场景文本检测&识别学习 day01(传统OCR的流程、常见的损失函数)
2024-04-07 01:16:03 开发 16
传统OCR:传统光学字符识别
常见的的模型主要包括以下几个步骤来识别文本
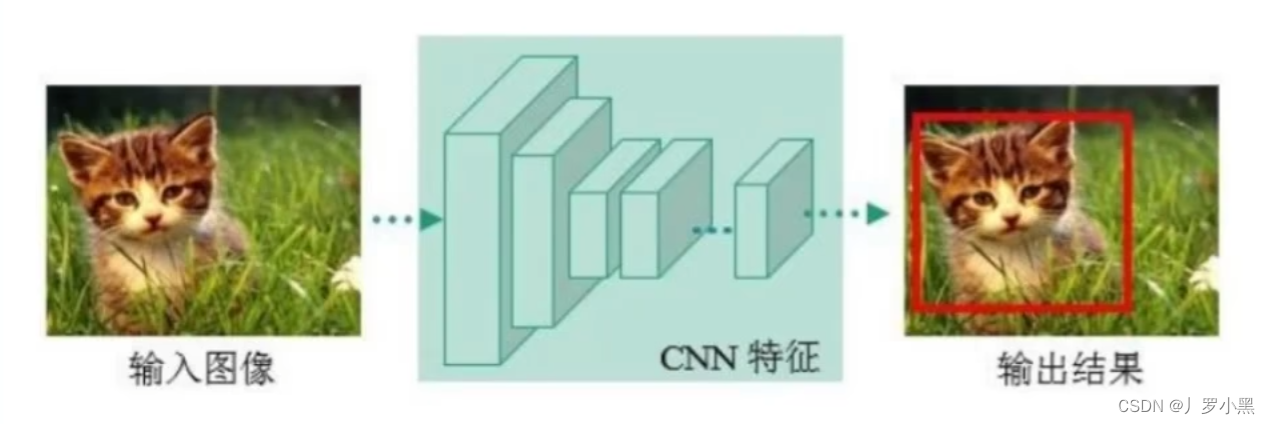
预处理 :预处理是指对输入的图像进行处理,以提高文字识别的准确率。这可能包括调整图像大小、转换为灰度图像、二值化(将图像转换为黑白两色)、去噪声、校正图像中的倾斜等步骤。目的是减少图像中的干扰信息,并突出文字部分。文本检测 :文本检测的目的是在图像中定位文本的位置。这一步骤要解决的主要问题是识别图像中哪些区域包含文字。使用的模型通常是基于深度学习的,例如卷积神经网络(CNN)。这些模型可以学习文本的形状、大小和布局,从而在各种背景下准确地识别出文本区域。文本识别 :在文本区域被检测出来之后,下一步是识别这些区域内的具体文字。这通常涉及到将文本区域内的图像转换为可编辑的文字。在这个阶段,也常使用基于深度学习的模型,如循环神经网络(RNN)和长短期记忆网络(LSTM),它们对处理序列数据(如文字串)特别有效。这些模型能够识别和理解文本区域内每个字符的顺序,进而转换成文字。后处理 :后处理步骤包括纠正识别出的文字中的拼写错误、语法错误等。可以使用词典、语言模型等工具来提高文本的准确性。例如,如果识别出的文字是英文,可以使用英语词典来检查和纠正单词的拼写错误。
其中对于文本识别,又有以下几个步骤:
字符分割:在一些传统的OCR系统中,一个重要的步骤是字符分割,即将文本区域内的图像分割成单个字符。这需要算法识别每个字符之间的空隙,以便单独处理每个字符。然而,这种方法在处理复杂背景或字体、连笔文字(如手写或某些印刷体)时可能会遇到困难。
特征提取:特征提取是识别过程中的一个关键步骤。它涉及到从每个已识别的字符图像中提取有用的信息,这些信息对于后续的分类和识别至关重要。特征可以是基于像素的(如图像的形状、边缘),也可以是更高级的特征(如通过深度学习模型自动学习到的特征)。
字符识别:在特征被提取之后,下一步是使用这些特征来识别每个字符。这通常通过分类算法完成,如支持向量机(SVM)、随机森林或深度学习模型(如卷积神经网络CNN)。深度学习方法,尤其是CNN,由于其强大的特征学习能力,已经成为最流行和最有效的方法之一。
序列建模:对于连续文本(例如句子或段落),仅仅识别单个字符是不够的;还需要理解字符之间的顺序关系。循环神经网络(RNN)和长短期记忆网络(LSTM)等模型特别适合处理这类序列数据。这些模型不仅可以识别单个字符,还能学习字符之间的依赖关系,提高整体识别的准确性。
(可选)语言模型:在识别出文本之后,语言模型可以用来进一步提高识别的准确性。通过分析词汇的语境,语言模型可以帮助纠正拼写错误,甚至是基于上下文推断出模糊或缺失的字符。这一步是提高OCR系统输出质量的重要环节。
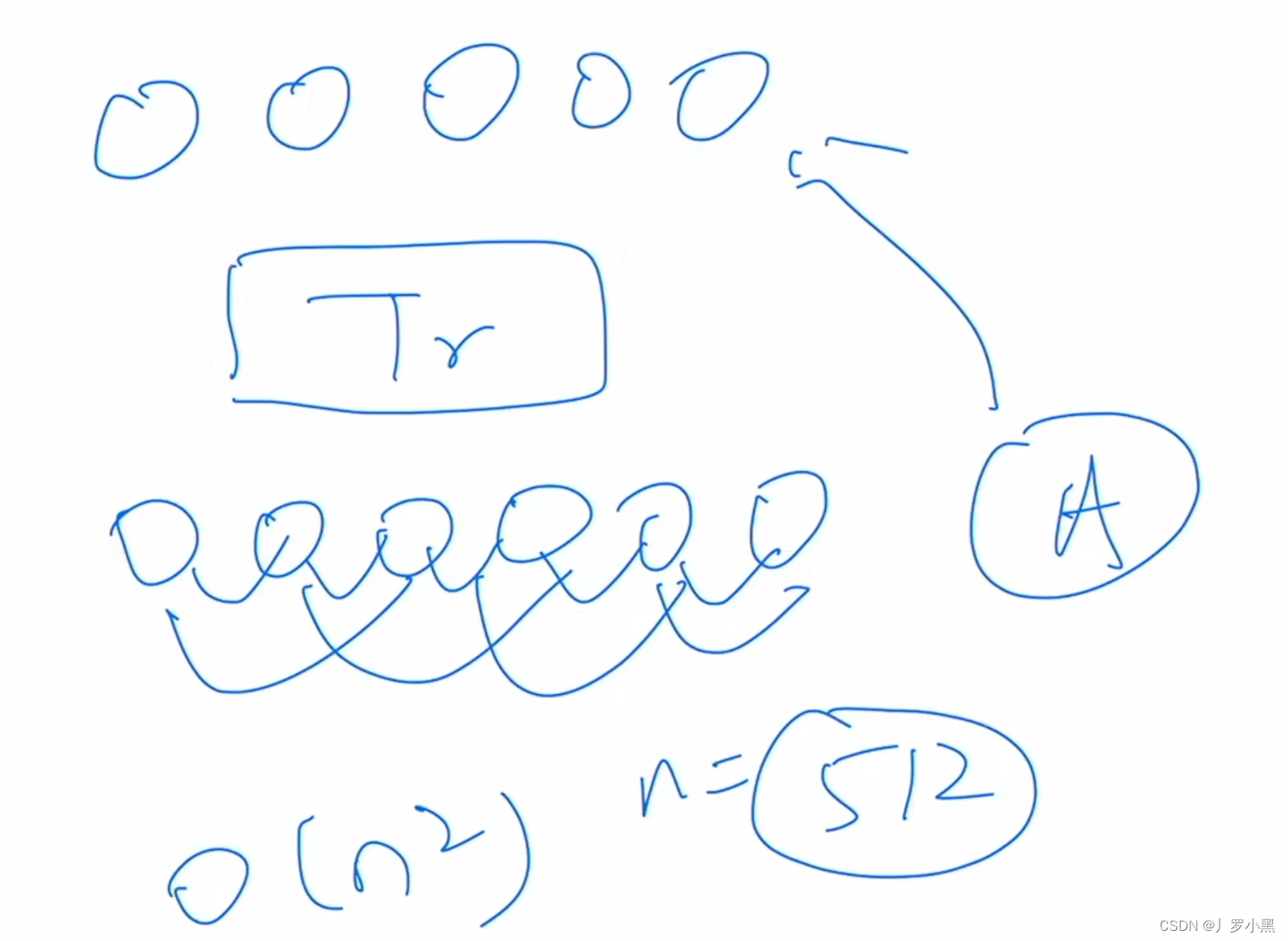
定义:L1损失,也称为最小绝对偏差(Least Absolute Deviations,LAD)损失,是实际值与预测值之差的绝对值的和。对于边界框预测来说,L1损失可以定义为预测框和真实框坐标之间差异的绝对值的和。
公式:如果有一个真实框坐标为(x,y,w,h)其中x,y是框的中心坐标,w,h是框的宽度和高度,预测框坐标为(x̂,ŷ,ŵ,ĥ),则L1损失可以表达为:
特点:L1损失对于异常值(outliers)不那么敏感,因为它不像平方误差损失(L2损失)那样对较大的误差赋予更高的权重。这使得L1损失在处理有噪声的数据时比较有优势。
定义:GIoU损失是IoU(Intersection over Union)的一种推广,用于测量两个框的重叠度。IoU仅考虑了框之间的交集和并集,而GIoU还考虑了框之间不重叠的情况,提供了更全面的测量。
公式:GIoU在IoU的基础上增加了一个项,考虑了最小封闭框(即同时包含预测框和真实框的最小框)与预测框和真实框之间的关系。其中,IoU是交集与并集的比例,C是最小封闭框的面积,U是预测框和真实框的并集面积。GIoU损失定义为:
特点:GIoU损失解决了IoU在某些情况下无法有效反映框之间差异的问题(例如,当两个框不重叠时,IoU为0,但这并不意味着它们的距离相同)。通过考虑最小封闭框,GIoU提供了一种更有效的方式来度量和优化边界框的位置和大小。
定义:焦点损失是交叉熵损失的一个变种,旨在解决类别不平衡问题,特别是在一类样本数量远多于另一类样本的情况下。它通过减少那些已经被正确分类的样本对损失函数的贡献,来增加模型对难以分类样本的关注度。
公式: p t p_t p t p t p_t p t 1 − p 1−p 1 − p α t α_t α t
特点:
原文地址:https://blog.csdn.net/u011453680/article/details/137427207
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。
本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:https://www.suanlizi.com/kf/1776660149755318272.html
如若内容造成侵权/违法违规/事实不符,请联系《酸梨子》网邮箱:1419361763@qq.com进行投诉反馈,一经查实,立即删除!
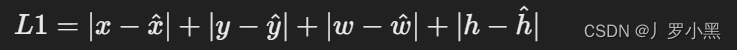
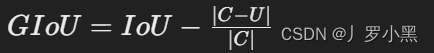
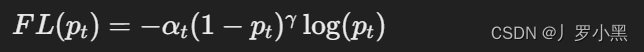


























![练习 16 Web [极客大挑战 2019]LoveSQL](https://img-blog.csdnimg.cn/direct/a9c41cc42b044f21a2ea98ba7c03775a.png)