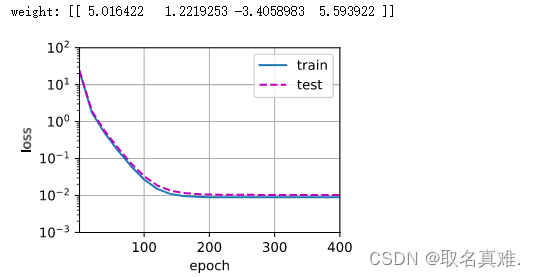
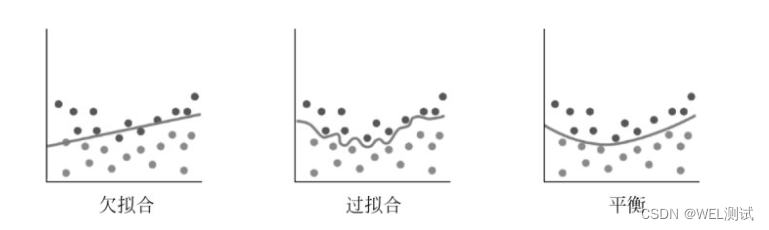
少量样本通常会导致过拟合,而不是欠拟合。过拟合指模型在训练数据上表现良好,但在未见过的测试数据上表现不佳,因为模型过于复杂,试图捕获训练数据中的噪声和细微特征。由于训练数据有限,模型可能会过度适应这些数据的特定特征,而无法泛化到其他数据。相反,欠拟合指模型未能充分捕获数据中的模式和结构,导致在训练和测试数据上都表现不佳。
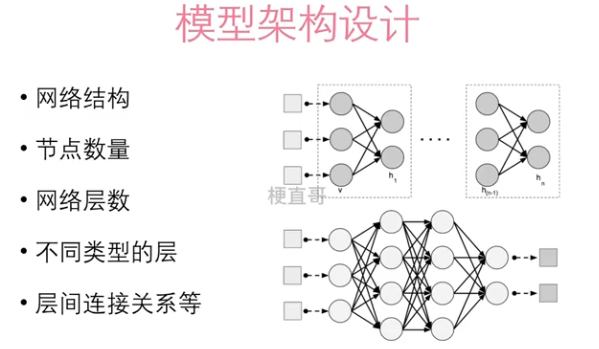
在深度学习中,当训练样本数量较少时,模型可能会过度拟合训练数据,因为参数数量较多的深度学习模型有很强的拟合能力。为了缓解过拟合,可以使用技术如数据增强、正则化、dropout等,以及使用预训练模型等方法来充分利用少量数据。