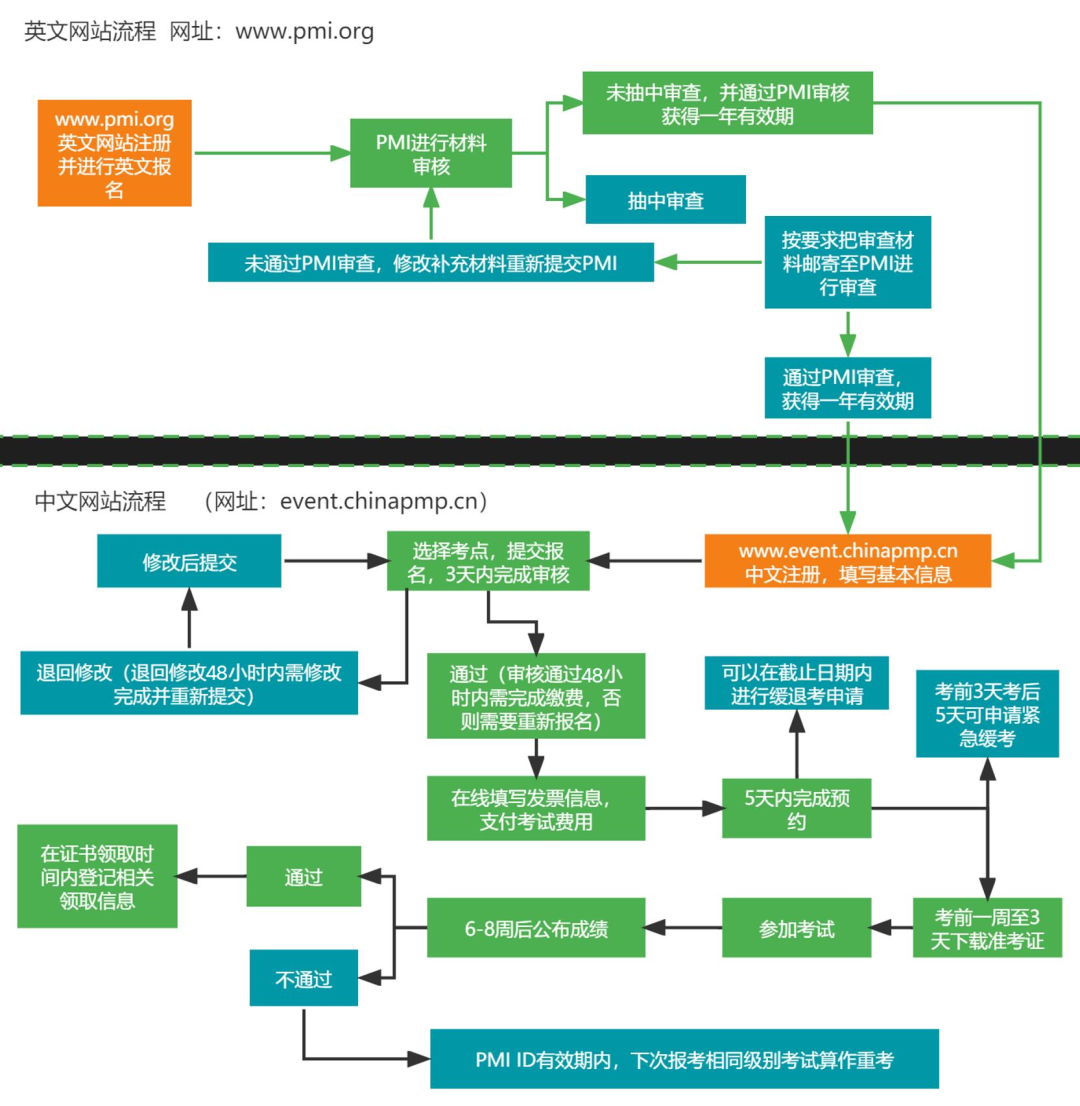
目录
3️⃣ 4.3 利用条形图、折线图探究单车使用量和季节的关系
4️⃣ 4.4 利用条形图、折线图探究单车使用量和月份的关系
5️⃣ 4.5 利用条形图、箱线图探究单车使用量和星期的关系
1️⃣ 5.1 利用条形图、折线图探究单车使用量和温度、湿度和风速的关系
◾ df = ggplot(data, aes(x, y))
3️⃣ 4.3 利用条形图、折线图探究单车使用量和季节的关系
📍 折线图
plt.plot(x, y, format_string, **kwargs, color, linestyle, linewidth, marker, markersize, markeredgecolor, markerfacecolor)
| 字段 | 数据类型 | 含义 |
x, y |
数组 or list | x 和 y 是表示数据点坐标的序列。x 是x轴上的坐标值,y 是对应的y轴上的坐标值 |
format_string |
str | 可选的字符串,用于指定线条的样式、颜色和标记。例如,'r-' 表示红色实线,'go' 表示绿色圆圈标记 |
color |
str or 颜色代码 |
参数用于指定线条的颜色。可以是颜色的名称(如'red'),十六进制颜色代码(如'#FF0000'),RGB元组(如(1.0, 0.0, 0.0))等 |
linestyle |
str | 指定线条的样式。例如,'-' 表示实线,'--' 表示虚线,'-.' 表示点划线,':' 表示点状线,' '(空格)表示没有线条 |
linewidth |
float or int | 用于指定线条的宽度 |
marker |
str | 指定数据点的标记样式。例如,'o' 表示圆圈,'.' 表示点,',' 表示像素点,'s' 表示正方形等 |
markersize |
float or int | 指定标记的大小 |
markeredgecolor |
str or 颜色代码 |
指定标记边缘的颜色 |
markerfacecolor |
str or 颜色代码 |
指定标记填充的颜色 |
# 1.绘图
### 分组聚合
season_Aggregated = pd.DataFrame(data.groupby(['年份','季节']).sum())['使用量'].reset_index()
# 将data的数据,根据'年份'、'季节'进行分组'进行分组,并统计总数,然后根据'使用量'进行重新编排索引
# 2.绘制条形图
plt.figure(figsize=(14, 8))
plt.subplot(1, 2, 1)
plt.bar(season_Aggregated['季节'][:4]-0.2, # 数据
season_Aggregated['使用量'][:4], # 数据
width=0.4, # 表示柱状图的宽度
color='green', label='2011') # 设置柱子颜色和标签
plt.bar(season_Aggregated['季节'][4:]+0.2, # 数据
season_Aggregated['使用量'][4:], # 数据
width=0.4, # 表示柱状图的宽度
color='yellow', label='2012') # 设置柱子颜色和标签
plt.title('使用量与季节关系条形图', fontsize=15) # 设置图形的标题以及文字的打下
plt.xlabel('季节', fontsize=15) # 设置x轴标签以及字体大小
plt.ylabel('使用量', fontsize=15) # 设置y轴标签以及字体大小
plt.xticks([1, 2, 3, 4], ['春季', '夏季', '秋季', '冬季']) # 设置x轴刻度以及对应刻度的标签
plt.legend(loc='best') # 设置图例位置
# 3.绘制折线图
plt.subplot(1, 2, 2)
plt.plot(season_Aggregated['季节'][:4],
season_Aggregated['使用量'][:4],
color='green', # 设置颜色
lw=3, # 设置折线的宽度
marker='o', # 设中的点的标记图形
label='2011')
plt.plot(season_Aggregated['季节'][4:],
season_Aggregated['使用量'][4:],
color='yellow', # 设置颜色
lw=3, # 设置折线的宽度
marker='o', # 设中的点的标记图形
label='2012')
plt.title('使用量与季节折线图', fontsize=15)
plt.xlabel('季节', fontsize=15)
plt.ylabel('使用量', fontsize=15)
plt.xticks([1, 2, 3, 4], ['春季', '夏季', '秋季', '冬季'])
plt.legend(loc='best')
plt.grid(True) # 在图形内部显示网格线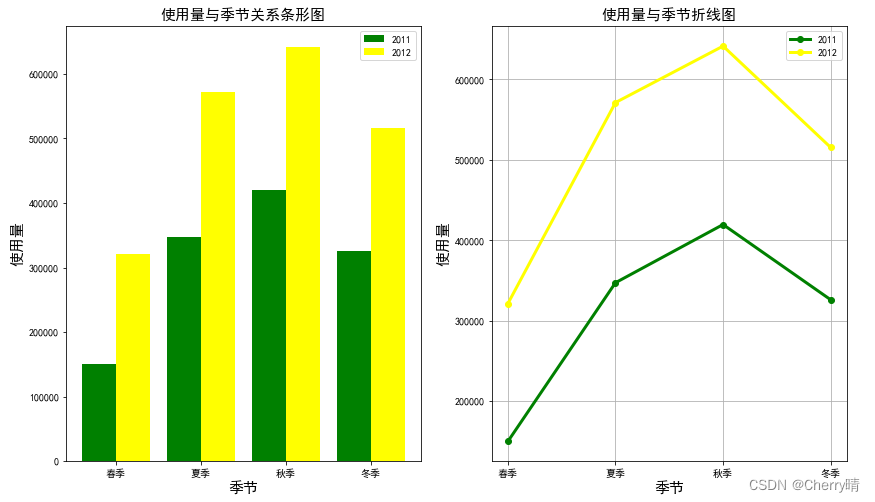
4️⃣ 4.4 利用条形图、折线图探究单车使用量和月份的关系
# 1.绘图
### 分组聚合
month_Aggregated = pd.DataFrame(data.groupby(['年份','月份']).sum())['使用量'].reset_index()
# 将data的数据,根据'年份'、'月份'进行分组'进行分组,并统计总数,然后根据'使用量'进行重新编排索引
# 2.绘制条形图
plt.figure(figsize=(14, 10))
plt.subplot(2, 1, 1)
plt.bar(month_Aggregated['月份'][:12]-0.2,
month_Aggregated['使用量'][:12],
width=0.4, # 表示柱状图的宽度
color='blue', label='2011')
plt.bar(month_Aggregated['月份'][12:]+0.2,
month_Aggregated['使用量'][12:],
width=0.4, # 表示柱状图的宽度
color='gold', label='2012')
plt.title('使用量与月份关系条形图', fontsize=15)
plt.xlabel('月份', fontsize=15)
plt.ylabel('使用量', fontsize=15)
plt.xticks(np.arange(1, 13)) # 横坐标为1-12
plt.legend(loc='best')
# 3.绘制折线图
plt.subplot(2, 1, 2)
plt.plot(month_Aggregated['月份'][:12],
month_Aggregated['使用量'][:12],
color='blue', # 控制线条宽度
lw=3,
marker='o', # 设中的点的标记图形
label='2011')
plt.plot(month_Aggregated['月份'][12:],
month_Aggregated['使用量'][12:],
color='gold',
lw=3, # 控制线条宽度
marker='o', # 设中的点的标记图形
label='2012')
plt.title('使用量与月份折线图', fontsize=15)
plt.xlabel('月份', fontsize=15)
plt.ylabel('使用量', fontsize=15)
plt.xticks(np.arange(1, 13)) # 横坐标为1-12
plt.legend(loc='best')
plt.grid(True) # 在图形内部显示网格线
5️⃣ 4.5 利用条形图、箱线图探究单车使用量和星期的关系
## 条形图
### 分组聚合
weekday_Aggregated = pd.DataFrame(data.groupby(['年份','星期']).sum())['使用量'].reset_index()
# 将data的数据,根据'年份'、'星期'进行分组'进行分组,并统计总数,然后根据'使用量'进行重新编排索引
### 绘图
plt.figure(figsize=(20, 8))
plt.subplot(1, 3, 1)
plt.bar(weekday_Aggregated['星期'][:7]-0.2,
weekday_Aggregated['使用量'][:7],
width=0.4, # 表示柱状图的宽度
color='green', label='2011')
plt.bar(weekday_Aggregated['星期'][7:]+0.2,
weekday_Aggregated['使用量'][7:],
width=0.4, # 表示柱状图的宽度
color='yellow', label='2012')
plt.title('使用量与星期关系条形图', fontsize=15)
plt.xlabel('星期', fontsize=15)
plt.ylabel('使用量', fontsize=15)
plt.xticks([0, 1, 2, 3, 4, 5, 6], ['周一', '周二', '周三', '周四', '周五', '周六', '周日']) # 使用列表的方式来表示轴的标签
plt.legend(loc='best')
## 箱线图
### 筛选
work_usecount = pd.Series(data['使用量'][data['工作日']==1]) # 筛选'工作日'这一列的数据,为1的赋值给work_usecount
rest_usecount = pd.Series(data['使用量'][data['工作日']==0]) # 筛选'工作日'这一列的数据,为0的赋值给rest_usecount
workingday_usecount = [work_usecount, rest_usecount] # 合并两个数组
### 绘图
plt.subplot(1, 3, 2)
plt.boxplot(workingday_usecount,
labels = ['是', '否'],
widths=0.5, # 指定箱线图的宽度,默认为0.5
patch_artist = True, # 填充箱体的颜色
showfliers = False, # 不显示异常值
boxprops = {'color':'black','facecolor':'red'})
plt.title('使用量与工作日关系箱线图', fontsize=15)
plt.xlabel('工作日', fontsize=15)
## 筛选
holi_usecount = pd.Series(data['使用量'][data['节假日']==1]) # 筛选'节假日'这一列的数据,为1的赋值给holi_usecount
noholi_usecount = pd.Series(data['使用量'][data['节假日']==0]) # 筛选'节假日'这一列的数据,为0的赋值给noholi_usecount
holiday_usecount = [holi_usecount, noholi_usecount]
plt.subplot(1, 3, 3)
plt.boxplot(holiday_usecount,
labels = ['是', '否'],
widths=0.5, # 指定箱线图的宽度,默认为0.5
patch_artist = True, # 填充箱体的颜色
showfliers = False, # 不显示异常值
boxprops = {'color':'black','facecolor':'navy'})
plt.title('使用量与节假日关系箱线图', fontsize=15)
plt.xlabel('节假日', fontsize=15)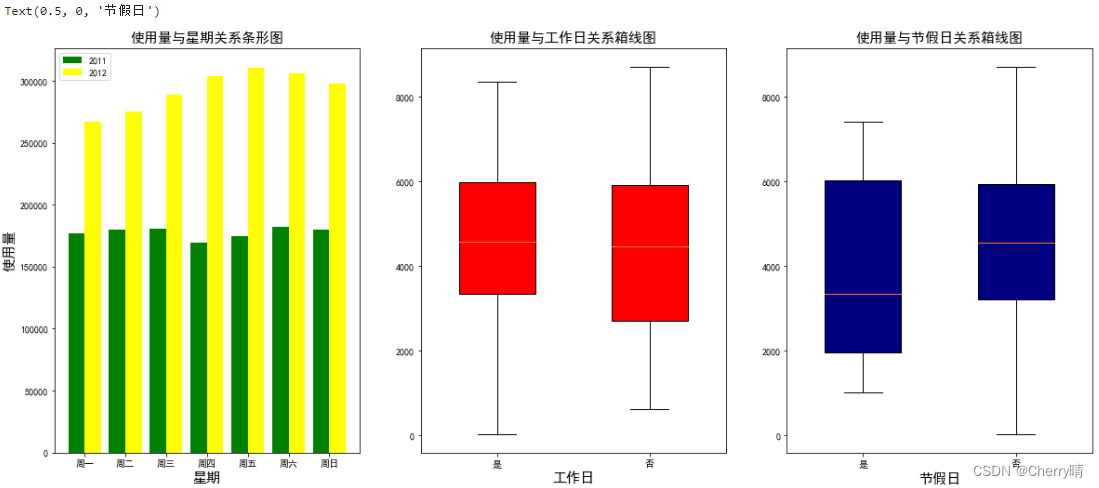
从上面三幅图可以看出,2011年一周内各天的租车量大致相同,2012年周四、周五和周六的租车量最高;在工作日方面,是否为工作日对租车辆的影响并不明显;而节假日的租车量相较非节假日来说较小。
6️⃣ 4.6 利用箱线图探究单车使用量和天气的关系
## 筛选
plt.figure(figsize=(8, 8))
weaType1 = pd.Series(data['使用量'][data['天气类型']==1]) # 根据'天气类型'进行筛选,分为3种类型
weaType2 = pd.Series(data['使用量'][data['天气类型']==2])
weaType3 = pd.Series(data['使用量'][data['天气类型']==3])
weather_usecount = [weaType1, weaType2, weaType3]
### 箱线图
plt.boxplot(weather_usecount,
labels = ['晴朗少云', '多云雾', '小雨雪雷电'],
widths=0.5,
patch_artist = True, # 填充箱体的颜色
showfliers = False) # 不显示异常值
plt.title('使用量与天气关系箱线图', fontsize=15)
plt.xlabel('天气', fontsize=15)
plt.grid(True)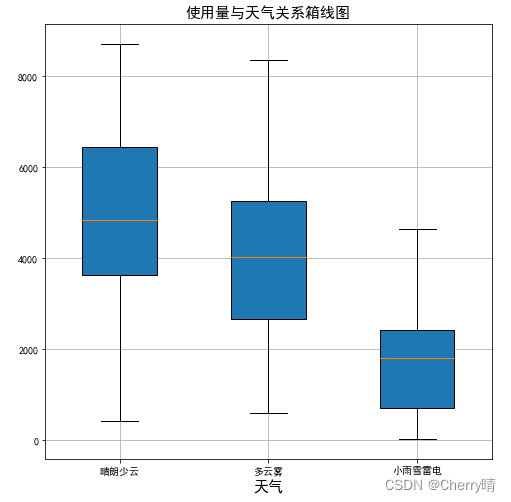
📈 5、拟合回归线
1️⃣ 5.1 利用条形图、折线图探究单车使用量和温度、湿度和风速的关系
- 使用散点图并拟合回归线来观察使用量和温度、湿度和风速的关系
📍 ggplot画图步骤及方法
◾ df = ggplot(data, aes(x, y))
给参数data里传入数据,x里传入横坐标数据,y里传入纵坐标数据,即可画出一个空白框图
◾ 画图形
(1) geom_point() : 散点图
(2) geom_line() : 折线图
(3) geom_point() + geom_line() : 折线散点图
(4) geom_area() : 面积图:ggplot(aes(x='', ymin='', ymax=''),data) + geom_area()
(5) geom_bar() : 柱状图
(6) geom_density() : 概率密度函数图
◾ 添加线条有多种类型的方法
(1) stat_smooth(color='blue') : 添加趋势线,画拟合曲线
(2) geom_abline(intercept, slope, color, size) : 添加斜线,intercept确定截距,slope确定斜率,效果类似于stat_smooth()
(3) geom_hline(yintercept, color, size) : 添加水平线,yintercept确定水平线的位置,color确定颜色,size确定线条宽度
(4) geom_vline(xintercept, color, size) : 添加垂线
◾ 文本设置
theme(text = element_text(fontproperties=myfont))
element_text(family = NULL, face = NULL, colour = NULL, size = NULL, hjust = NULL, vjust = NULL, angle= NULL, lineheight = NULL)
| 字段 | 数据类型 | 含义 |
family |
str | 指定字体族(如"serif", "sans", "mono"等,或具体的字体名称) |
face |
str | 指定字体的样式(如"plain", "italic", "bold", "bold.italic") |
colour |
str | 指定颜色,可以是颜色名称或十六进制颜色代码 |
size |
数值 | 指定字体大小 |
🔷 单车使用量与温度的关系
# 与温度的关系
plt.figure(figsize=(12, 8))
# ggplot(data, aes('温度', '使用量')):入的数据是data的数据,x轴的数据是'温度',y轴的数据是'使用量
# geom_point(color='blue'):画散点图,点的颜色为蓝色
# geom_smooth(method='lm'):画拟合曲线
# geom_smooth(method = 'lm',se = F,color='red',size=1),设置se = F,绘制拟合线。
# theme(text = element_text(fontproperties=myfont)):文本的设置
ggplot(data, aes('温度', '使用量')) + geom_point(color='blue') + geom_smooth(method='lm') + theme(text = element_text(fontproperties=myfont))

🔷 单车使用量与湿度的关系
# 与湿度的关系
plt.figure(figsize=(12, 8))
# ggplot(data, aes('湿度', '使用量')):入的数据是data的数据,x轴的数据是'温度',y轴的数据是'使用量
# geom_point(color='blue'):画散点图,点的颜色为蓝色
# geom_smooth(method='lm'):画拟合曲线
ggplot(data, aes('湿度', '使用量')) + geom_point(color='green') + geom_smooth(method='lm') + theme(text = element_text(fontproperties=myfont))

🔷 单车使用量与风速的关系
### 与风速的关系
plt.figure(figsize=(12, 8))
# ggplot(data, aes('风速', '使用量')):入的数据是data的数据,x轴的数据是'温度',y轴的数据是'使用量
# geom_point(color='blue'):画散点图,点的颜色为蓝色
# geom_smooth(method='lm'):画拟合曲线
ggplot(data, aes('风速', '使用量')) + geom_point(color='red') + geom_smooth(method='lm') + theme(text = element_text(fontproperties=myfont))

从上面三幅图可以看出,温度与使用量呈正相关关系,随着温度的升高租车量在增加;湿度和风速与使用量呈负相关关系,随着湿度和风速的升高租车量在下降。
🌳 6、利用决策树预测单车的使用量
1️⃣ 将数据分为训练集和测试集
- 把数据分为训练集和测试集,利用除单车使用量之外的所有特征来建立决策树模型,预测单车的使用量,并将模型可视化并得到各特征的重要性,数据的分割比例为训练集75%,测试集25%
## 分离数据和目标
X = data.drop(['日期', '使用量'], axis=1) # 按列删除,删除data数据中的'日期'和'使用量'这两列
y = data['使用量']- 分割数据时要注意的是,因为数据间带有时间特性,不能随机打乱,所以这里我们将数据的前75%作为训练集,后25%作为测试集
# 1.分割训练集合测试集
cut_point = np.floor(X.shape[0]*0.75) # 返回不大于输入参数的最大整数。
# 即对于输入值x将返回最大的整数i使得 i <= x。注意在Python中,向下取整总是从 0 舍入
# 2.分割训练集
X_train = X.loc[:cut_point, :]
y_train = y.loc[:cut_point]
# 3.分割测试集
X_test = X.loc[cut_point:, :]
y_test = y.loc[cut_point:]2️⃣ 导入库和建立模型
# 1.载入必要库
from sklearn.tree import DecisionTreeRegressor
# 2.建立模型
model_DF = DecisionTreeRegressor(max_depth=3, random_state=10)
# 3.训练模型
model_DF.fit(X_train, y_train)
# 4.得到的结果为
DecisionTreeRegressor(max_depth=3, random_state=10)📍 用于创建决策树回归模型的类DecisionTreeRegressor(criterion,splitter,max_depth,min_samples_split,min_samples_leaf,min_weight_fraction_leaf,max_features,random_state,max_leaf_nodes,min_impurity_decreas,ccp_alpha)
| 字段 | 数据类型 | 含义 |
| criterion | str | 可选值包括 'mse' 或 'mae'。用于指定分割内部节点的标准,默认为 'mse'(均方误差) |
| splitter | str | 可选值包括 'best' 或 'random'。用于指定在每个节点选择特征的方式,默认为 'best' |
| max_depth | int | 指定树的最大深度。如果是 None,则树会生长到所有叶子都是纯的或直到所有叶子包含少于 min_samples_split 个样本为止 |
| min_samples_split | int or float | 指定一个内部节点必须拥有的最小样本数,以便进行分割。如果是浮点数,则它应该是一个介于 0 和 1 之间的分数,并且 ceil(min_samples_split * n_samples) 将作为最小样本数 |
| min_samples_leaf | int or float | 指定一个叶子节点必须拥有的最小样本数。如果是浮点数,则它应该是一个介于 0 和 1 之间的分数,并且 ceil(min_samples_leaf * n_samples) 将作为最小样本数。 |
| min_weight_fraction_leaf | float | 指定叶子节点中样本权重和的最小比例 |
| max_features | int or float or str | 指定寻找最佳分割时要考虑的特征数。如果是整数,则考虑 max_features 个特征;如果是浮点数,则考虑 max_features * n_features 个特征; 如果是 'auto',则 max_features=sqrt(n_features); 如果是 'sqrt',则 max_features=sqrt(n_features); 如果是 'log2',则max_features=log2(n_features); 如果是 None则 max_features=n_features |
| random_state | int | 用于控制树构建的随机性 |
| max_leaf_nodes | int | 如果不是 None,则树将不会有超过 max_leaf_nodes 的叶节点 |
| min_impurity_decreas | float | 果分割导致的不纯度减少小于此值,则节点将不会被分割 |
| ccp_alpha | 非负浮点数 |
用于进行复杂度参数剪枝的复杂度参数 |
- DecisionTreeRegressor(max_depth=3, random_state=10)
- max_depth这个参数决定了决策树的最大深度。树的深度是从根节点到最远叶子节点的最长路径上的节点数。max_depth=3 意味着决策树的最大深度将被限制为3,也就是说,从根节点开始,最多只有3层(包括根节点和叶子节点)。限制树的深度可以帮助防止过拟合,但也可能导致模型欠拟合。
- random_state这个参数用于设置随机数生成器的种子。决策树在构建过程中可能会涉及到一些随机性,比如特征的选择和划分点的选择。设置 random_state可以确保每次运行代码时,模型的构建过程都是一致的,从而得到相同的结果。这对于实验的可重复性非常重要
3️⃣ 决策树可视化
import os
os.environ['PATH'] += os.pathsep + 'C:/XXX/xxx/Desktop/实验五——共享单车可视化/Graphviz/bin/'
### 决策树可视化
# 1.导入必要库
from sklearn.tree import export_graphviz
from six import StringIO
from IPython.display import Image
import pydotplus
# 2.输出图片到dot文件
X_train_ename = ['season', 'year', 'month', 'holiday', 'weekday', 'workingday', 'weather', 'temperature', 'humidity', 'windSpend']
export_graphviz(model_DF, out_file='tree.dot',
feature_names=X_train_ename,
rounded=True, precision = 1)
# 3.使用dot文件构造图
graph= pydotplus.graph_from_dot_file('tree.dot')
Image(graph.create_png())
📍 将决策树可视化
这是将决策树模型导出为 Graphviz 的.dot格式文件的函数。这个.dot文件可以被 Graphviz 工具转换为可视化的树形图
export_graphviz(model_DF,out_file,feature_names,rounded,precision,class_names,special_characters,filled,leaves_parallel)
| 字段 | 数据类型 | 含义 |
| model_DF | Scikit-learn 决策树模型对象 |
想要导出的决策树模型 |
out_file |
str | 输出的 .dot 文件的文件名或文件路径。如果文件不存在,该函数会创建它。如果文件已存在,它可能会被覆盖(取决于文件打开模式) |
feature_names |
list or array | 用于标识决策树中每个特征的名称列表。这个列表应该与训练数据集中特征的数量和顺序相匹配 |
rounded |
bool | 如果为 True,则树中的数值(如节点中的样本数或特征值)将被四舍五入到最接近的整数。这有助于使树更简洁,特别是在数值很大或有很多小数位的情况下 |
precision |
int | 用于指定树中数值的精度(小数点后的位数)。例如,如果 precision=1,则数值将被四舍五入到一位小数。这个参数仅在 rounded=True 时有意义 |
class_names |
list or array | 指定类别标签的名称(仅对分类树有意义) |
special_characters |
bool | 决定是否转义 Graphviz 中的特殊字符 |
filled |
bool | 如果为 True,则绘制节点以显示类别比例 |
leaves_parallel |
bool | 如果为 True,则绘制所有叶子节点在树的同一层上 |
4️⃣ 查看特征重要性并绘制条形图
# 1.查看特征重要性
feature_importance = pd.Series(model_DF.feature_importances_, index=X_train.columns).sort_values(ascending=False)[:5]
print(feature_importance)
# 2.绘制水平条形图
plt.figure(figsize=(8, 6))
plt.bar(feature_importance.index,
feature_importance.values,
color=['b', 'k', 'g', 'y', 'm'])
plt.title('特征重要性条形图', fontsize=15)
plt.xlabel('特征', fontsize=15)
plt.ylabel('重要性', fontsize=15)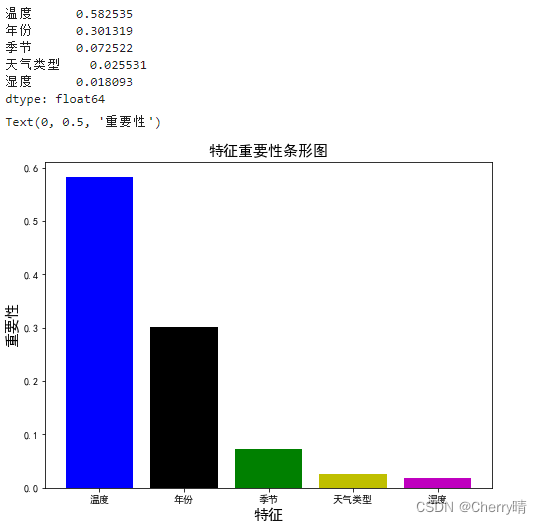
注意:本文中数据以及内容若有侵权,请第一时间联系删除。
本文未经作者授权,禁止转载,谢谢配合。