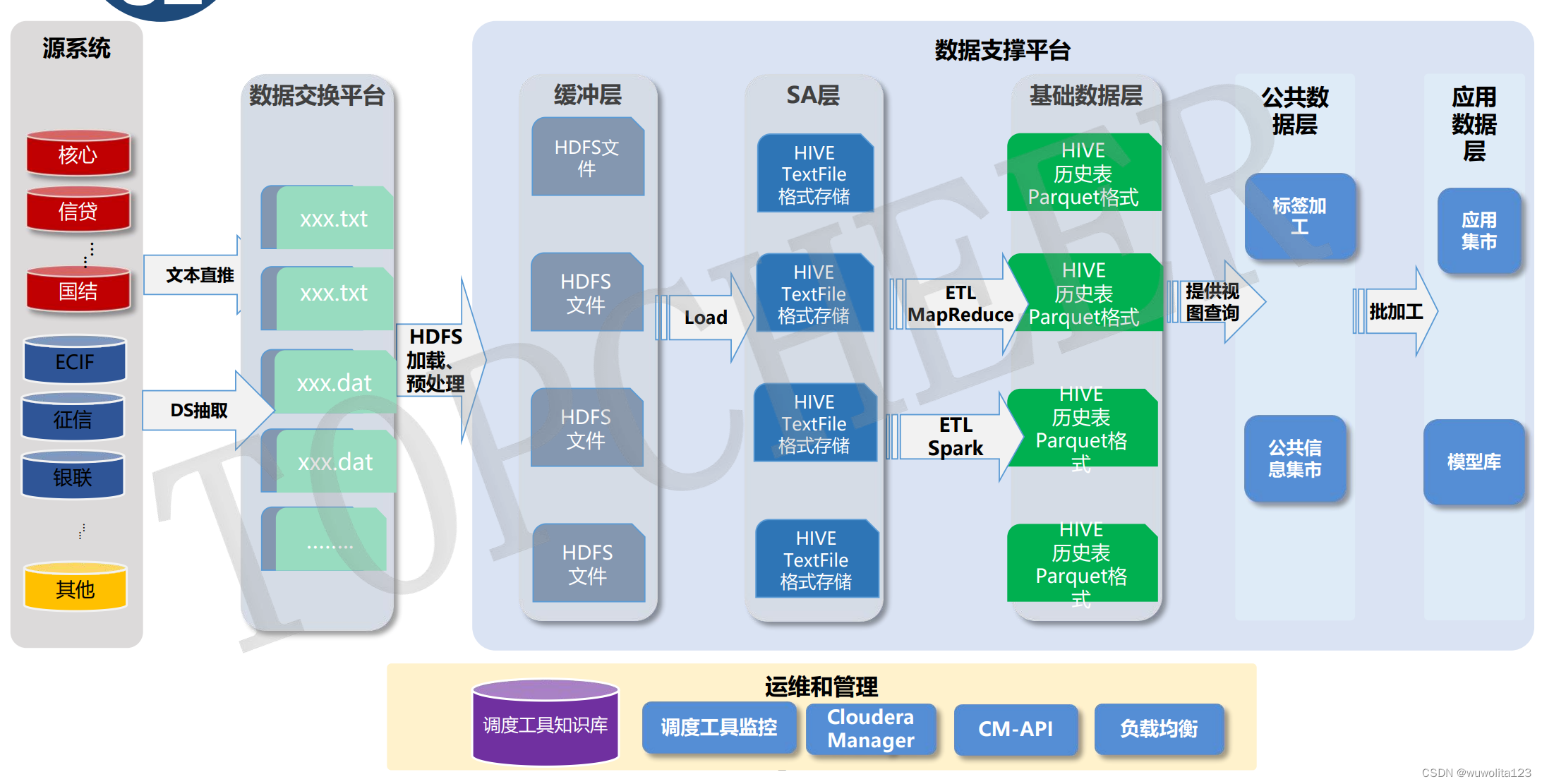
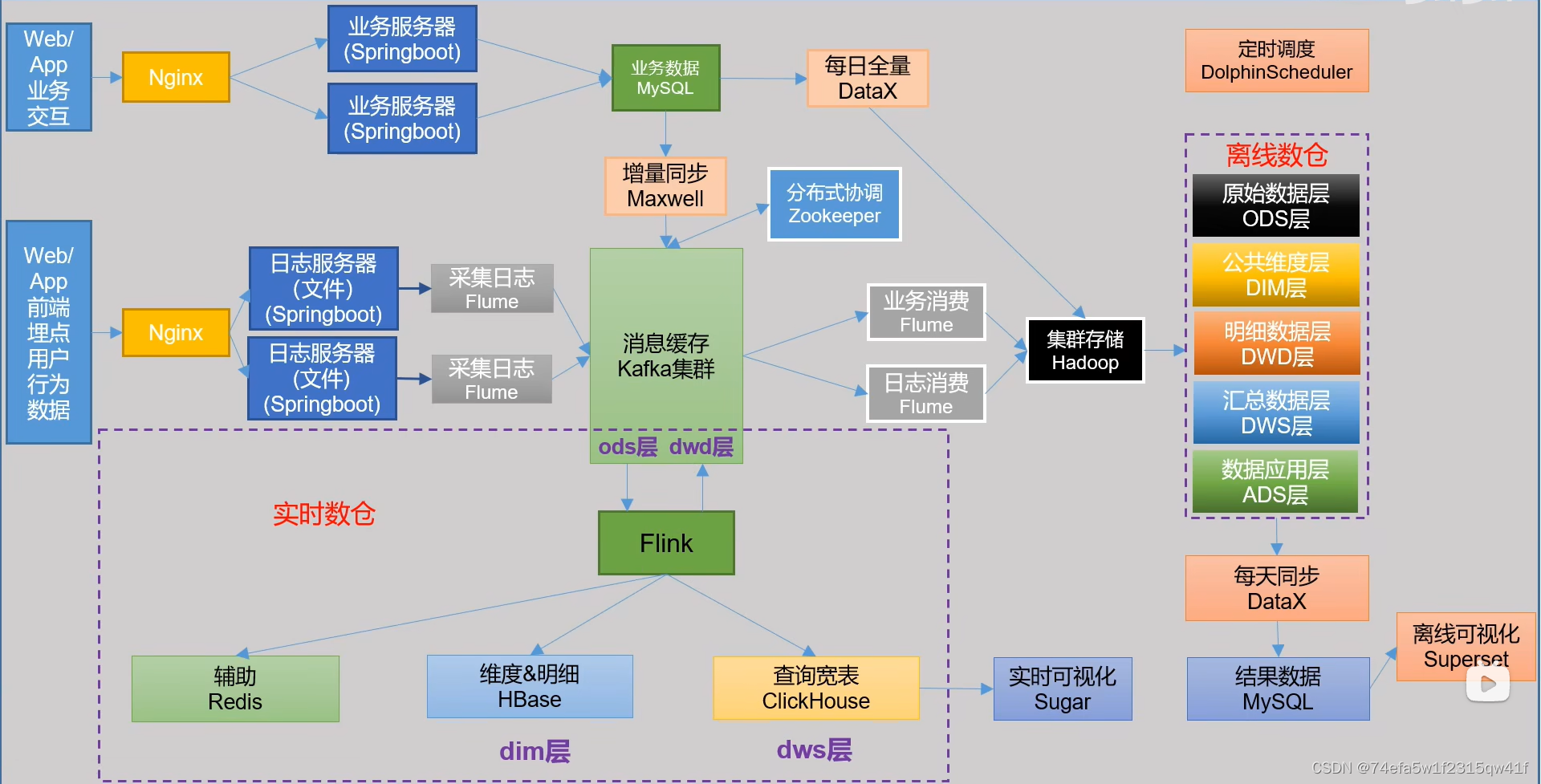
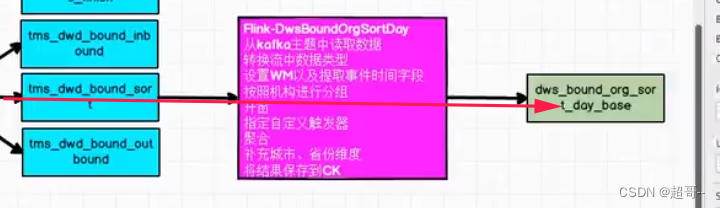
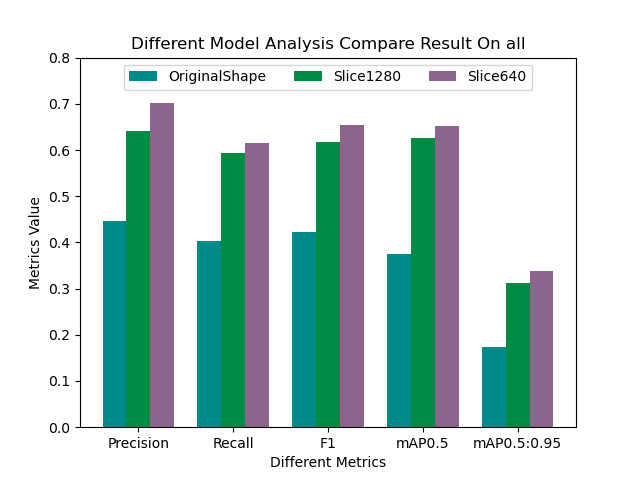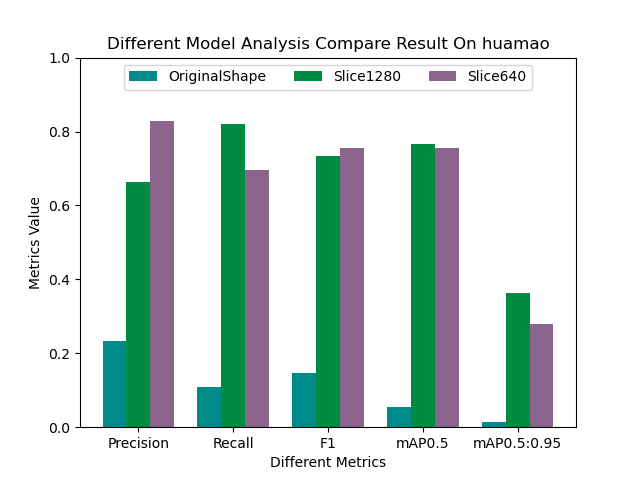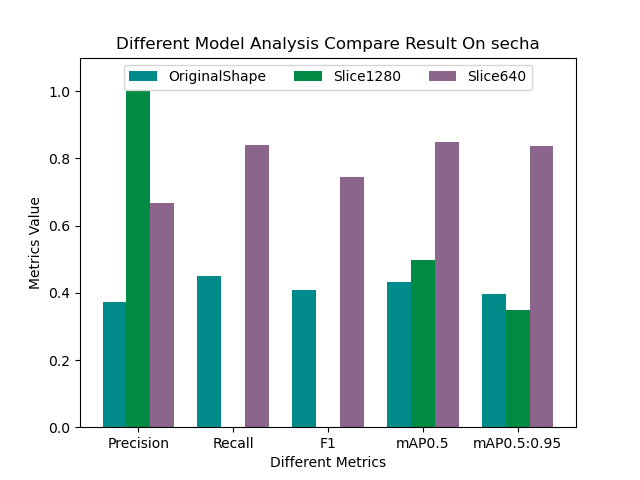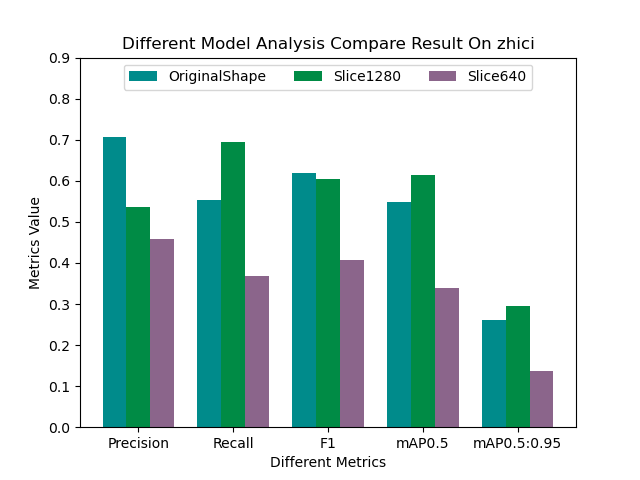
目前比较流行的实时数仓架构有两类,其中一类是以Flink+Doris为核心的实时数仓架构方案;另一类是以湖仓一体架构为核心的实时数仓架构方案。本文针对Flink+Hudi湖仓一体架构进行介绍,这套架构的特点是可以基于一套数据完全实现Lambda架构。实时数仓架构图如下:
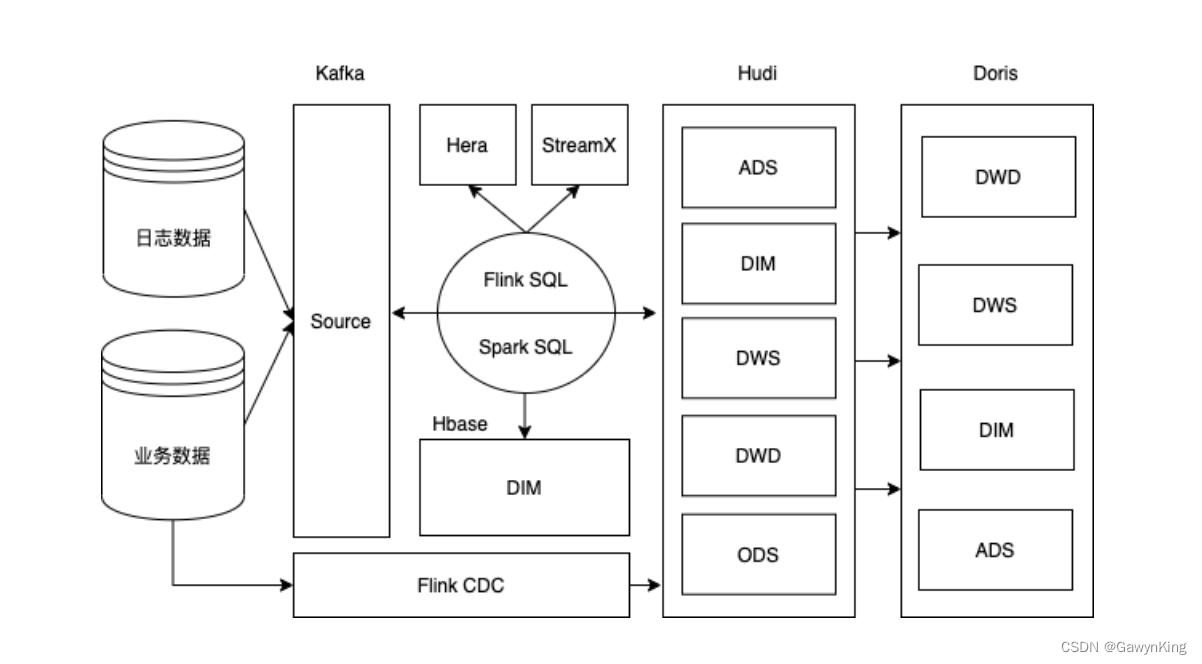
技术框架
Kafka:用于接入数据源;
Flink CDC:如果直接接入业务数据源可以考虑CDC方式,如果通过Kafka缓冲接入业务数据可以忽略;
Flink:用于数据ETL,包括接入数据、处理数据及输出数据全链路数据计算任务;
Spark:用于数据ETL,包括处理数据及输出数据全链路数据计算任务;
Hudi:湖仓一体数据管理框架,用来管理模型数据,包括ODS/DWD/DWS/DIM/ADS等;
Doris:OLAP引擎,同步数仓结果模型,对外提供数据服务支持;
Hbase:用来存储维表信息,维表数据来源一部分有Flink加工实时写入,另一部分是从Spark任务生产,其主要作用用来支持Flink ETL处理过程中的Lookup Join功能。这里选用Hbase原因主要因为Table的Hbase Connector支持异步IO功能。
Hera:调度系统,用来调度离线Spark任务;
StreamX:Flink任务管理工具,用于部署管理以及监控Flink实时任务;
数仓架构
采用维度模型标准三层架构,ODS/DWD/DWS/DIM/ADS,分层架构符合Kimball维度模型建仓指导原则。
ODS层:增量方式接入业务数据和日志数据,ODS层分区保留当日增量结果,包含备份和支持下游数据源功能;
DIM层:维表加工分为几种情况:
静态维表/转码表/字典表这些日常不怎么变化的直接加载到Hudi即可,用于flink数据处理;如果应用端需要依赖这类表,Doris也得同步存储一份;
普通维表数据由Flink完成实时任务加工,由Spark任务完成离线数据修复,同时为了维表Join,维表还需要同步hbase一份(原因可以参考笔者另外一篇博客《Flink基于Hudi维表Join缺陷分析及解决方案》),同时结果同步Doris,供终端引用。
DWD层:维度模型设计,采用事务表建模(目的尽量将单表数据设计关系降低到最低)、易于ETL实现;实时数据装载由Flink驱动,通过对ODS流进行Join、聚合和转行操作、以及对外部表以Lookup Join方式清洗数据(切记不能过分冗余维度数据,底层对数据做分离是核心设计思想,冗余越是过分、维护成本越高),结果保存Hudi;离线任务修复由Spark实现,操作同一份数据,ETL要做好时间限制条件,避免离线任务影响实时任务,同时结果数据同步Doris,供终端引用;
DWS层:非必要不要轻易跨业务过程合并数据,其他参考DWD设计思路。
ADS层:面向业务场景编程,一套数据产品对应自己的一套数据,这里一般有两种实现思路可以参考:
Flink/Spark驱动读取DWD/DWS/DIM数据加工ADS结果表,数据写入Hudi,同步Doris供下游引用;
StarRocks高版本支持物化视图功能,可以借助物化视图实现ADS层;
总结:无论是实时数仓还是离线数仓建设,问题根源一般来自于模型设计的不合理,要知道数据模型才是维度建模的灵魂,Kimball老爷子写了几百万字的著作,主要描述的是数据建模的思想。
Flink+Hudi实时数仓架构缺点
基于Hudi湖仓一体架构虽然实时性比离线数仓要高很多,但是对比纯实时数仓而言,其延迟性一般在分钟级(到终端引用可能要延迟10~15分钟时间),对于某些实时性要求较高场景并不适合。
常见问题
数据源保序任务:一般来说接入数据源很难完全避免乱序场景发生,这种情况有两种方案可以参考:
事实表按照业务过程建设,一般业务过程数据不存在更新所以单个key也不存在重复发射的情况,即使存在数据重发,也可以通过ETL规则提前规避掉,这种思路对于下游数据任务加工都比较友好。
针对接入数据按照
update_time保序,由于接入Append-Only流数据,通过保序任务会变成Retract流,这样后续依赖也要考虑回撤场景带来的问题。具体可以参考作者关于乱序场景的几篇文章。
实时UV/PV计算:去重计数指标一直依赖都是数据仓库设计领域的难题,由于本架构采用了doris,所以这部分指标加工如果没有特殊要求可以通过doris的bitmap实现;另一种实现思路是借助redis hyperloglog(由于改架构避免不了Spark修复数据情况,所以一定场景下是可以接受实时数据差异的)能力,通过自定义UDF函数实现UV计算。这两种思路是实时UV常用的解决思路。
历史实时数据对齐:如果底层面向业务过程设计,那么根据合理的时间戳属性,是可以严格区分历史数据和实时数据区别的,这种情况可以考虑通过离线数据补全缺失数据。这也侧面说明了模型设计的能力才是数据仓库的核心技能,其他方面的技能对于数仓建设的正面影响加到一起也不及模型设计能力的一部分。
Flink基于Hudi维表Join存在陷阱,详情请参看笔者另一篇博客《Flink基于Hudi维表Join缺陷分析及解决方案》。
总结
Flink和Hudi组合实现湖仓一体架构,目前也是业界讨论比较多的一套架构方案,这也得益于Flink和Hudi社区的快速发展,对于组件的特性支持越来越丰富。对于文中涉及到的一些技术点并没有展开发挥,这部分内容陆续会在博客的其他文章中继续讨论。如果你对实时数仓架构有独到的见解,欢迎留言讨论。