统、推荐系统、社交媒体平台等。
地理分布的数据中心
- 例如,全球分布的应用需要高可用性和低延迟的数据访问。
示例代码
以下是使用 Java 连接 Cassandra 的示例代码:
import com.datastax.oss.driver.api.core.CqlSession;
import com.datastax.oss.driver.api.core.cql.ResultSet;
import com.datastax.oss.driver.api.core.cql.SimpleStatement;
public class CassandraExample {
public static void main(String[] args) {
try (CqlSession session = CqlSession.builder().build()) {
// 创建键空间
session.execute("CREATE KEYSPACE IF NOT EXISTS test WITH replication = {'class':'SimpleStrategy', 'replication_factor':1}");
// 使用键空间
session.execute("USE test");
// 创建表
session.execute("CREATE TABLE IF NOT EXISTS users (id UUID PRIMARY KEY, name TEXT, age INT)");
// 插入数据
session.execute("INSERT INTO users (id, name, age) VALUES (uuid(), 'Alice', 30)");
// 查询数据
ResultSet resultSet = session.execute("SELECT * FROM users");
resultSet.forEach(row -> {
System.out.println("ID: " + row.getUuid("id"));
System.out.println("Name: " + row.getString("name"));
System.out.println("Age: " + row.getInt("age"));
});
}
}
}
Cassandra 和 Redis 都是流行的 NoSQL 数据库,但它们在设计目标、架构、数据模型和应用场景上有显著不同。以下是对 Cassandra 和 Redis 的详细比较:
Cassandra 的特点和优势
分布式架构
- 去中心化的对等架构:Cassandra 采用无主架构,所有节点都是对等的,没有主节点和从节点的区别。这种架构使得 Cassandra 天然支持高可用性和无单点故障。
- 高可扩展性:可以通过添加节点来水平扩展,数据自动在节点之间分片和复制,确保扩展过程中无停机。
- 高写入性能:优化了写操作,适合写密集型应用。
数据模型
- 列族存储模型:Cassandra 使用列族(Column Family)存储数据,每个列族包含多个行和列,适合处理大规模、稀疏的数据集。
- 灵活的模式:允许动态添加列,数据模式非常灵活。
一致性和容错性
- 可配置的强一致性和最终一致性:用户可以根据需求选择不同的一致性级别,从强一致性到最终一致性。
- 复制因子和数据分布:数据通过一致性哈希算法分布到多个节点上,并根据复制因子进行多副本存储,保证数据的高可用性和容错性。
适用场景
- 大数据处理和实时分析:适用于需要高写入和读取性能的应用,如实时分析、物联网数据收集、大数据存储等。
- 地理分布的系统:支持跨数据中心部署,适合全球分布的应用。
Redis 的特点和优势
内存存储
- 高性能:Redis 是一个内存数据库,数据存储在内存中,读写速度非常快,适合高吞吐量和低延迟的应用。
- 丰富的数据结构:支持多种数据结构,包括字符串、哈希、列表、集合、有序集合、位图和 HyperLogLog 等。
单线程架构
- 简化并发控制:Redis 采用单线程模型,避免了复杂的并发控制,提高了性能和稳定性。
持久化机制
- RDB 和 AOF:Redis 提供两种持久化机制,RDB(快照)和 AOF(Append-Only File),用户可以根据需求选择合适的持久化方式。
适用场景
- 缓存和会话存储:Redis 的高性能使其非常适合作为缓存层,提升系统的响应速度。也常用于会话存储、排行榜、实时统计等场景。
- 消息队列:Redis 可以通过列表和发布/订阅机制实现高效的消息队列。
具体比较
| 特性 | Cassandra | Redis |
|---|---|---|
| 架构 | 分布式无主架构,所有节点对等 | 单线程,多实例分片 |
| 存储模型 | 列族存储,支持稀疏数据 | 内存存储,支持多种数据结构 |
| 数据一致性 | 可配置强一致性和最终一致性 | 单节点强一致性,多节点需要自己实现一致性 |
| 扩展性 | 水平扩展,通过增加节点自动扩展 | 通过分片机制扩展,但不如 Cassandra 自然 |
| 写入性能 | 高写入性能,适合写密集型应用 | 高写入性能,适合高频读写 |
| 读性能 | 读取性能良好,但取决于节点的分布和复制策略 | 读取性能极高,但受限于内存大小 |
| 持久化 | 内置持久化,适合长期存储大规模数据 | 提供 RDB 和 AOF 持久化机制,但主要用于缓存场景 |
| 容错性 | 高容错性,数据多副本存储,节点故障自动恢复 | 高容错性,通过主从复制和哨兵机制保证数据可用性 |
| 适用场景 | 大数据处理、实时分析、地理分布系统、物联网等 | 缓存、会话存储、消息队列、实时统计等 |
选择建议
- 选择 Cassandra:如果你的应用需要处理大规模数据,并且对写入性能要求高,或者需要跨数据中心的分布式部署,那么 Cassandra 是一个合适的选择。
- 选择 Redis:如果你的应用需要极高的读写性能,主要用于缓存、会话存储或实时统计等场景,并且数据规模可以完全放在内存中,那么 Redis 是一个理想的选择。
总结
Cassandra 和 Redis 各有优势,适用于不同的应用场景。Cassandra 更适合处理大规模、分布式的数据存储和高写入性能的应用,而 Redis 则因其高性能和丰富的数据结构,广泛用于缓存、会话存储和实时数据处理。选择合适的数据库取决于具体的业务需求和数据特性。



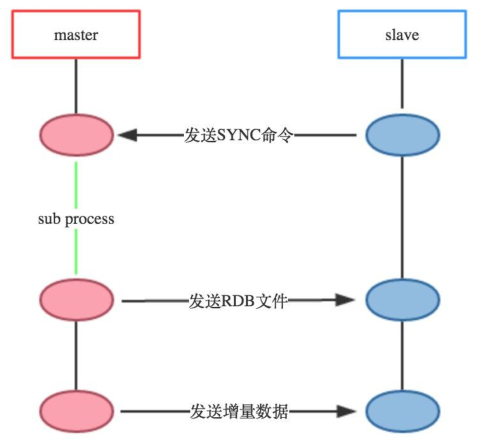




















![[经验] 白怎么写好看-如何优美地书写白色字体 #微信#笔记#媒体](https://img-home.csdnimg.cn/images/20230724024159.png?origin_url=https%3A%2F%2Fwww.hao123rr.com%2Fzb_users%2Fcache%2Fly_autoimg%2F%25E7%2599%25BD%25E6%2580%258E%25E4%25B9%2588%25E5%2586%2599%25E5%25A5%25BD%25E7%259C%258B-%25E5%25A6%2582%25E4%25BD%2595%25E4%25BC%2598%25E7%25BE%258E%25E5%259C%25B0%25E4%25B9%25A6%25E5%2586%2599%25E7%2599%25BD%25E8%2589%25B2%25E5%25AD%2597%25E4%25BD%2593.jpg&pos_id=H57BsgYx)