使用TensorFlow构建马尔可夫决策过程模型
使用TensorFlow构建马尔可夫决策过程模型:决策分析的深度实践
马尔可夫决策过程(Markov Decision Process, MDP)是解决决策制定问题的经典方法之一,尤其擅长处理具有随机性和序列决策的问题。TensorFlow,作为强大的机器学习库,提供了丰富的工具来构建和解决这类问题的框架。本文将指导你如何使用TensorFlow构建马尔可夫决策过程模型,从基础概念入手,逐步深入到代码实现,最终展示如何在实际决策问题中应用。
一、马尔可夫决策过程简介
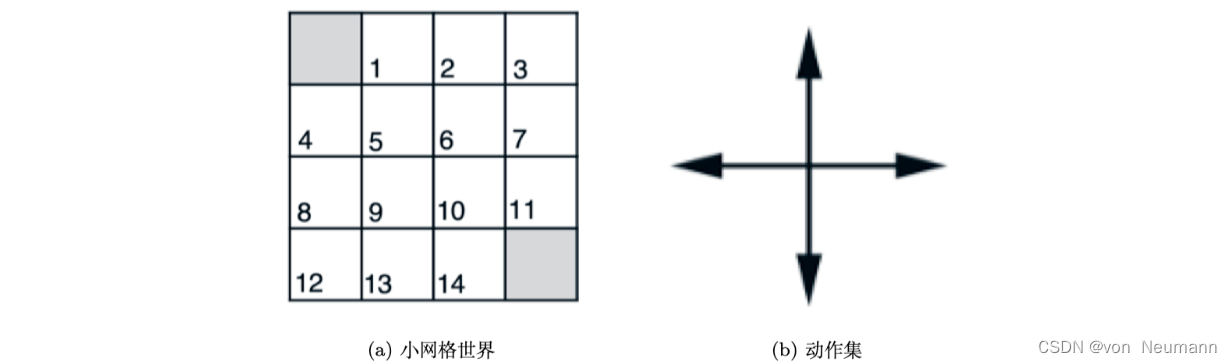
马尔可夫决策过程由状态空间、动作空间、奖励函数、状态转移概率和折扣因子组成。在每个时刻,决策者基于当前状态选择一个动作,环境根据一定的概率转移到下一个状态,并给予一个即时奖励。目标是找到一个策略,最大化长期累积奖励。
二、TensorFlow准备
首先,确保安装并导入TensorFlow库。此外,还需要Numpy用于数组操作。
import numpy as np
import tensorflow as tf
三、定义MDP模型参数
假设一个简单的环境,有3个状态(S1, S2, S3),2个动作(A1, A2),转移概率矩阵已知,奖励矩阵已知。
states = ['S1', 'S2', 'S3']
actions = ['A1', 'A2']
transition_probs = {
('S1', 'A1'): {'S1': 0.7, 'S2': 0.3},
('S1', 'A2'): {'S2': 0.6, 'S3': 0.4},
('S2', 'A1'): {'S1': 0.4, 'S2': 0.6},
('S2', 'A2'): {'S3': 0.7, 'S2': 0.3},
('S3', 'A1'): {'S1': 0.1, 'S3': 0.9},
('S3', 'A2'): {'S2': 0.8, 'S3': 0.2}
}
}
rewards = {
('S1', 'A1'): 10,
('S1', 'A2'): 2,
('S2', 'A1'): 3,
('S2', 'A2'): 1,
('S3', 'A1'): 2,
('S3', 'A2'): 3
}
discount_factor = 0.9
四、构建状态值函数模型
使用TensorFlow定义状态值函数(V(s))的神经网络模型,作为预测每个状态的期望回报。
def build_value_function_model():
model = tf.keras.Sequential([
tf.keras.layers.InputLayer(input_shape=(1, name="state_input"), # 状态输入
tf.keras.layers.Dense(32, activation='relu'), # 隐藏层
tf.keras.layers.Dense(1) # 输出层,预测值函数
])
model.compile(optimizer=tf.optimizers.Adam(), loss="mse") # 使用均方误差作为损失
return model
value_model = build_value_function()
五、迭代更新值函数
根据贝尔曼算法(Bellman Equation)迭代更新值函数,直到收敛。
def update_values():
num_iterations = 10
while True:
num_iterations += 1
for state in states:
next_states_values = [
transition_probs[(state, action)][next_state] * rewards[(state, action)]
+ discount_factor * value_model(np.array([[next_state]]).numpy()[0])
for action in actions
for next_state in states
]
max_value = np.max(next_states_values)
value_model.fit(np.array([[state]]), np.array([max_value)]), epochs=1, verbose=0)
if num_iterations % 100 == 0: # 每100次迭代打印一次
print("Iteration:", num_iterations, "Loss:", value_model.evaluate(np.array(states), verbose=0))
if num_iterations > 10000: # 假定义一个停止条件
break
update_values()
六、策略提取与决策
根据最终的值函数,提取最优策略。
def extract_policy():
policy = {}
for state in states:
q_values = np.array([[
rewards[(state, action)]
+ discount_factor * np.sum(
[transition_probs[(state, action)][next_state] * value_model(np.array([[next_state]]).numpy()[0]
for next_state in states
)
)
for action in actions
])
best_action = np.argmax(q_values)
policy[state] = actions[best_action]
return policy
optimal_policy = extract_policy()
print("Optimal Policy:", optimal_policy)
结语
通过上述步骤,我们使用TensorFlow成功构建了一个马尔可夫决策过程模型,从定义环境参数到训练值函数,直至提取最优策略。此框架不仅适用于简单的示例,对于更复杂环境和实际问题,只需相应扩展状态空间、动作空间及调整模型复杂度即可。TensorFlow的灵活性和强大计算能力为探索复杂决策问题提供了无限可能。