场景文本检测&识别学习 day03 (Error解决)
- 开发
- 19
-
Error解决
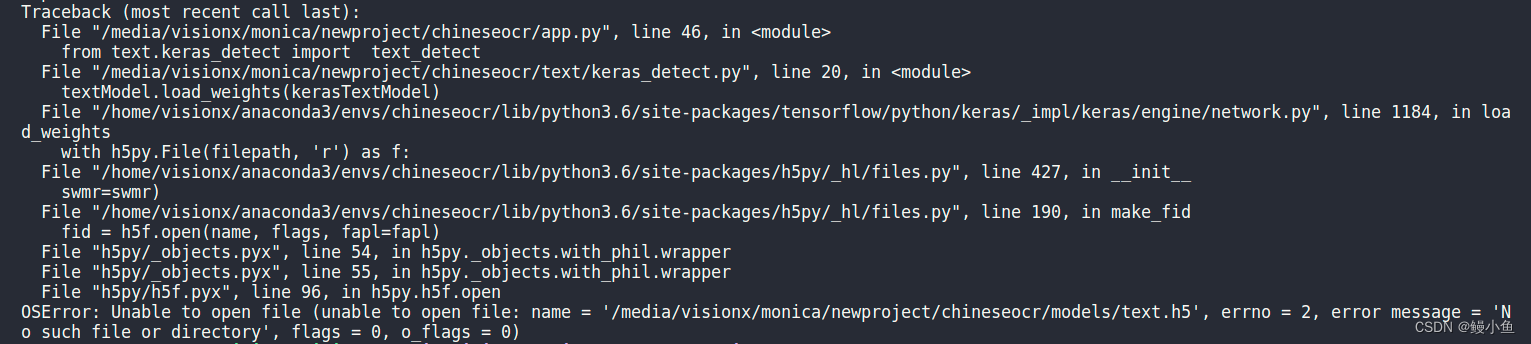
- CUDA out of memory ,在模型的训练过程中,可能一开始会报这个错,也可能运行几个迭代之后报这个错,具体报错解决如下:
--amp
AMP技术解释
- AMP(自动混合精度)是一个用于深度学习训练中的技术,它通过智能地使用半精度(浮点16)和全精度(浮点32)浮点运算来加速模型的训练并减少内存使用。
- 提高训练速度:
- 运算加速:半精度浮点数(FP16)比全精度浮点数(FP32)需要的内存更少。这允许GPU在相同时间内处理更多的数据
- 网络吞吐量提升:由于数据包大小减小,使用FP16可以在GPU上加载更多的数据和模型参数
- 减少内存使用:
- 节约内存: FP16相比FP32可以节约一半的内存,这对于大模型数据和大批量数据尤其重要,因为它们对显存的需求非常高
- 允许更大的批量大小:由于每个数据点使用的内存减少,可以在不超过GPU内存限制的情况下增加批量大小,这有助于更稳定和有效的训练
- 为什么AMP可以避免超出显存:
- 现存管理优化:AMP提供了动态的显存管理技术,这包括在必要时自动调整数据的精度。例如在某些操作中使用FP16,在需要高精度计算的操作中自动切换回FP32,这样既保证了计算精度,又优化了显存使用
- 避免内存溢出:通过减少单个数据元素的内存需求,AMP可以有效降低整体内存消耗,这样在相同的硬件条件下,可以运行更大的模型或者使用更大的数据批量。从而避免因内存不足而导致的程序崩溃或者性能下降
- 如何使用AMP:
- 使用torch.cuda.amp模块来实现自动混合精度,该模块提供了“autocast”、"GradScaler"这两个工具,其中“autocast”用于自动调整运算的数据类型,“GradScaler”用于调整梯度的规模,防止在使用FP16时因数值范围限制而造成的梯度下溢。
原文地址:https://blog.csdn.net/u011453680/article/details/137678264
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。
本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:https://www.suanlizi.com/kf/1778679956956647424.html
如若内容造成侵权/违法违规/事实不符,请联系《酸梨子》网邮箱:1419361763@qq.com进行投诉反馈,一经查实,立即删除!