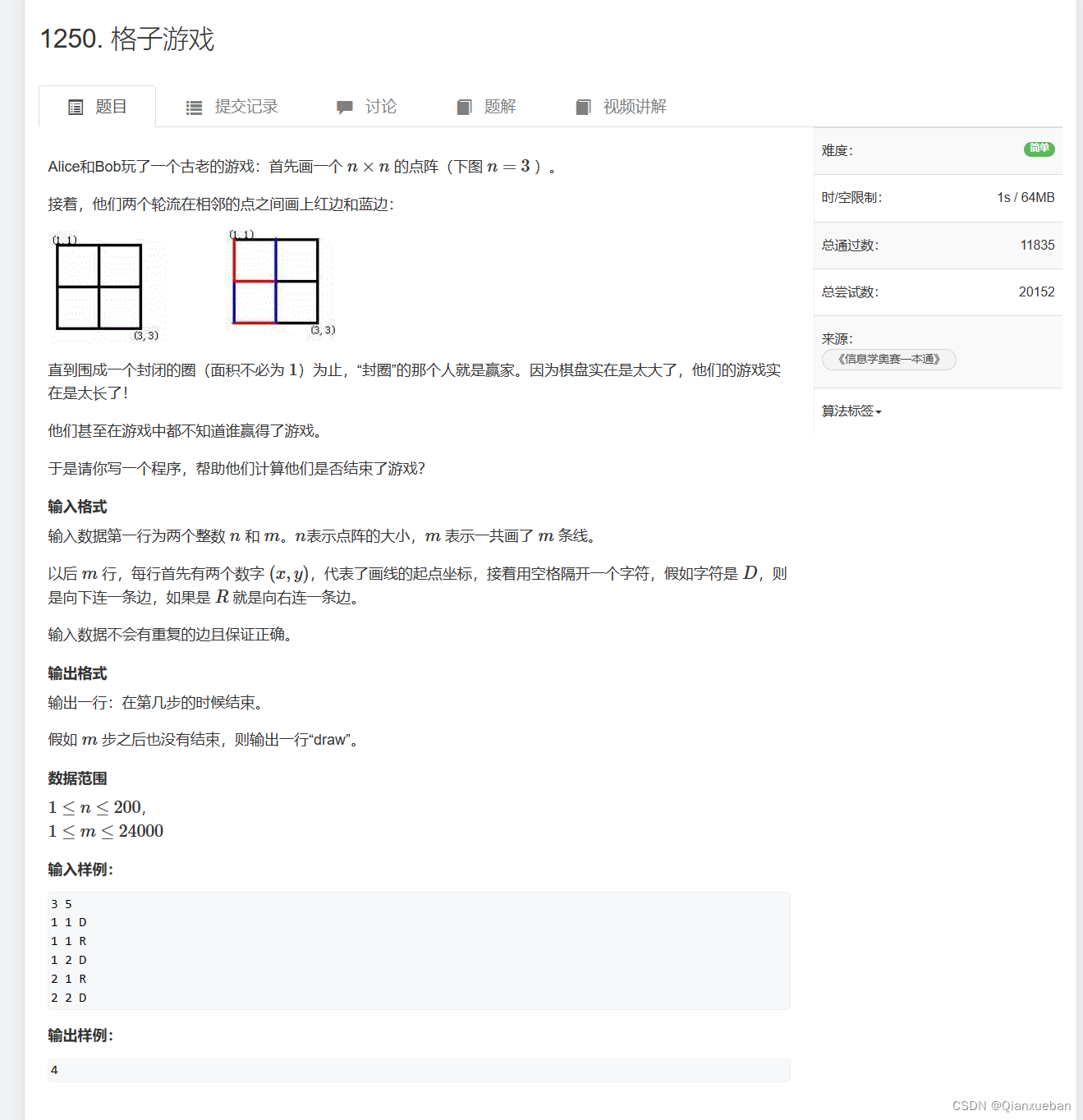
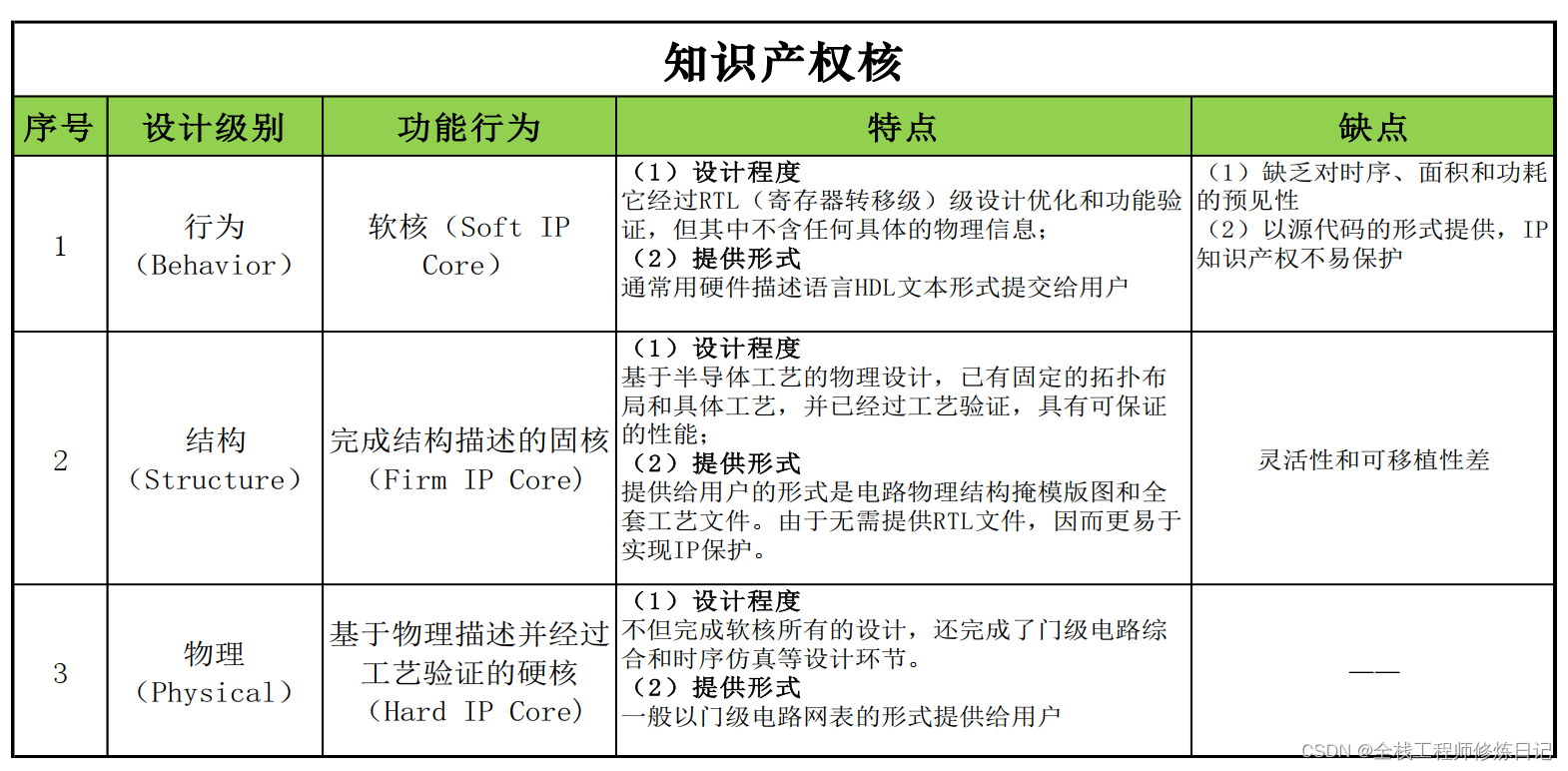
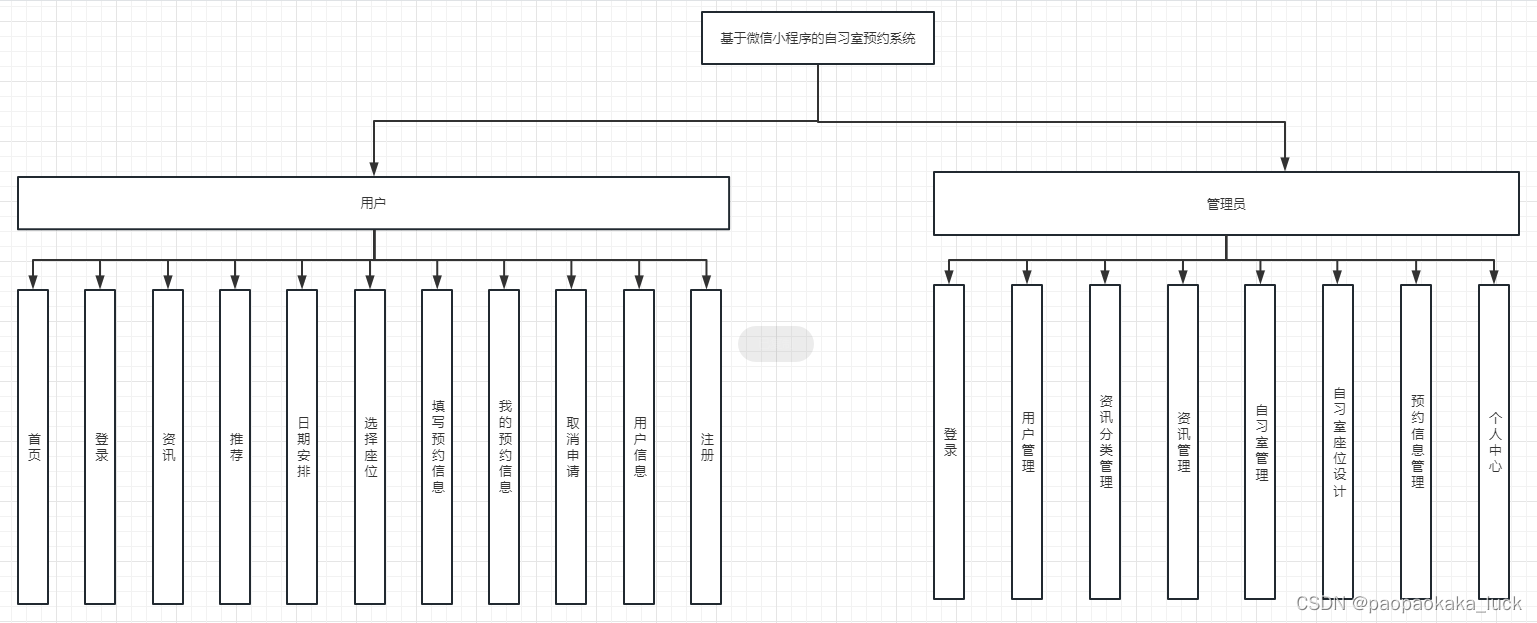
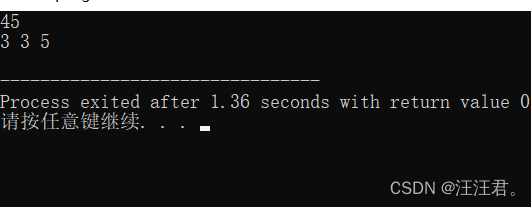
SIMD是(Single Instrument Multi Data),MMX实现了SIMD;SSE是(Streaming SIMD Extension),它取代了MMX;后来AVX(Advanced Vector Extension,高级向量扩展)对SSE进行了扩展。如下代码展示了SSE处理未对齐内存的情况:
; sse_unaligned.asm
extern printf
section .data
spvector1 dd 1.1
dd 2.2
dd 3.3
dd 4.4
spvector2 dd 1.1
dd 2.2
dd 2.2
dd 3.3
dpvector1 dq 1.1
dq 2.2
dpvector2 dq 3.3
dq 4.4
fmt1 db "Single Precision Vector 1: %f, %f, %f, %f", 10, 0
fmt2 db "Single Precision Vector 2: %f, %f, %f, %f", 10, 0
fmt3 db "Sum of Single Precision Vector 1 and Vector 2: %f, %f, %f %f", 10, 0
fmt4 db "Doule Precision Vector 1: %f, %f", 10, 0
fmt5 db "Doule Precision Vector 2: %f, %f", 10, 0
fmt6 db "Sum of Double Precision Vector 1 and Vector 2: %f, %f", 10, 0
section .bss
spvector_res resd 4
dpvector_res resq 4
section .text
global main
main:
push rbp
mov rbp, rsp
mov rsi, spvector1
mov rdi, fmt1
call printspfp
mov rsi, spvector2
mov rdi, fmt2
call printspfp
movups xmm0, [spvector1]
movups xmm1, [spvector2]
addps xmm0, xmm1
movups [spvector_res], xmm0
mov rsi, spvector_res
mov rdi, fmt3
call printspfp
mov rsi, dpvector1
mov rdi, fmt4
call printdpfp
mov rsi, dpvector2
mov rdi, fmt5
call printdpfp
movupd xmm0, [dpvector1]
movupd xmm1, [dpvector2]
addpd xmm0, xmm1
movupd [dpvector_res], xmm0
mov rsi, dpvector_res
mov rdi, fmt6
call printdpfp
leave
ret
printspfp:
push rbp
mov rbp, rsp
movss xmm0, [rsi]
cvtss2sd xmm0, xmm0
movss xmm1, [rsi+4]
cvtss2sd xmm1, xmm1
movss xmm2, [rsi+8]
cvtss2sd xmm2, xmm2
movss xmm3, [rsi+12]
cvtss2sd xmm3, xmm3
mov rax, 4
call printf
leave
ret
printdpfp:
push rbp
mov rbp, rsp
movsd xmm0, [rsi]
movsd xmm1, [rsi+8]
mov rax, 2
call printf
leave
ret
需要注意的几个指令如下:
movups: 移动未对齐的打包单精度;(u:未对齐unaligned;p:打包的packed;s:单精度single;)
addps: 打包单精度相加;
movss: 移动标量单精度;(s:标量scalar;s:单精度single)
cvtss2sd: 将标量单精度转换为标量双精度;(d:双精度double)