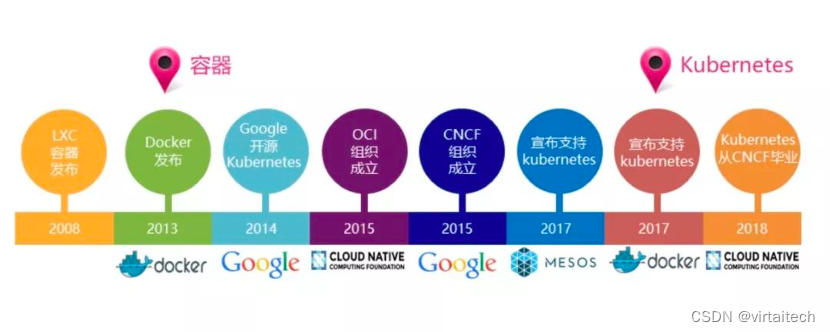
随着英伟达卡被禁售,国产显卡市场逐渐崛起。以华为、曙光为第一梯队代表,壁仞、燧原、寒武纪等为第二梯队代表,场景覆盖从图像识别到大模型训练、推理,落地领域包括金融、安防、智能汽车、IOT、智能客服等行业
国内主流的GPU提供商:
- 昆仑芯:昆仑芯(北京)科技有限公司前身为百度智能芯片及架构部,于2021年4月完成独立融资,首轮估值约130亿元。是国内最早布局AI加速领域,深耕10余年,是一家在体系结构、芯片实现、软件系统和场景应用均有深厚积累的AI芯片企业。
- 壁仞科技:壁仞科技创立于 2019 年,在 GPU、DSA(专用加速器)和计算机体系结构等领域具有深厚的技术积累。公司致力于开发原创性的通用计算体系,建立高效的软硬件平台,同时在智能计算领域提供一体化的解决方案。
- 燧原科技:燧原科技是一家专注于人工智能领域云端算力平台的创业公司,致力为人工智能产业发展提供普惠的基础设施解决方案,提供自主知识产权的高算力、高能效比、可编程的通用人工智能训练和推理产品。其创新性架构、互联方案和分布式计算及编程平台,可广泛应用于云数据中心、超算中心、互联网、金融及智慧城市等多个人工智能场景。燧原科技是国内第一家同时拥有高性能云端训练和云端推理产品的创业公司,同时也是国内第一个发布第二代人工智能训练产品组合的公司。燧原科技自成立以来,已完成多轮融资,并发布了多款人工智能训练和推理产品。
- 海光:海光DCU(Data Center Unit)系列产品以GPGPU(通用并行计算图形处理器)架构为基础,兼容通用的“类CUDA”环境。该系列产品可广泛应用于大数据处理、人工智能、商业计算等应用领域。海光DCU产品能适配、适应国际主流商业计算软件和人工智能软件,是国内具有全精度浮点数据和各种常见整型数据计算能力的GPGPU产品。其采用“类CUDA”通用并行计算架构,可广泛应用于电信、金融、互联网、教育、交通等重要行业或领域。
- 寒武纪:寒武纪公司是一家专注于人工智能芯片领域的科技企业,成立于2016年。该公司的主要业务是设计、生产基于人工智能芯片的处理器,以及提供基于这些芯片的解决方案。这些芯片可以应用于各种需要人工智能处理能力的领域,如云计算、智能家居、智能安防等。
- 华为昇腾:目前提供包括推理卡与训练卡,训练卡主要包括910A和910B,910A性能接入A10910B目前性能接近A800的80%,但生态有待完善
国内GPU厂商产品及参数
| 品牌 | 昆仑芯 | 壁仞科技 | 燧原科技 | 海光 | 寒武纪 | 华为海思 | |
| 产品 | R200 | BR100 | i20 | 深算一号 | MLU370-X8 | 昇腾910 | |
| 发布日期 | 2021 | 2022 | 2021 | 2021 | 2022 | 2018 | |
| 半精度(FP16) | 128 TFLOPS | NA | 128 TFLOPS | NA | 96 TFLOPS | 320 TFLOPS | |
| 单精度(FP32) | 32 TFLOPS | 256 TFLOPS | 32 TFLOPS | NA | 24 TFLOPS | NA | |
| 双精度(FP64) | NA | NA | NA | 10.8 TFLOPS | NA | NA | |
| INT8 | 256 TOPS | 2048 TOPS | 256 TOPS | NA | 256 TOPS | 640 TOPS | |
| CUDA兼容 | NA | 是 | 否 | NA | 否 | NA | |
海外GPU厂商产品及参数:
| 品牌 | AMD | AMD | NVIDIA | NVIDIA | NVIDIA | NVIDIA | NVIDIA |
| 产品 | INSTINCT MI100 | INSTINCT M1250 | P100 | V100 SXM2 | T4 | A100 80GB | H100 PCle |
| 发布日期 | 2020 | 2021 | 2016 | 2017 | 2018 | 2020 | 2022 |
| 工艺 | 7nm | 6nm | 16nm | 12nm | 12nm | 7nm | 4nm |
| 半精度(FP16) | 184.6 TFLOPS | 362.1 TFLOPS | 21.2 TFLOPS | 125 TFLOPS | 65 TFLOPS | 312 TFLOPS | NA |
| 半精度(FP16 Tensor Core) | NA | NA | 不支持 | 不支持 | 不支持 | 不支持 | 1600 TFLOPS* |
| 单精度(FP32) | 23.1 TFLOPS | 45.3 TFLOPS | 10.6 TFLOPS | 15.7 TFLOPS | NA | 19.5 TFLOPS | 48 TFLOPS |
| 单精度(FP32 Tensor Float) | 46.1 TFLOPS(AMD为Matrix Core) | 90.5 TFLOPS (AMD为Matrix Core) | 不支持 | 不支持 | 不支持 | 156 TFLOPS | 800 TFLOPS |
| 双精度(FP64) | 11.5 TFLOPS | 45.3 TFLOPS | 5.3 TFLOPS | 7.8 TFLOPS | 8.1 TFLOPS | 9.7 TFLOPS | 24TFLOPS |
| 双精度(FP64 Tensor Core) | 不支持 | 90.5 TFLOPS (AMD为Matrix Core) | 不支持 | 不支持 | 不支持 | 19.5 TFLOPS | 48 TFLOPS |
| INT8 | 184.6 TOPs | 362.1 TOPs | NA | NA | 130TOPs | 624TOPs | NA |
| INT8(Tensor Core) | 不支持 | NA | 不支持 | 不支持 | 不支持 | 不支持 | 3200TOPs |
| CUDA兼容 | 否 | 否 | 是 | 是 | 是 | 是 | 是 |
国内外GPU卡的主要差距
1. 技术差距:国外GPU卡在技术研发方面领先,拥有较高的计算性能和能效比。而国内GPU卡在技术研发方面相对滞后,与国外产品存在一定的性能差距。
2. 编程软件:主要是CUDA、Pytorch相关的软件完善度不够,需要一个比较长的时间来积累
3. 用户生态:包括集成商生态,用户生态,软件生态、人才生态、行业生态、场景生态等需要完善
为了缩小国内外GPU卡的差距,国内企业需要加强自主研发和创新,提高技术研发能力;同时,需要加强生态系统建设,完善硬件、软件、开发工具w和应用场景等方面的布局;还需要加强市场推广和品牌建设,提高市场竞争力和影响力。