NumPy(Numerical Python)是用Python编写的科学计算库,用来存储大型矩阵和执行大型矩阵的科学计算,在数据处理特别是科学计算方法具有独特优势,它包含:
- 一个强大的N维数组对象ndarray。
- 丰富的广播功能函数
- 整合C/C++/Fortran代码的工具
- 线性代数、博立叶变换、随机数生成等功能
一、数据获取
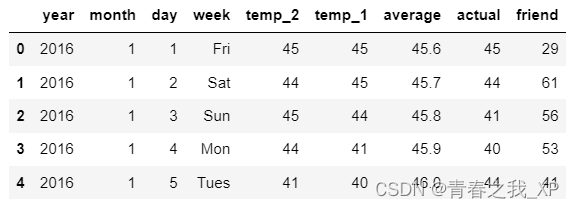
要分析某地区的空气 质量状况,首先要取得该地区空气质量的历史数据
1、通过网络爬虫获取
按需编写
2、直接从网站下载
二、数据预处理
1、读取数据
NumPy提供的loadtxt()函数,能够快速地实现文本数据的读取:
import numpy as np
data = np.loadtxt(fname="数据集/aqi.csv",delimiter=",",skiprows=1,dtype=float)- 首先导入NumPy库(简称np),通过NumPy的loadtxt函数读取csv文件。
loadtxt()函数常用参数:
| 参数 | 含义 | 例子 |
|---|---|---|
| fname | 加载的文件路径 | fname="../data/aqi.csv";读取上级目录data下的aqi.csv文件 |
| delimiter | 数据之间的间隔符 | delimiter=",";数据集之间以逗号分离 |
| skiprows | 忽略数据的位置 | skiprows=1;忽略第一行(第一行为标题,不需要读取) |
| dtype | 数据类型 | dtype=float;设置数据类型为float |
查看data中的数据:
print(data)查看data的属性:
print(data.shape) # 数组的维度 (1236, 11)
print(data.size) # 数组中元素总个数 135962、合并多个数据
2.1、垂直合并
data1 = np.loadtxt("数据集/aqi_2017.csv",delimiter=",",skiprows=1,dtype=float)
data2 = np.loadtxt("数据集/aqi_2018.csv",delimiter=",",skiprows=1,dtype=float)
data3 = np.vstack((data1,data2)) # 按行合并两个文件通过vstack()函数实现垂直合并数据功能。需要注意的是,在合并的文件中,字段的顺序和数量要保持一致。
2.2、水平合并
data4 = np.loadtxt("数据集/aqi_1.csv",delimiter=",",skiprows=1,dtype=float)
data5 = np.loadtxt("数据集/aqi_2.csv",delimiter=",",skiprows=1,dtype=float)
data6 = np.hstack((data4,data5))通过hstack()函数实现水平合并数据功能。注意:在合并的文件中,数据的数量和顺序要一样。
2.3、其它方法
在NumPy中,除了上述两种方法外,还可以使用row_stack()和column_stack()函数实现同样的功能。另外还可以使用concatenate()函数来实现垂直合并和水平合并功能:
np.concatenate((data1,data2),axis=0) # axis=0表示垂直合并
np.concatenate((data4,data5),axis=1) # axis=0表示水平合并NumPy的dstack()方法可以实现深度合并:
r = np.array([[1,2,3],
[4,5,6],
[7,8,9]])
g = np.array([[10,11,12],
[13,14,15],
[16,17,18]])
b = np.array([[20,30,40],
[50,60,70],
[80,90,100]])
color = np.dstack((r,g,b))
# 结果为:
# [[[ 1 10 20]
# [ 2 11 30]
# [ 3 12 40]]
#
# [[ 4 13 50]
# [ 5 14 60]
# [ 6 15 70]]
#
# [[ 7 16 80]
# [ 8 17 90]
# [ 9 18 100]]]
# 可知,dstack方法将r,g,b中对应位置上的数合并起来,生成三位数组3、ndarray数据结构
NumPy的多维数组对象:ndarray。类似于Python的列表。只能存储单一数据类型
| 参数 | 含义 |
|---|---|
| np.array(x,dtype) | 将x转换为ndarray对象 |
| np.ones(shape,dtype) | 生成一个维度为shape、值全为1的ndarray对象 |
| np.zeros(shape,dtype) | 生成一个维度为shape、值全为0的ndarray对象 |
| np.empty(shape,dtype) | 生成一个维度为shape、未初始化的ndarray对象 |
| np.eye(N) | 生成一个N*N的单位矩阵(对角线元素为1,其余元素为0) |
4、去除冗余数据
4.1、去除无用数据
delete()函数可以删除任意行或列的数据:
data = np.delete(data,0,axis=1) # 删除第一列数据
# 如果要一次性删除多列,比如删除前三列数据:
data = np.delete(data,[0,1,2],axis=1)4.2、去除重复数据
unique()函数可以删除重复的数据:
data = np.unique(data,axis=0) # 按行删除重复数据
data = np.unique(data,axis=1) # 按列删除重复数据5、数据持久化存储
5.1、保存为文本文件
savetxt()方法可以将数据保存为文本文件:
np.savetxt("aqi2.csv",data,fmt="%.2f",newline='\n')5.2、保存为二进制文件
save()函数以二进制格式保存数据,load()方法从二进制文件中读取数据:
np.save("aqi",data) # 保存数据
data = np.load("aqi.npy") # 读取数据三、科学计算
1、获取任意范围样本数据
5.1、索引的使用
- 使用索引可以定位到行或列
- 索引的值可以从0开始
- 索引的值也可以从-1开始
- 使用逗号分割行和列
# 获取第1行数据:
data[0] # 方式1:使用索引,自上而下
data[-8] # 方式2:使用索引,自下而上
# 获取第2-4行数据:
data9[[1,2,3]] # 将所有要获取的行索引存放到列表中
# 获取第3行第4列的数据:
data[2,3] # 使用逗号分隔行和列,逗号左边代表行索引,右边代表列索引5.2、切片的使用
- 使用切片抽取行或列中某个范围的数据
- 切片的起止位置用冒号:分隔开
- 将索引和切片结合起来使用,可以截取任意范围的数据
# 获取前3行数据
data[0:3,:] # 方法1
data[:3,:] # 方法2
data[:3,] # 方法3
# 获取第2-4行中第3-5列数据
data[1:4,3:5] # 注意行和列的终止索引分别是4和5
# 获取第2-5列数据:
data[:,1:5] # 注意逗号左边的冒号不可以省略
# 获取最后3列数据
data[:,-3:] # 注意data[:,-3:-1]的写法是错误的2、计算特征的最小值、最大值和平均值
ndarray常用计算函数:
| 计算方法 | 说明 |
|---|---|
| ndarray.mean(axis) | 求平均值 |
| ndarray.sum(axis) | 求和 |
| ndarray.cumsum(axis) | 累加 |
| ndarray.sumprod(axis) | 累成 |
| ndarray.std(axis) | 求标准差 |
| ndarray.var(axis) | 求方差 |
| ndarray.max(axis) | 求最大值 |
| ndarray.min(axis) | 求最小值 |
例子:
# 计算数据集中data中AQI的平均值、最大值和最小值
data[:,-1].mean(axis=0) # AQI的平均值
data[:,-1].max(axis=0) # AQI的最大值
data[:,-1].min(axis=0) # AQI的最小值
# 分别计算NO2、CO和O3的最小值
data[:,-4:-1].min(axis=0)
# ndarray数组还可以与标量进行运算:
data1 = [[1,2,3],
[4,5,6]]
data2 = np.array(data1)
data2 = data2*2 + 1
# 将数组中所有的数都变为原来的一半
data1 = [[1,2,3],
[4,5,6]]
data2 = np.array(data1)
data2 = data2/23、统计
where()函数能得到符合条件的数据的索引
# 首先统计空气质量等级为优的天数
t=np.where(data[:,-1]<35) # 得到所有符合条件的索引
print(t)
style1=len(t[0]) # 得到索引的数量
# 统计空气质量等级为良的天数
t=np.where((data[:,-1]>=35) & (data[:,-1]<75)) # 使用&分隔多个筛选条件
style2=len(t[0])
# 统计空气质量等级为差的天数
t=len(np.where(data[:,-1]>=75)[0])4、预测空气质量
4.1、矩阵乘法原则
已知矩阵A和矩阵B,AB表示两个矩阵相乘,计算方法是将矩阵A中的每一行分别与矩阵B中每一列对应的元素相乘再相加。
矩阵A的列数必须等于矩阵B的行数。
4.2、NumPy矩阵乘法
dot(A,B)函数可以实现矩阵A和矩阵B的乘法运算:
import numpy as np
data = np.loadtxt("数据集/aqi_new.csv",delimiter=",",skiprows=1,dtype=float)
A = data[:,3:-1] # 提取特征
B = [1.4,0.2,-0.05,-0.01,2.4,0.1] # 参数
B = np.array(B) # 转换为ndarray对象
B = B.reshape(6,1) # 转换为6行1列
result = np.dot(A,B) # 矩阵乘法
print(result)四、总结
数据分析流程和实现函数:
| 流程 | 具体任务 | 实现函数 |
|---|---|---|
| 项目需求分析 | 项目介绍,项目流程和项目目标 | |
| 环境搭建 | Anaconda和Pycharm的介绍和安装 | |
| 数据获取 | 获取项目需要的数据集 | 方法1:通过网络爬虫从网络中获取。方法2:直接从提供数据的网站下载 |
| 数据预处理 | 读取数据 | np.loadtxt():读取文本文件。np.load():读取二进制文件 |
| 合并多个数据 | np.vstack():按行合并。np.hstack():按列合并 | |
| 去除冗余数据 | np.delete() | |
| 数据持久化存储 | np.savetxt():存储为文本形式。np.save():存储为二进制形式 | |
| 科学计算与统计 | 获取任意范围的样本数据 | 索引和切片 |
| 计算特征的最小值、最大值和平均值 | ndarray.min()、ndarray.max()、ndarray.mean() | |
| 统计不同空气质量等级的数量 | np.where() | |
| 计算空气质量 | np.dot() |