云原生环境下GPU算力调度深度分析
概述:
云原生时代,GPU算力调度与管理备受瞩目,成为企业和云服务提供商关注的焦点,助力AI、深度学习、高性能计算等领域,满足对GPU资源的迫切需求。
- 容器化与编排:
- Kubernetes(K8s)强效集成GPU资源调度,通过NVIDIA等Device Plugin机制精准识别与分配GPU。用户轻松在Pod定义中指定GPU设备及显存需求,实现高效资源利用。Kubernetes以其卓越的扩展性,为容器化应用提供强大的GPU支持。
- 资源调度策略:
- 智能调度精准高效:基于GPU型号、内存、计算能力、网络带宽等,智能分配任务至最佳GPU节点,大幅提升执行效率。
- 拓扑感知调度优化GPU性能,通过高级调度器支持GPU拓扑结构,有效利用NVIDIA NVLink等高速互连,大幅减少跨GPU数据传输延时,显著提升计算效率。
- 资源隔离与共享:
- MIG技术实现GPU多实例化,精细划分GPU为独立计算单元,为各应用提供细粒度资源隔离与共享,确保高效、安全的虚拟化体验。
- 弹性伸缩与负载均衡:
- 自动化扩缩容解决方案:借助Kubernetes的Horizontal Pod Autoscaler或自研autoscaler插件,依据GPU负载智能调整资源,实现高效利用,自动增减GPU资源,确保性能与成本的完美平衡。
- 资源预留与智能调度:设定GPU资源预留策略,保障关键任务稳定运行,支持高优先级任务智能抢占低优先级资源。
- 监控与优化:
- 云服务提供商产品与方案:
- 阿里云、腾讯云、AWS、Google Cloud、Azure等云服务商均提供云原生GPU计算服务,涵盖弹性GPU实例、优化型容器及虚拟化等方案,为企业客户带来便捷高效的GPU算力使用体验。
云原生GPU算力调度与管理方案,全面涵盖硬件适配、资源调度、智能优化与上层服务化,为企业提供高效稳定的GPU计算能力。持续的技术创新,驱动AI与高性能计算应用迈向新高度,为企业带来无限可能。
以下是深度分析:
01 GPU介绍
GPU以多核心、高速内存为特色,擅长并行处理,广泛应用于深度学习、图形处理与科学计算。主要厂商有NVIDIA、AMD等,其性能关键指标涵盖核心数量与内存速度。
02 Kubernetes管理GPU
随着AI技术的飞速发展,GPU需求激增。在资源管理中,Kubernetes已成为主流标准,众多客户选择利用其在Kubernetes中运行AI任务。为高效管理GPU资源,Kubernetes采用插件扩展机制,包括两个核心内部机制,确保AI计算在Kubernetes集群中的顺畅运行。
- Extend Resources功能强大,支持用户自定义资源名称及整数度量,为RDMA、FPGA、GPU等异构设备提供统一支持。上报此类资源仅需通过PATCH API更新Node对象状态,操作简便,仅需一行curl命令即可完成,如下:
```bash
curl -X PATCH ...
```
轻松扩展资源,高效管理异构设备。
# 启动 Kubernetes 的客户端 proxy,这样你就可以直接使用 curl 来跟 Kubernetes 的 API Server 进行交互了 $ kubectl proxy
# 执行 PACTH 操作 $ curl --header "Content-Type: application/json-patch+json" \ --request PATCH \ --data '[{"op": "add", "path": "/status/capacity/nvidia.com/gpu", "value": "1"}]' \ http://localhost:8001/api/v1/nodes/<your-node-name>/status
apiVersion: v1, Node资源状态精简呈现:CPU容量2核,内存高达2GB(2049008K),并配备invidia.com/gpu资源1个,满足您的多元计算需求。
- Device Plugin:Kubernetes的设备插件框架,专为GPU、FPGA及高性能NIC等第三方设备设计。通过遵循Device Plugin接口规范,轻松创建特定设备插件,实现Kubernetes对设备的无缝管理。简化配置,提升性能,助力您的云计算之旅更加高效顺畅。
设备插件API接口定义于pkg/kubelet/apis/deviceplugin/v1beta1/api.pb.go文件第567行,专业、精简,满足高效设备交互需求。
type DevicePluginServer interface {// GetDevicePluginOptions returns options to be communicated with Device// Manager GetDevicePluginOptions(context.Context, *Empty) (*DevicePluginOptions, error)// ListAndWatch returns a stream of List of Devices// Whenever a Device state change or a Device disappears, ListAndWatch// returns the new list ListAndWatch(*Empty, DevicePlugin_ListAndWatchServer) error// Allocate is called during container creation so that the Device// Plugin can run device specific operations and instruct Kubelet// of the steps to make the Device available in the container Allocate(context.Context, *AllocateRequest) (*AllocateResponse, error)// PreStartContainer is called, if indicated by Device Plugin during registeration phase,// before each container start. Device plugin can run device specific operations// such as reseting the device before making devices available to the container PreStartContainer(context.Context, *PreStartContainerRequest) (*PreStartContainerResponse, error) }
- ListAndWatch:DevicePlugin一经启动并向Kubelet注册,即触发Kubelet调用其API实时获取设备信息。这一长连接机制确保设备状态实时更新,一旦健康状况变动,DevicePlugin会主动推送最新信息至Kubelet,确保系统始终保持最新设备状态感知。
- Kubelet在创建需特定设备的容器时,通过API高效分配资源,迅速提供设备列表、环境变量及挂载点等关键信息,确保容器顺利获得所需设备资源。
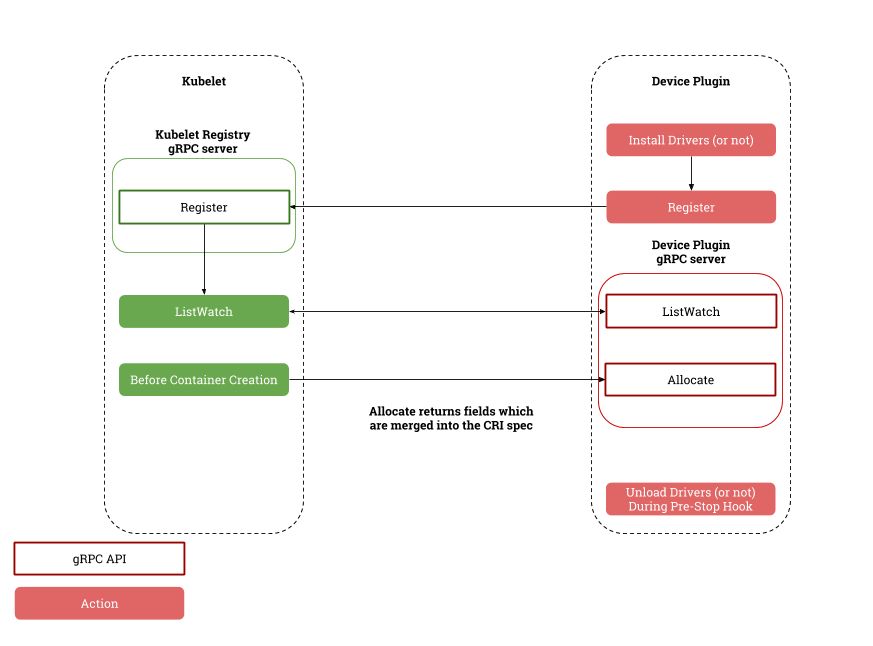
Device Plugin 与 Kubelet 交互过程
目前主流的GPU厂商都提供了对应的设备插件,如NVIDIA提供的Device Plugin (https://github.com/NVIDIA/k8s-device-plugin)。安装了插件,集群就会暴露一个自定义可调度的资源,例如 amd.com/gpu 或 nvidia.com/gpu。可以通过请求这个自定义的 GPU 资源在你的容器中使用这些 GPU,其请求方式与请求 cpu 或 memory 时相同。不过,在如何指定自定义设备的资源请求方面存在一些限制:
GPU 只能在limits部分指定,这意味着:
- 在Kubernetes中,设置GPU的`limits`时,即使不指定`requests`,系统将默认以`limits`为请求值,简化配置,提升效率。
- 你不可以仅指定 `requests` 而不指定 `limits`。
以下是一个 Pod 请求 GPU 的示例清单:
apiVersion: v1kind: Podmetadata:name: example-vector-addspec:restartPolicy: OnFailurecontainers:- name: example-vector-addimage: "registry.example/example-vector-add:v42"resources:limits:gpu-vendor.example/example-gpu: 1 # 请求 1 个 GPU
利用Kubernetes中的厂商Device Plugin插件,高效管理GPU资源,但仍有诸多不便与局限,需持续优化以提升体验。
- 资源调度不够灵活,只支持按较粗粒度的调度,按 GPU 块数调度。
- GPU不能共享,算力不能切分,这样会导致GPU算力的浪费。
- 集群GPU资源缺乏全局概览,难以直观获取集群GPU信息,如Pod/容器与GPU绑定关系、已使用GPU数量等关键数据,限制了资源管理和优化。
接下来介绍业内的一些GPU算力共享方案。
03 业内共享GPU算力方案
3.1 阿里GPU Share Device Plugin
实现思路:
通过Kubernetes的Extended Resource机制,我们精确定义了GPU资源,涵盖显存和数量,实现高效资源管理和利用。
通过Device Plugin机制,我们精准地在节点上报告GPU卡数量及总显存容量(数量×显存),确保kubelet实时更新至Kubernetes API Server,为资源调度提供精准数据支持。
通过k8s scheduler Extender机制,我们增强了调度器的功能。在全局调度过程中,Filter和Bind阶段均精准判断节点GPU显存是否满足需求。特别地,在Bind时,我们实时将GPU分配结果以annotation形式记录至Pod Spec,确保后续Filter能准确检查分配状态,实现资源的高效利用与管理。
使用示例
apiVersion: apps/v1beta1kind: StatefulSet
metadata: name: binpack-1labels: app: binpack-1spec: replicas: 3serviceName: "binpack-1"podManagementPolicy: "Parallel"selector: # define how the deployment finds the pods it managesmatchLabels: app: binpack-1 template: # define the pods specificationsmetadata: labels: app: binpack-1 spec: containers: - name: binpack-1image: cheyang/gpu-player:v2resources: limits: # GiB aliyun.com/gpu-mem: 3
优点:开源,使用简单。
不足之处:不支持共享资源的隔离,存在资源抢占情况;不支持算力维度的衡量划分。
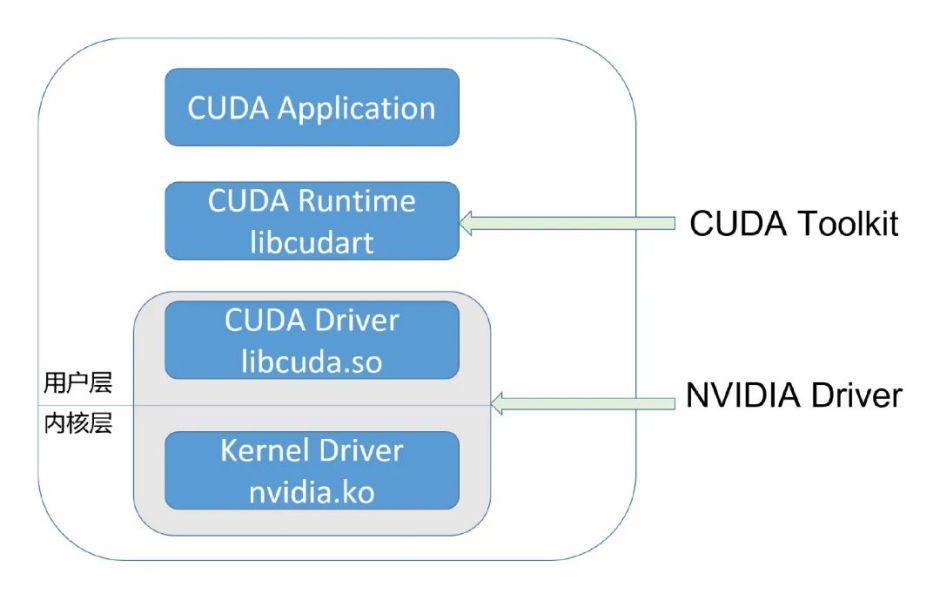
GPU应用调用链
- 截获CUDA库转发,如vCUDA。
- 截获驱动转发,如阿里云cGPU、腾讯云qGPU。
- 截获GPU硬件访问,如NVIDIA GRID vGPU。
3.2 阿里cGPU
cGPU,阿里云创新推出的容器共享技术,基于内核虚拟GPU隔离,实现多容器共享单GPU卡。这一技术不仅确保业务安全隔离,更显著提升GPU资源利用率,降低使用成本。cGPU通过内核驱动为容器提供虚拟GPU设备,实现显存与算力隔离,配合轻量用户态运行库,轻松配置容器内虚拟GPU,为您的业务带来前所未有的高效与便捷。
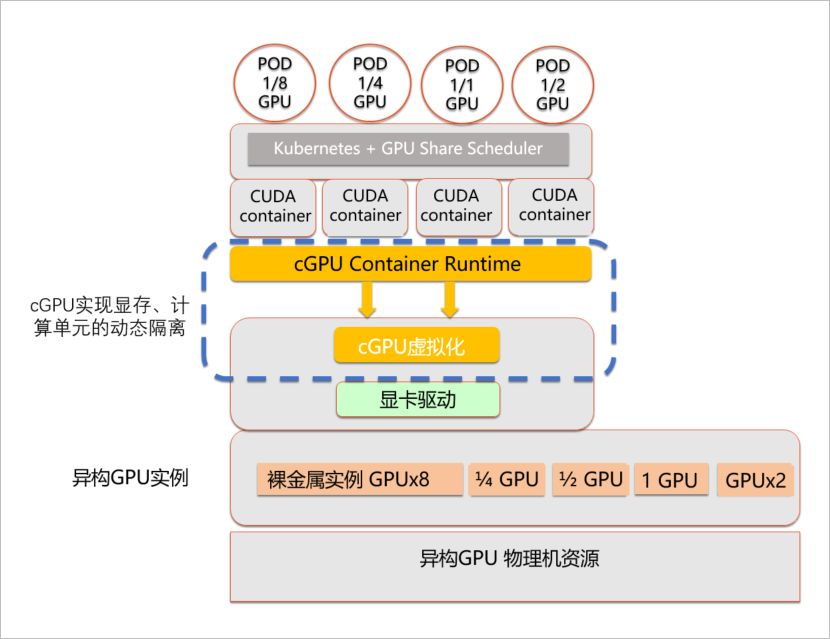
cGPU架构图
使用以下YAML内容,创建申请GPU显存和算力的任务:
apiVersion: batch/v1kind: Jobmetadata:name: cuda-samplespec:parallelism: 1template:metadata:labels:app: cuda-samplespec:containers:- name: cuda-sampleimage: registry.cn-beijing.aliyuncs.com/ai-samples/gpushare-sample:cuda-sample-11.0.3command:- bandwidthTestresources:limits: #申请2 GiB显存。aliyun.com/gpu-mem: 2 #申请一张GPU卡的30%算力。aliyun.com/gpu-core.percentage: 30workingDir: /rootrestartPolicy: Never
优点:支持算力、显存维度的管理调度,支持共享资源隔离。
不足之处:商业产品,只能在阿里云容器服务使用;自研难度极大。
3.3 腾讯qGPU
腾讯云推出GPU容器共享技术,实现多容器间GPU卡共享,显存、算力隔离。原理与阿里云cGPU相近,高效提升资源利用,简化管理。
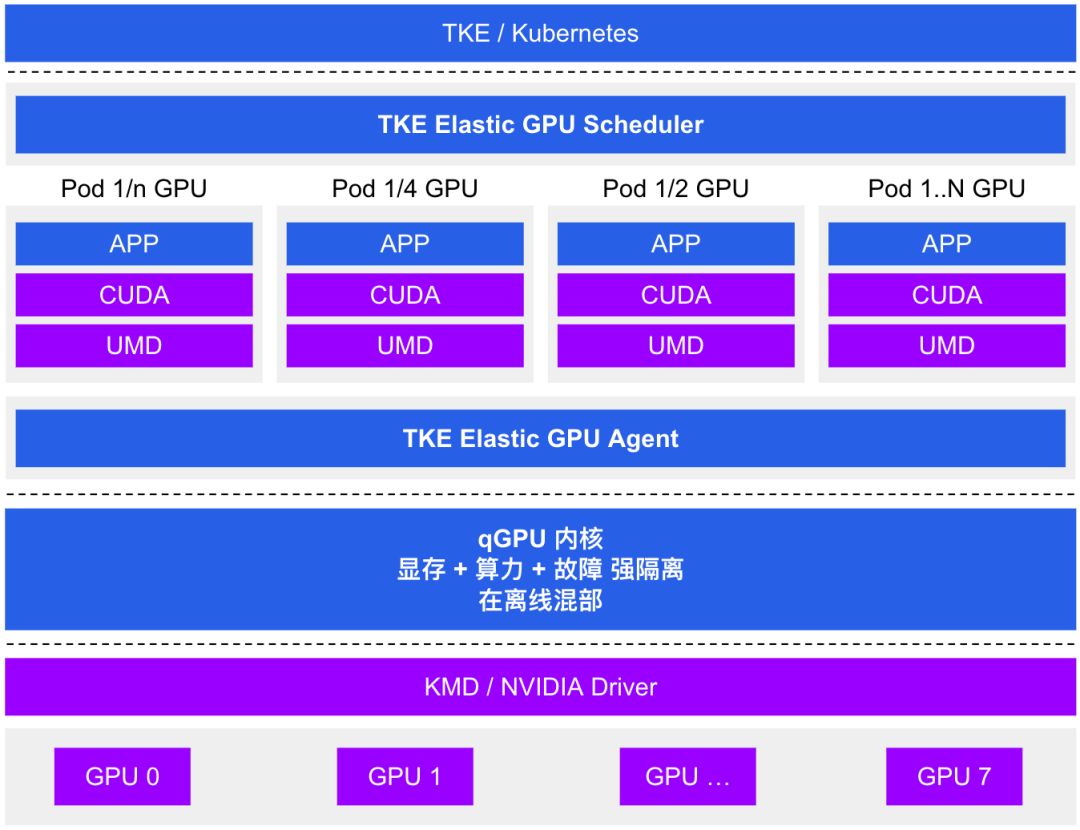
qGPU架构图
3.4 vCUDA
这里主要是讨论腾讯开源的GaiaGPU。vCUDA的系统架构采用一个Manager来管理GPU,Manager负责配置容器的GPU计算能力和显存资源,做到使用者无法使用多余申请的显存,GPU的平均使用率不会大幅超出申请值。vCUDA的设计只侵入了CUDA层,用户的程序无需重新编译就可以运行在基于vCUDA的GPU实现共享。vCUDA使用修改后cuda library来达到资源控制,vCUDA分别修改了计算操作,显存操作和信息获取3个方面的API。
GaiaGPU,尖端图形处理单元解决方案的代名词。我们专注于为业界提供最先进、性能卓越的GPU产品,通过高效的计算能力和卓越的图形渲染,助您轻松应对各种复杂场景。选择GaiaGPU,体验前所未有的高效与流畅,让您的项目更上一层楼!
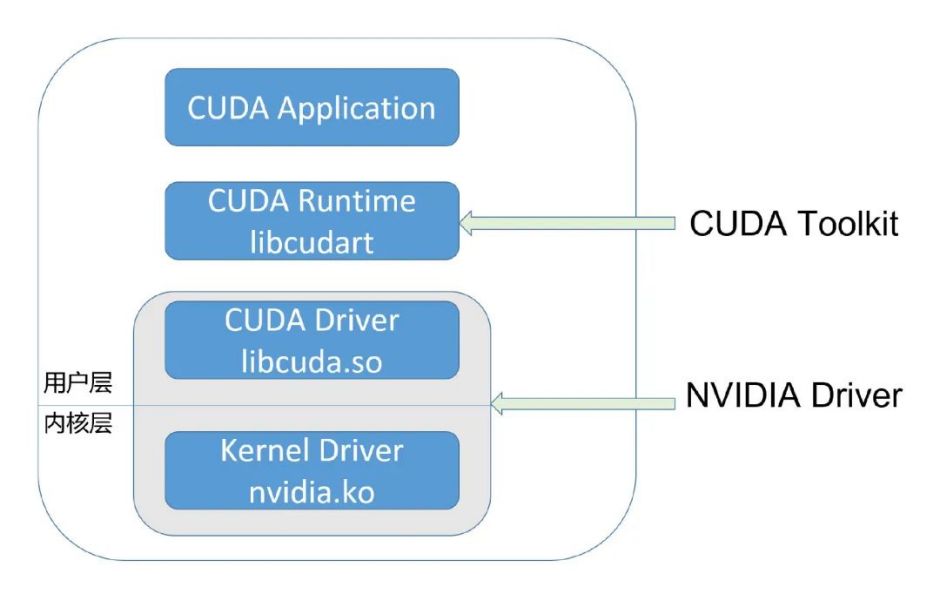
vCUDA智能管理GPU资源,通过拦截容器内CUDA驱动调用,精准控制进程对GPU和显存的占用,提升资源利用效率。
优点:开源,可以在任意地方使用,不依赖任何云。
缺点:需要替换CUDA库,版本要对齐;部分场景下有兼容性问题。
04 云原生方式管理GPU资源
cGPU、qGPU、vCUDA、gpu share、GPU 池化 等 GPU 共享技术越来越被用户采用。每种方案都有自己独立的一套 Kubernetes 集成实现方式,通常是由调度器 + device plugin 组成。这些方案相互独立,没有统一标准,无法共通。这导致用户在单个集群中很难同时使用多种 GPU 后端技术,同时也没有一个全局的视角获取集群层面 GPU 信息。这为基于 Kubernetes 构建统一的GPU算力基础设施平台增加了很多难度。
Elastic GPU引领创新,引入三款Kubernetes CRD,深受PV/PVC/StorageClass模型启发。这些CRD精准定义了GPU资源的各类抽象,助您实现更精细化的资源管理和高效利用,让GPU算力发挥到极致。详情访问https://github.com/elastic-ai/elastic-gpu。
- ElasticGPU:集群中实用GPU资源,涵盖本地物理卡、GPU算力与显存组合切片资源,以及远端设备。灵活配置,满足各种计算需求,助力高效数据处理与深度学习应用。
- ElasticGPUClaim让用户轻松申领ElasticGPU资源,支持整卡、GPU核数/显存、TFLOPS算力等灵活选择,满足您不同场景下的高性能计算需求。
- EGPUClass:高效打造ElasticGPU生态,支持qGPU虚拟化、vCUDA技术及GPU远端池化,轻松实现GPU的生产与挂载,助您轻松应对高性能计算需求。
支持用户通过云原生方式管理GPU资源。此方案分为四个模块:
- 在前端资源层面有两个标准化资源定义GPU Core和GPU Memory;
- GPU CRD直观呈现物理卡与容器资源关系,用户轻松掌握集群GPU资源分配,提升物理卡在集群中的可见性与管理效率。
- 自研GPU Extender Scheduler,精准调度GPU资源,提升集群分配效率,实时感知物理卡资源,实现精细化管理。
- Device Plugin Agent构建通用框架,支持多样Device Plugin发现机制,实现主流GPU Provider支持,简化用户管理,降低成本,为您的设备管理提供高效、便捷的解决方案。
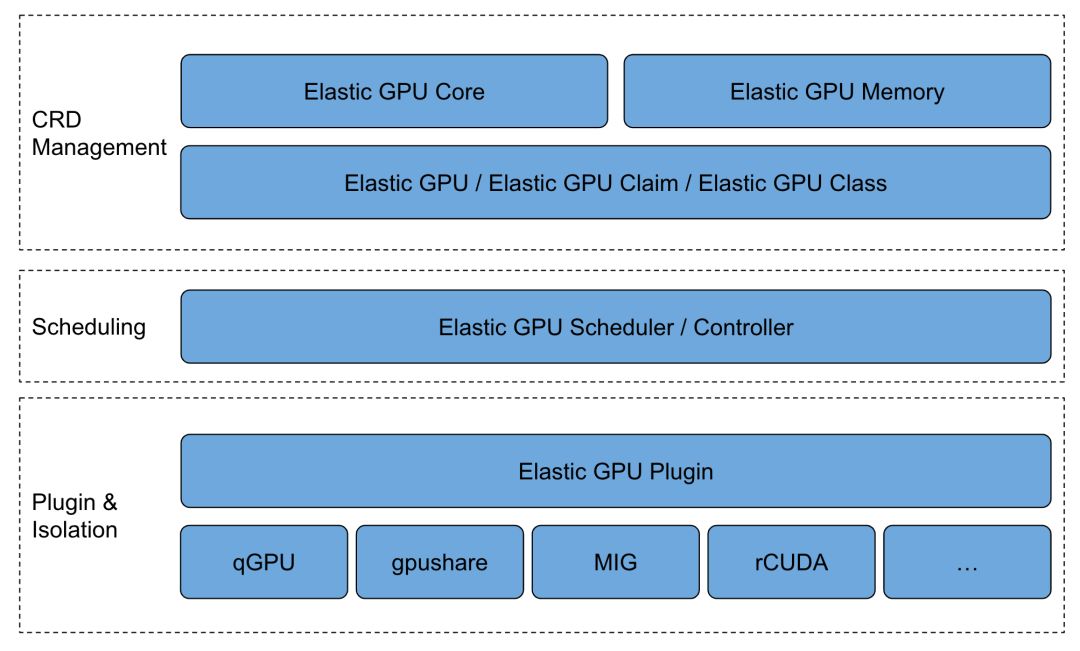 统一GPU框架
统一GPU框架
以qGPU为例,描述结合Elastic GPU方案
- qGPU资源申请
`apiVersion: elasticgpu.io/v1alpha1
kind: ElasticGPUClass
metadata:
name: qgpu-class
spec:
provisioner: elasticgpu.io/qgpu
reclaimPolicy: Retain
eGPUBindingMode: Immediate
精简定义,快速部署ElasticGPUClass资源`qgpu-class`,实现GPU资源的弹性管理与即时绑定,确保资源高效利用与回收。```
ElasticGPUClaim 精准定义qGPU资源需求。`tke.cloud.tencent.com/qgpu-core` 标识10% GPU算力申请,而`tke.cloud.tencent.com/qgpu-memory`则确保4GB显存需求。简洁高效,满足您对GPU资源的精准管理与优化。
ElasticGPU资源申请优化
```yaml
apiVersion: elasticgpu.io/v1alpha1
kind: ElasticGPUClaim
metadata:
name: qgpu-egpuc
spec:
storageClassName: qgpu-class
resources:
requests:
tke.cloud.tencent.com/qgpu-core: 10
tke.cloud.tencent.com/qgpu-memory: 4Gi
```
简洁高效的ElasticGPU申请配置,明确指定了GPU核心数和内存量,确保资源合理分配与应用性能最大化。
用户通过指定ElasticGPUClaim,轻松申领qGPU资源,实现Pod创建过程中的高效资源配置。
```yaml
apiVersion: v1
kind: Pod
metadata:
name: qgpu-pod
annotations:
elasticgpu.io/egpuc-<container-name>: qgpu-egpuc
spec:
containers:
- name: test
# 高效GPU容器部署,专注于性能优化
```
优化后的文案简洁明了,突出了GPU容器部署的专业性和性能优化的重点。
05 总结
Kubernetes通过Device Plugin机制对GPU进行管理,使用GPU厂商提供的Device Plugin插件,即可在集群中申请使用GPU资源。对于需要共享GPU算力,并且不考虑资源隔离的场景,可考虑使用开源的GPU Share Device Plugin插件。cGPU、qGPU、vCUDA等方案在支持共享GPU算力的同时,提供了资源隔离的能力,企业可根据需求进行选择。Elastic GPU通过扩展定义CRD,对GPU资源进行了抽象,能较好的支持gpu share、cGPU、qGPU、vCUDA等多种技术,是一种非常好的云原生方式管理GPU思路。目前社区只适配了qGPU,其他技术如gpu share目前需要自行完成适配。
-对此,您有什么看法见解?-
-欢迎在评论区留言探讨和分享。-

























![[Bug]使用Transformers 微调 Whisper出现版本不兼容的bug](https://img-blog.csdnimg.cn/direct/91f3f5876f9240a4aefe0851648dfbb6.png)