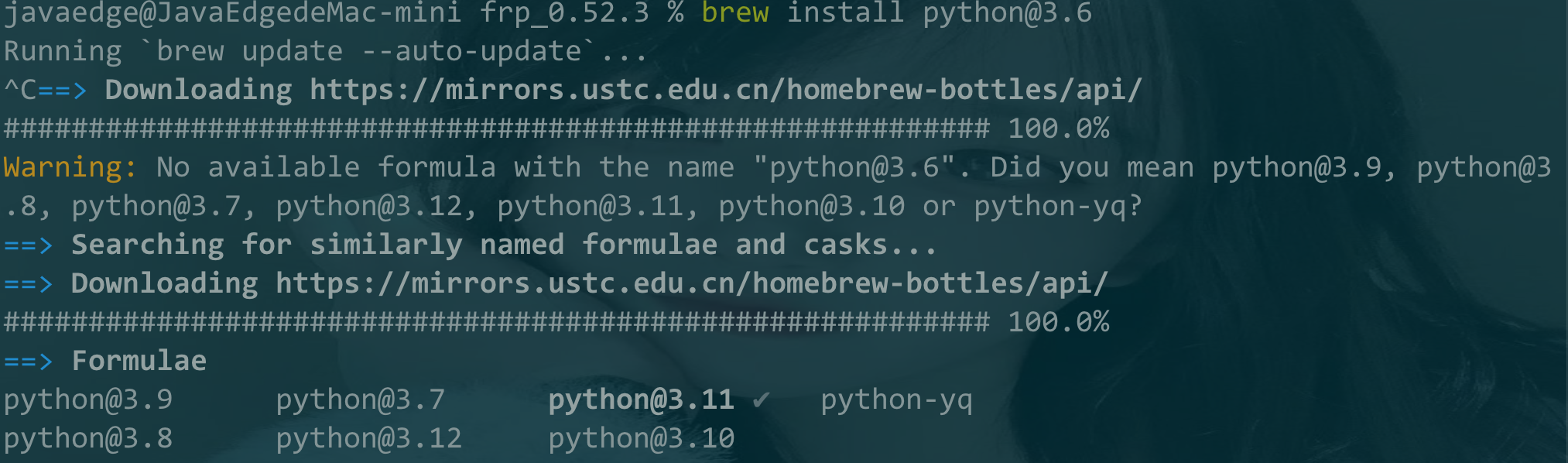
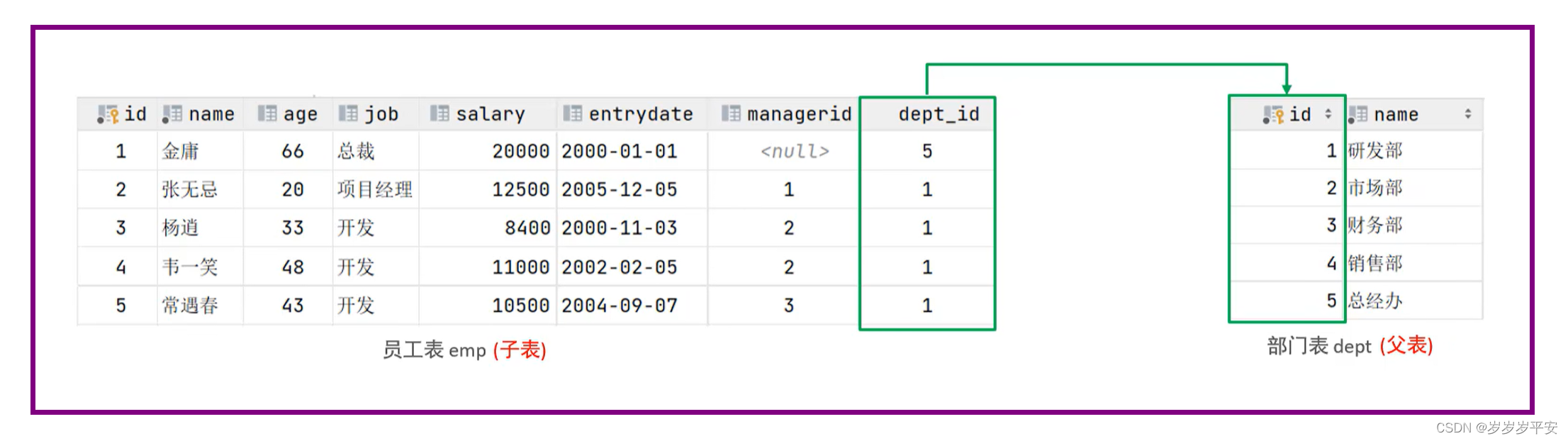
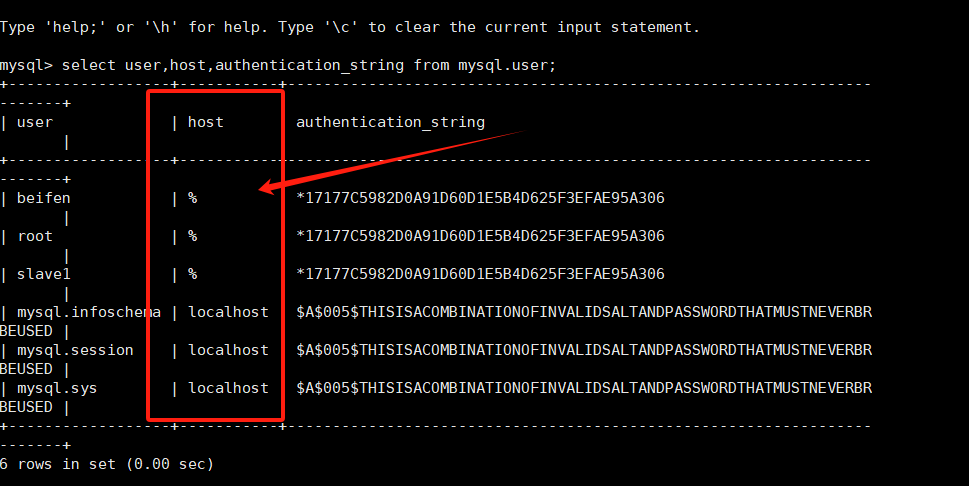
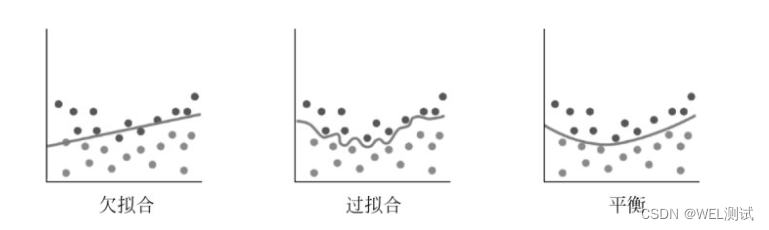
欠拟合
将训练损失和测试损失都比较大的拟合叫欠拟合,那么他的预测精度很低
1.一般出现在模型的复杂度小于数据本身的复杂度导致的,这个可能就是模型对数据的分布和实际数据分布之间的差异,这个就可能需要更换模型
2.还可能出现在梯度下降算法中,迭代次数少或者学习率低的情况,这个可以有挽留机会,通过增加次数、学习率就可以了
过拟合
训练损失小而测试损失大的情况叫过拟合
欠拟合就是模型过度拟合到观测数据中不具有普遍的部分,以至于在对未观测的数据标签进行预测时出现较大的偏差,可能出现在模型的复杂度大于数据的复杂度
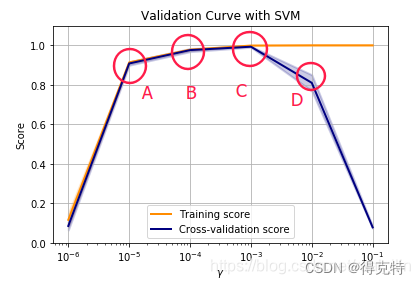
更一般的,欠拟合和过拟合取决于模型本身的复杂度
数据的模式
其实我们在监督学习中,标签y和变量x直接的关系就是所谓的模式记作f(x),机器学习的任务就是给出数据,找到这种模式
数据的噪声
是指数据点偏离数据模式的随机信息
正则化约束
过拟合的本质是由于模型的参数过于复杂,所以需要引入某种限制,防止过拟合的方向发展,这样的约束称为正则化。
在线性回归中如果数据N小于数据特征d就会出现过拟合就要在损失函数中加入一个正则项λ/2*||θ||^2,这称为L2范数,运用此方法的线性回归叫岭回归。此外还可以采用L0范数,衡量向量的非零元素个数,λ*||θ|| 这样的约束称为lasso回归。
超参数的特点
不通过模型优化而需要人为指定的参数就叫超参数,调整的过程叫调参
选择模型和调整参数的机器学习的必要步骤
数据集划分与交叉验证
为进一步消除数据分布的影响,在划分训练集和验证集时,采用随机划分、
交叉验证
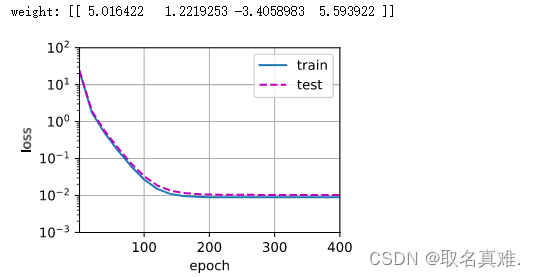
交叉验证就是将数据集分成k份,每一份单独训练,在i次训练中把第i份作为验证集,其余作为训练集,然后取平均损失。k一般取5-10,因为k小受随机性影响大,但是方差小,反之。




























![[CLIP] Learning Transferable Visual Models From Natural Language Supervision](https://img-blog.csdnimg.cn/direct/95a429cc263f45878b909a9e74f88aa6.png)