Transformer论文精读
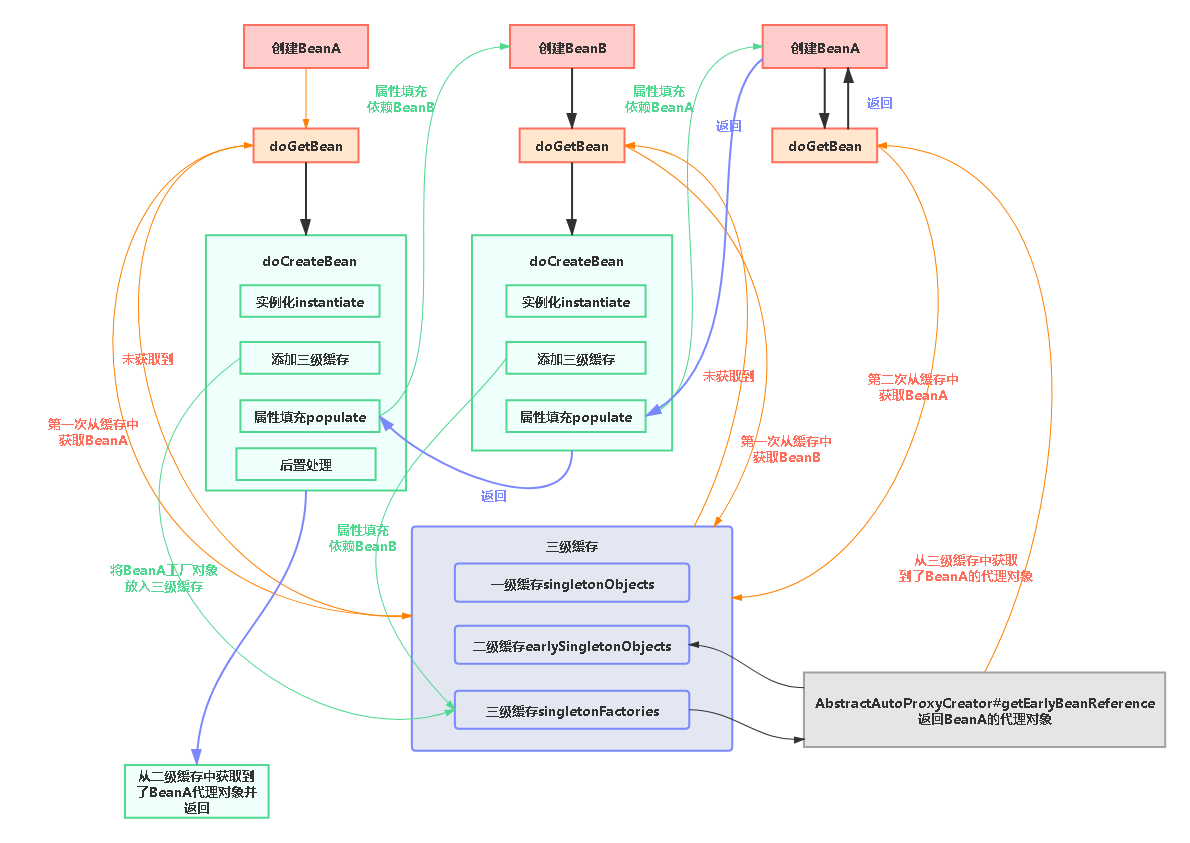
- Transformer是第一个仅仅使用注意力机制来做序列转录的模型,它将所有的循环层都替换为了Multi-Head Self-Attention。
- Multi-Head Self-Attention是为了模拟CNN中卷积核的多输出通道的效果,即每个卷积核的输出(卷积核的每个输出通道)都可以识别不一样的模式
- 简要流程:
- 对于一个序列输入( x 1 x_1 x1,…, x n x_n xn),其中 x n x_n xn表示序列句子中的第n个词,这个序列经过编码器层得到Z = ( z 1 z_1 z1,…, z n z_n zn),其中 z n z_n zn表示序列句子中的第n个词的向量表示,即编码器层将输入变成机器可以理解的向量形式
- 解码器层就会拿到Z,最后生成一个序列( y 1 y_1 y1,…, y m y_m ym),这里的n和m可以不一样
- 注意:在编码器层,模型可以一次看完整个输入,但是在解码器层,模型只能一个一个的输出,由于这里采用的自回归输出(输出又是输入,过去时刻的输出作为当前时刻的输入)
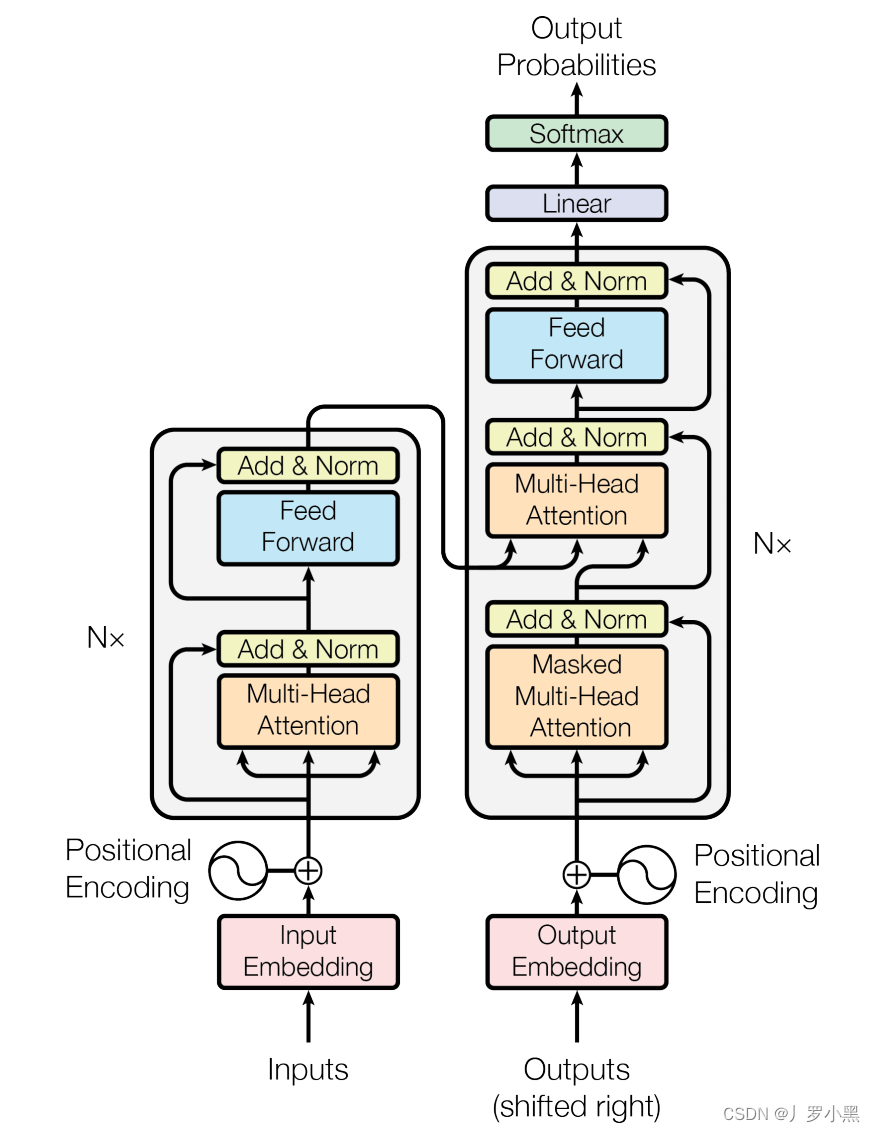
- Transformer的详细流程:
- 先将输入语句经过 input embedding (嵌入矩阵)变成机器可以理解的向量形式,通常是使用已经训练好的生成词向量的模型来进行,但是这个词向量只能代表单个词,缺乏整体的语义特征和语法特征,也缺乏位置信息,因此这些词向量还不能完成更复杂的任务,机器翻译、文本生成等,同时这个嵌入矩阵在训练过程中也可以进行学习
- 添加位置编码来补充词向量中的位置信息
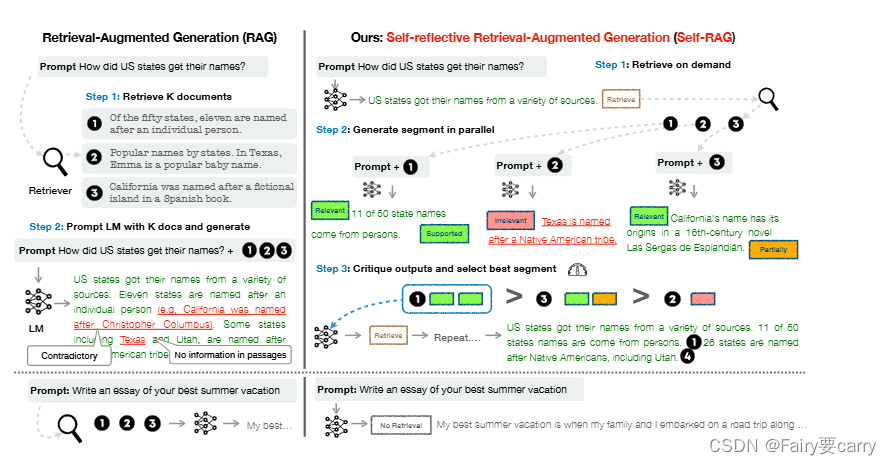
- 随后输入编码器层,编码器层有N个编码器堆叠,每个编码器都有两个子层:Multi-Head Attention 和 FFN,同时每个子层的输出都会经过残差 + 归一化
- 将编码器层输出结果传递给解码器层,解码器层有三个子层:Masked Multi-Head Attention 和 Multi-Head Attention 和 FFN,编码器直接传入第二个子层–Multi-Head Attention。而第一个子层–Masked Multi-Head Attention是用来确保预测和训练统一,即训练时解码器的注意力不会看到还未生成的输出
- 同时解码器为自回归模型,即前一个时刻的输出会作为当前时刻的输入,输入到第一个子层–Masked Multi-Head Attention中
- 注意:在解码器层、编码器层的每一个子层中,都使用了残差连接,由于残差连接需要保持输入和输出的维度一致,如果不一致需要做投影,为了简化,Transformer将维度都设为512
- 注意:在自然语言处理的Embedding层里,由于每个维度的值会很小,同时我们要加上位置编码,为了让这两者没有太大差异,所以我们会将输入乘以 d m o d e l \sqrt{d_{model}} dmodel,同时由于在注意力层,我们是将Q和K做点积然后除以 d m o d e l \sqrt{d_{model}} dmodel,因此一开始如果不放大的话。除以之后,可能会使得softmax函数(用于计算注意力权重)进入饱和区,梯度消失,从而影响训练效果。
- 注意:位置编码一开始就加入到输入中,是因为方便后面的操作,如果后面要进行打乱,那么不会影响到输出结果
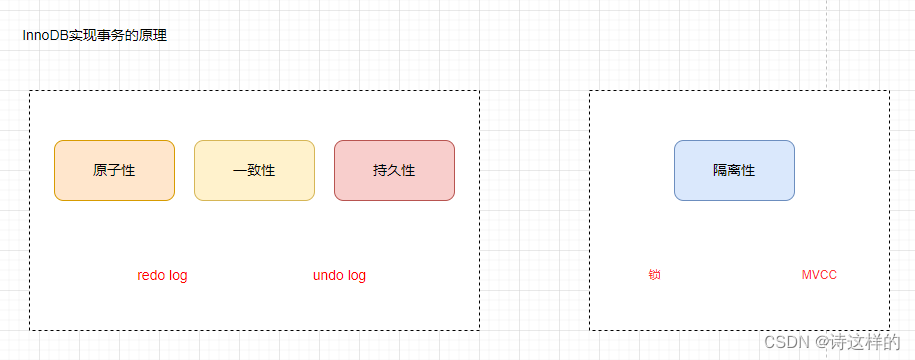
batch normalization 和 layer normalization
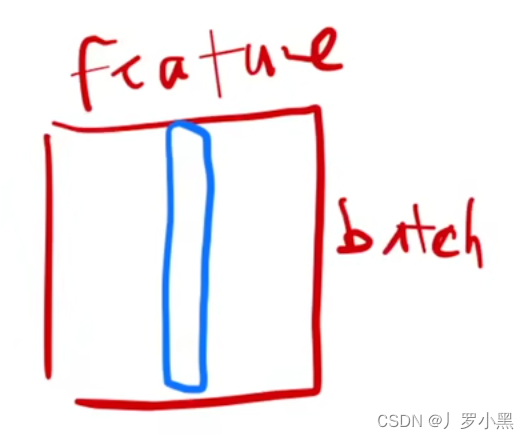
batch normalization:通常使用在等长输出的应用里
具体操作为:当输入数据为二维的,对于一个batch_size的数据,每一次把每一列的数据(每一个特征)均值变成0,方差变成1,即每个数据点都从原始数据值中减去均值,然后除以方差
注意:在batch normalization中,训练时,均值和方差是对于一个batch_size中的该列(该特征)的所有数据来说。在预测时,是将所有训练集数据的该列(该特征)的均值和方差存起来,作为预测的均值和方差
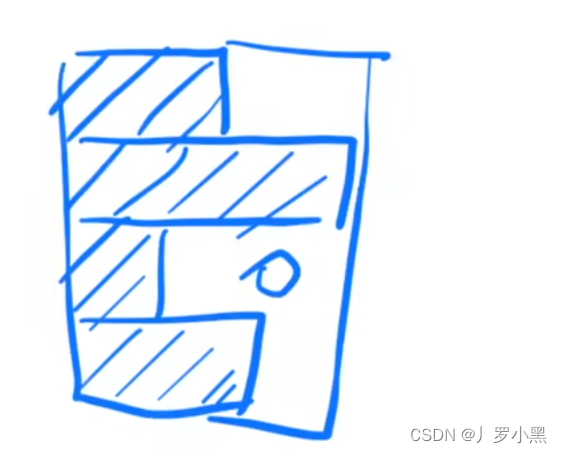
注意:由于我们需要算一个batch_size的每一列的数据(每一个特征),而当我们一个batch_size的数据不等长,即有些样本没有某些特征,我们需要进行补0,
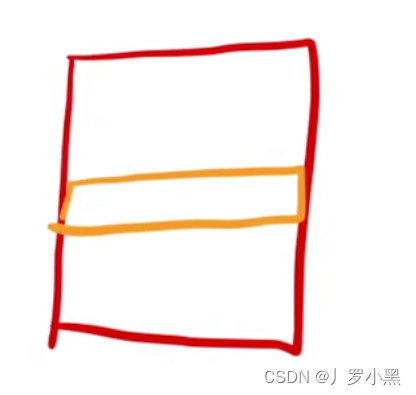
layer normalization:通常使用在变长输出的应用里
具体操作为:当输入数据为二维的,对于一个batch_size的数据,每一次把每一行的数据(每一个样本)均值变成0,方差变成1,即每个数据点都从原始数据值中减去均值,然后除以方差

注意:在batch normalization中,训练时,均值和方差是对于一个batch_size中的该行(该样本)的所有数据来说。在预测的时候,不需要再存训练数据集的数据了,直接算预测的样本的均值和方差即可
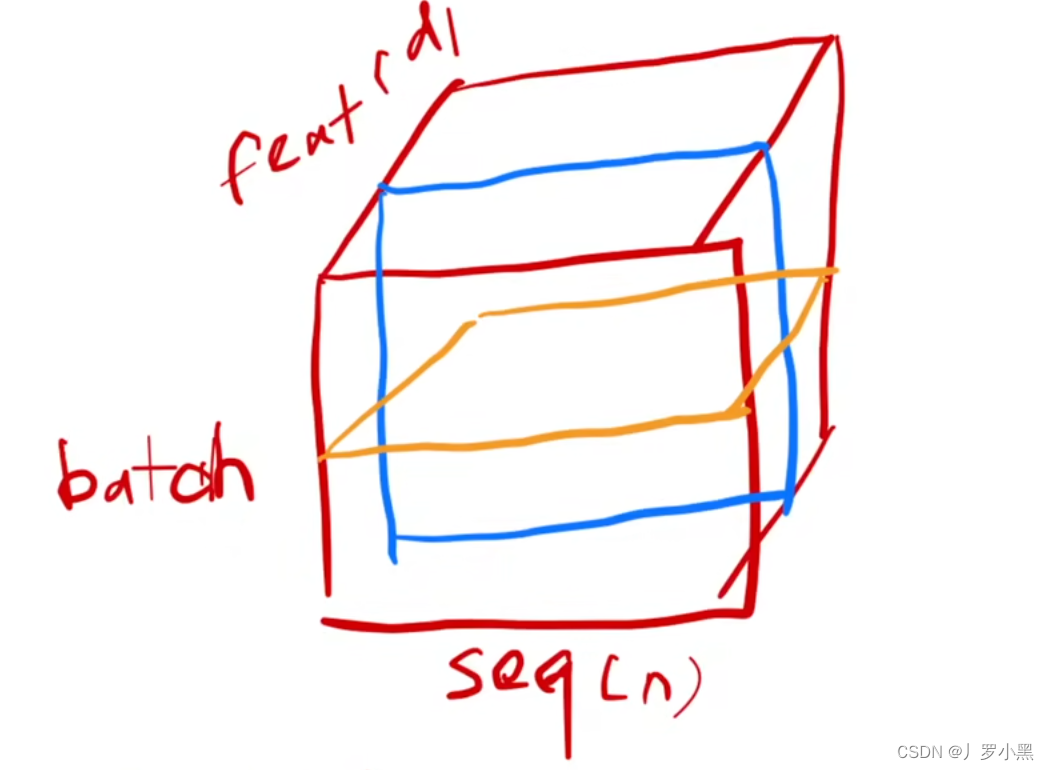
batch normalization:当输入数据为三维的,如下图:
仍然是按列切,即我们需要该batch_size上所有样本的某个特征数据
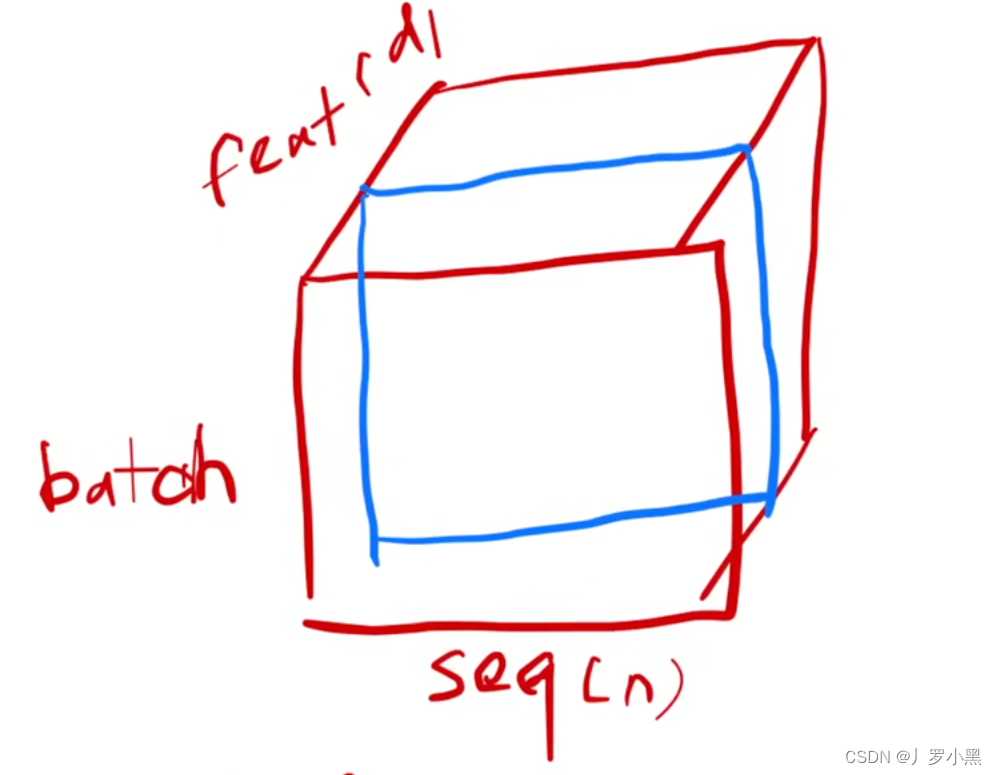
layer normalization:当输入数据为三维的,如下图:
按行切,即我们需要该batch_size上某个样本的所有特征数据
综上:对于batch normalization,如果样本长度变化比较大的时候,那么batch_size间,计算得到的均值和方差会抖动很大,同时如果预测的是全新的样本且长度很大,那么之前保存的全部训练数据集的均值和方差不是很好用。
对于layer normalization,由于我是对每个样本来算均值和方差,所以不需要存全局的均值和方差,同时由于只在自己样本内部进行计算,所以相对稳定一些
注意力机制

- 注意力机制可以表示为将查询(Query)、键(Key)和值(Value)向量映射到输出的过程。具体来说,输出是V的加权求和,权重由Q和相应K的相似度决定。每一个q都会得到一个输出,且在transformer中由于残差连接,所以输入和输出的维度一样。
- Transformer使用的是缩放点积注意力机制,缩放因子通常是键的维度的平方根。即在计算Q和K的相似度后,会除以一个缩放因子,来避免输入到softmax的是一个特别大的值,这有助于稳定训练过程,如下:

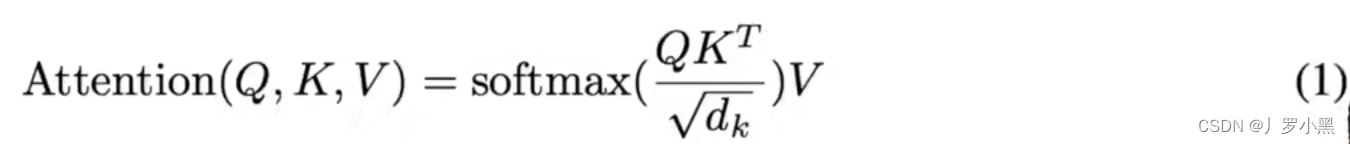
- 具体的矩阵运算如下:

- 注意:由于我们算的每一个q的注意力值Z,是需要V和softmax权重,而这是需要每一个q与所有k的点积得到的S来进行计算的,所以这里为S矩阵的一行和V矩阵的每一列相乘后得到s的softmax概率和为1,而得到的Z矩阵的一行就是我们需要的最终输出,即每一个q都会得到一个输出,一共有n个q,所以输出的个数也是n
- 注意:由于transfmorer使用的是缩放点积注意力,所以在Q和K相乘后需要除以 d k \sqrt{d_k} dk,来避免输入到softmax的是一个特别大的值,这有助于稳定训练过程。当 d k d_k dk不是很大的时候,除不除都可以,但是在transformer里, d k d_k dk为512,这相对来说比较大,所以需要除以 d k \sqrt{d_k} dk,同时也让这些数值尽量分散一点,而不是集中在0和1,避免输入到softmax的数为softmax的饱和区。 d k d_k dk其实就是 d o u t d_{out} dout,如下图:

- 缩放点积注意力的过程如下:
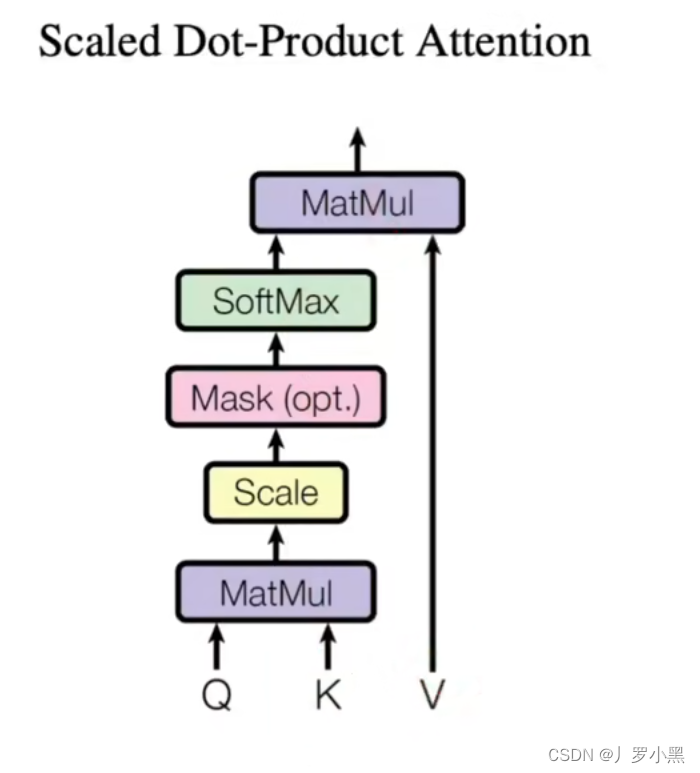
- Masked Attention:为了确保测试和训练统一,需要在计算t时刻的注意力值的时候不看t时刻以后的,这里我们将掩码加在softmax之前,虽然t时刻的q仍然会跟所有的k进行计算,但是我们只需要输出的时候不要用到t时刻以后的就行,这里我们直接将t时刻以后的q和k计算得出的值换成非常大的负数,那么它们在进入softmax后得出权重就为0,所以在最后的输出里只包含了 V 1 V_1 V1到 V t − 1 V_{t-1} Vt−1,就实现了不看t时刻后面的效果。
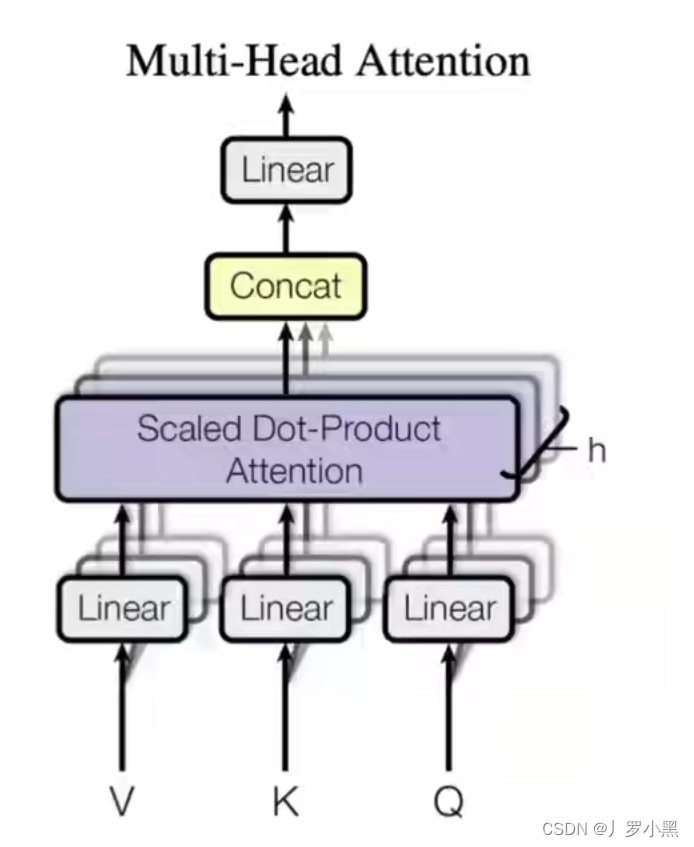
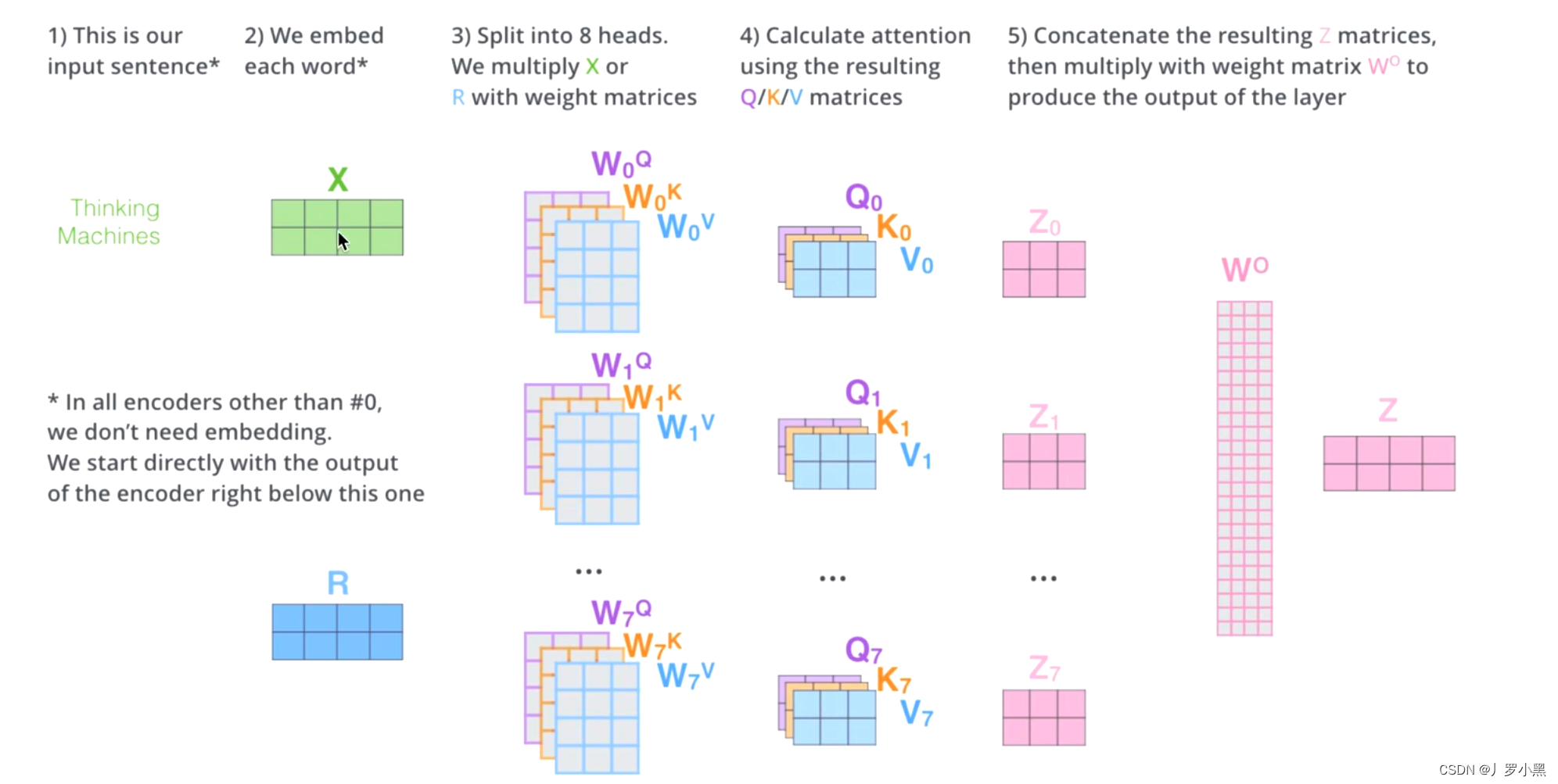
- Multi-Head Self-Attention:将输入x分别送入8套Q、K、V的转换矩阵,并分别得出在该套矩阵下得出的注意力值Z,将 Z 0 Z_0 Z0、…、 Z 7 Z_7 Z7拼接起来,经过一个线性变换,得到与输入x相同维度的Z‘,作为真正的输出
- 注意:转换矩阵不仅仅转换数据,还改变了输入的维度,从原始输入维度 d m o d e l d_{model} dmodel降低至 d k d_k dk,其中 d k d_k dk = d m o d e l / h d_{model} / h dmodel/h,transformer的 h = 8

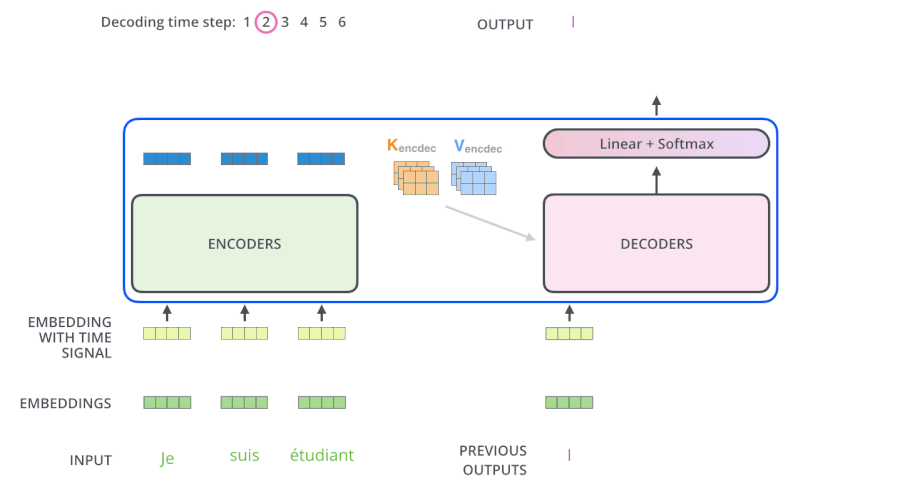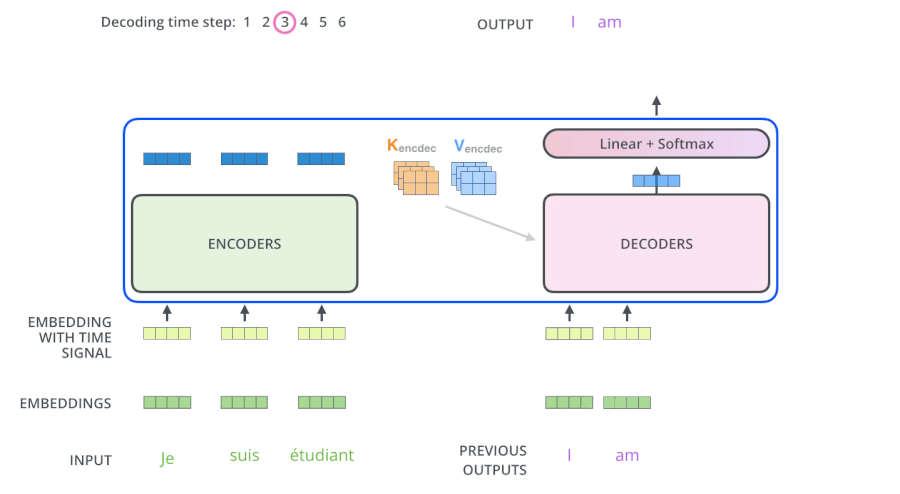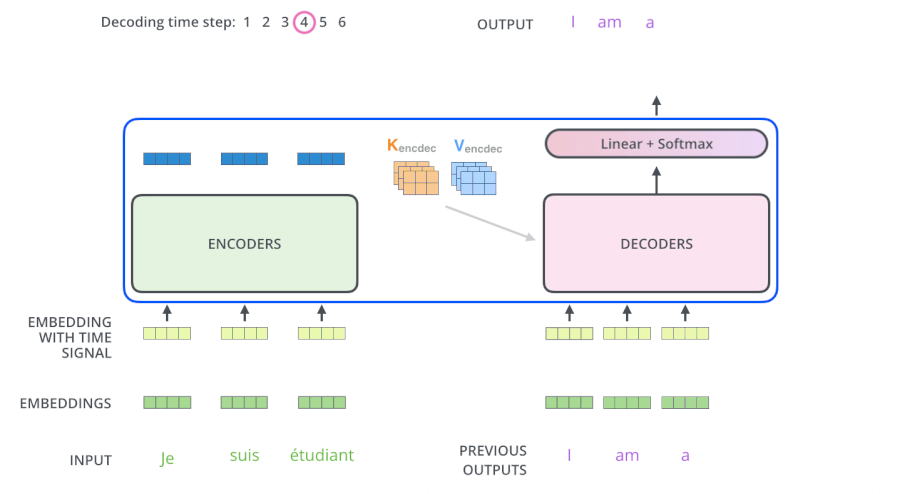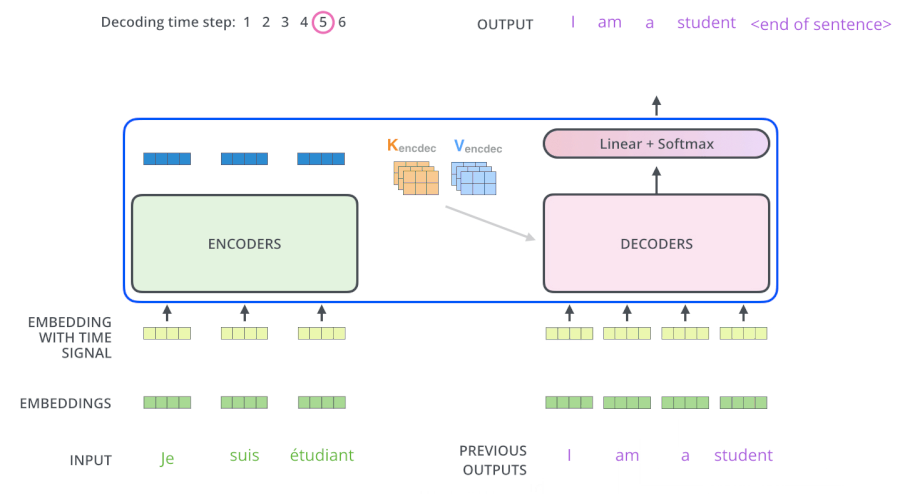

- Cross-Attention:在解码器的内部,Multi-Head Attention其实是一个交叉注意力模块,它使用解码器的前一个Masked Multi-Head Attention的输出作为Q(而前一个Masked Multi-Head Attention是self-Attention,所以它有多少个输入就有多少个输出,每一个q都有一个输出,即每生成一个词就有一个输出),与编码器的输出作为K、V进行注意力计算,得到很多包含下一个将要输出的词的信息的词向量Z‘。这样就能根据解码器的输入,将编码器的输出中我们感兴趣的东西给拿出来
- Z’在经过一个FFN,Softmax来得到最后的输出

- Transformer的模型参数如上图,需要我们调的参数有:N、 d m o d e l d_{model} dmodel、h,其他的参数都是通过公式算出的
FFN
- 语义空间是一个概念模型,它把现实世界的对象(如单词、短语、整个文档或者图片等)映射到一个数学定义的空间中,这个空间能够捕捉和表示这些对象的特征和相互关系。这种表示通常是高维的,并且旨在使得语义上相似或相关的对象在这个空间中距离更近,而不相似的对象距离更远。

- 在Transformer中,FFN层可以看作一个MLP,而且对于Multi-Head Attention的每一个输出作用的是同一个MLP
- 在Transformer中,MLP可以只用一个的原因是:由于在Attention层,我们已经对每个词向量进行全局语义的提取了,因此每个词向量已经包含了全局中感兴趣的部分,所以当我再使用MLP做投影,映射到更想要的语义空间的时候,只需要一个MLP单独做即可,不需要多个了,且使用MLP做投影时也不需要有交互,可以独立进行

- 在RNN中,也是同样使用一个MLP,作为投影,映射到更想要的语义空间,但是这里将上一时刻的输出和当前时刻的输入合并,作为当前时刻的整体输入,这样完成了信息的传递,获得了全局的语义信息
- 所以RNN和Transformer虽然都是使用MLP来做语义空间的转换,但是区别在于如何获取全局的语义信息,RNN是把上一时刻的输出和当前时刻的输入合并,作为当前时刻的整体输入,这样递归的传递来获得全局的语义信息。Transformer是通过Attention层直接获得全局的语义信息
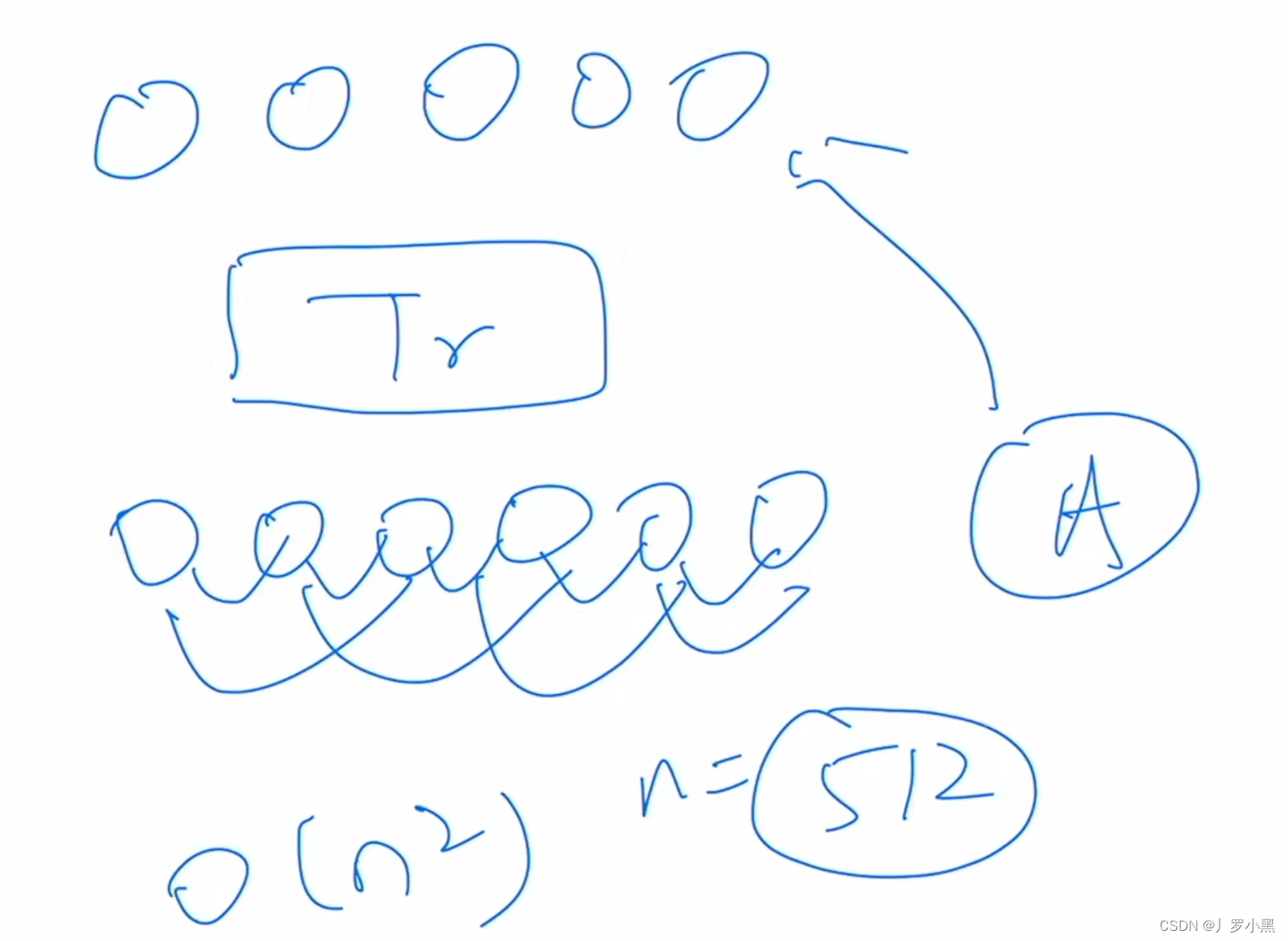
复杂度

- 由图可知,Self-Attention的计算复杂度是 O ( n 2 ∗ d ) O(n^2 * d) O(n2∗d),其中n是输入的词的个数,d是词向量的维度。主要的复杂度为当我们进行Q、K点积的时候,其实是 W q W_q Wq和 W k W_k Wk做矩阵乘法,也就是两个形状为(n,d)的矩阵做乘法,结果为(n,n)矩阵,且矩阵中的每个元素涉及 d 次乘法,和 d-1 次加法,一共 n ∗ n ∗ ( 2 d − 1 ) n * n *(2d-1) n∗n∗(2d−1)次,所以计算复杂度为 O ( n 2 ∗ d ) O(n^2 * d) O(n2∗d),由于Self-Attention内都可以用矩阵乘法做并行,所以顺序计算只需要等前面一步做完即可,等的步数越少那么并行度越高,所以为O(1),同时由于注意力机制是对于每个词都跟全局做注意力计算,因此词与词之间的距离也是可以直接到达,不需要中转,所以也为O(1)
- 在RNN中,由于对n个输入要乘以一个(d,d)的矩阵,即一个全连接层,所以计算复杂度为 O ( n ∗ d 2 ) O(n * d^2) O(n∗d2),同时由于RNN需要等前面的步做完,才能进行下一步的计算,所以为O(n),同时每个词之间的距离也是需要前面的做完,才能到达,所以为O(n)
- 在CNN中,k为卷积核,所以计算复杂度为 O ( k ∗ n ∗ d 2 ) O(k * n * d^2) O(k∗n∗d2),由于卷积可以做并行(单个卷积核可以在输入的不同区域中同时计算,或者同时计算多个卷积核),所以顺序计算也是只需要等前面一步做完即可,所以为O(1),同时由于卷积核的大小为k,所以k距离内的信息可以一次到达,超过了k就需要多层卷积进行叠加,才能到达,所以为O( l o g k log_k logk(n))
- 最后一个为受限的自注意力,用的很少,基本上都用最原始的自注意力
- 综上:当序列的长度和模型的宽度差不多的时候,大家深度都一样的话,前三种模型的计算复杂度都差不多,但是Self-Attention和CNN对于计算会更友好,而且Self-Attention对信息的全局提取上是最好的。但是实际上由于Self-Attention对模型的假设更少,所以需要更大的模型和更多的数据才能做到和CNN、RNN一样的效果
- 现在人们发现,由于Attention使用了一个归纳偏置,使得他能够处理一些更一般化的信息,这就是为什么Attention没有做任何空间上的假设,也能够做到跟CNN一样,甚至更好的结果,但由于归纳偏置更一般化,所以在数据里面抓取信息的能力变差,因此需要更大量的数据才能训练出想要的效果
RNN
- 在传统的RNN中,我们给一个序列,RNN会将序列从左往右一步一步地计算,如果给一个句子,那么RNN会一个词一个词地计算
- RNN处理时序信息的过程:在计算第t个词时候,RNN会计算一个 h t h_t ht作为输出,叫做第t个词的隐藏状态(当前词之前的历史信息)。而 h t h_t ht是由 h t − 1 h_{t-1} ht−1和当前第t个词本身决定的,即根据前一个词的历史信息 h t − 1 h_{t-1} ht−1和当前词t进行计算,得到当前词的历史信息 h t h_t ht
- 综上:RNN通过将之前的历史信息全部放在隐藏状态里,然后一步一步的传下去,得到最后的输出 h t h_t ht
- 缺点:
- 由于是一步一步的计算,所以无法做并行,即当我们计算第t个词的时候,必须保证前t-1个词都计算完成,得到 h t − 1 h_{t-1} ht−1后才可以
- 由于是一步一步的计算,所以如果当时序比较长,那么很早期的时序信息会在后面被丢掉,如果不想丢掉就需要一个很大的隐藏状态,但是这样的话,每一步都需要存一个很大的 h t h_t ht,这很占内存空间
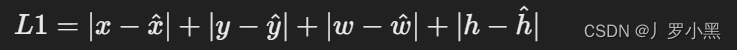

![[nlp入门<span style='color:red;'>论文</span><span style='color:red;'>精读</span>] | <span style='color:red;'>Transformer</span>](https://img-blog.csdnimg.cn/direct/904fe7047f8c4faebc1d4f329695681e.png)

















![[2021最新]大数据平台CDH存储组件kudu之启用HA高可用(添加多个master)](https://img-blog.csdnimg.cn/20210415144108832.png)