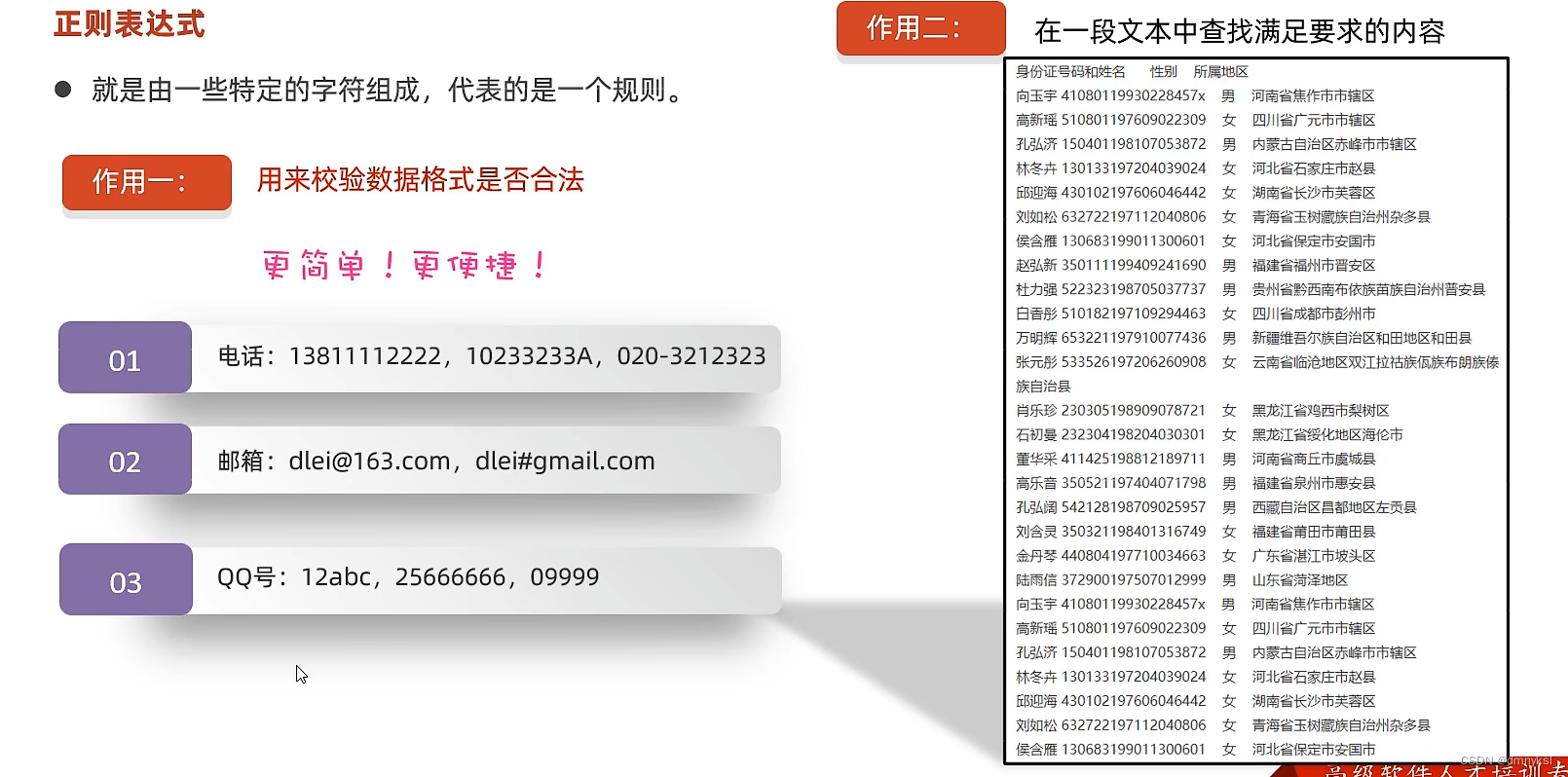
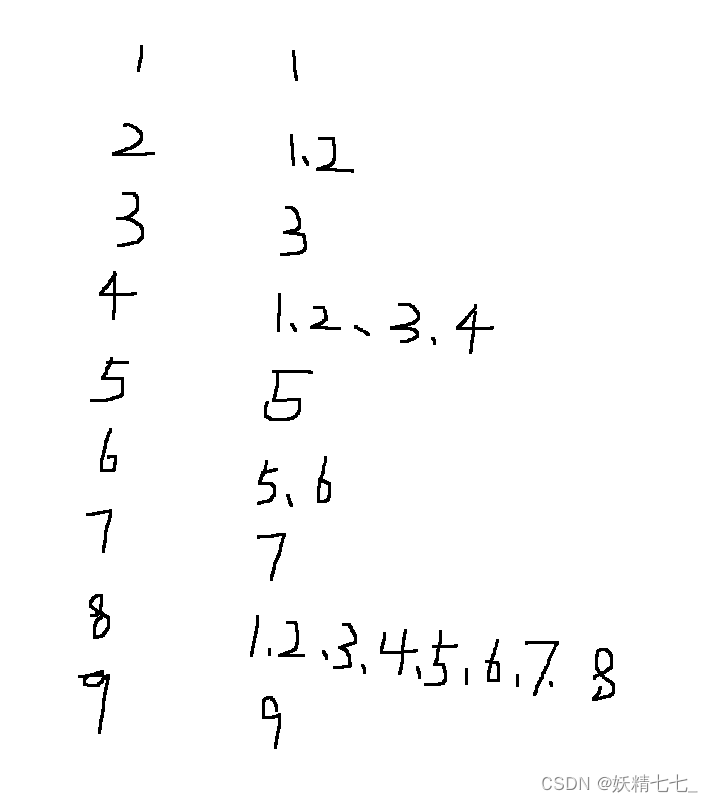正则表达式是用于匹配字符串中字符组合的模式。它们在JavaScript和许多其他编程语言中用于搜索、替换和验证操作。
正则表达式的语法有许多元素,这里是一些基本和常用的:
字面量字符:包括所有非特殊字符,会精确匹配这些字符。
点(
.):匹配除换行符之外的任意单个字符。转义符(
\):用于转义一个特殊字符,让其被当作字面量处理,或者用于表示一个特殊序列。字符类:
[abc]:匹配任何包含的字符(如a、b或c)。[^abc]:匹配任何不在括号中的字符。[a-z]:匹配a到z的任意小写字母。[A-Z]:匹配A到Z的任意大写字母。[0-9]:匹配任何数字。
预定义的字符类:
\d:匹配任何数字(等同于[0-9])。\D:匹配任何非数字字符(等同于[^0-9])。\w:匹配任何字母数字字符,包括下划线(等同于[A-Za-z0-9_])。\W:匹配任何非单词字符(等同于[^A-Za-z0-9_])。\s:匹配任何空白字符(包括空格、制表符、换页符等)。\S:匹配任何非空白字符。
量词:
*:匹配前面的元素零次或多次。+:匹配前面的元素一次或多次。?:匹配前面的元素零次或一次。{n}:匹配前面的元素恰好n次。{n,}:匹配前面的元素至少n次。{n,m}:匹配前面的元素至少n次,但不超过m次。
锚点:
^:匹配字符串的开头或在多行模式中的行开头。$:匹配字符串的结尾或在多行模式中的行结尾。\b:匹配单词边界。\B:匹配非单词边界。
分组和引用:
(abc):匹配abc,并将其作为一个组。(a|b):匹配a或b。(?<name>abc):命名捕获组。\1:引用第一个捕获组。
非捕获组:
(?:abc):匹配abc,但不作为捕获组。
前瞻和后顾:
(?=abc):正向前瞻,匹配后面是abc的位置。(?!abc):负向前瞻,匹配后面不是abc的位置。(?<=abc):正向后顾,匹配前面是abc的位置。(?<!abc):负向后顾,匹配前面不是abc的位置。
这些元素可以组合和嵌套来创建复杂的匹配模式。正则表达式的能力非常强大,但也可能难以阅读,因此在使用它们时编写清晰和维护的代码非常重要。