搜索了一下,大致有这些库能将PDF转txt
1. PyPDF/PyPDF2(截止2024.03.28这两个已经合并成了一个)pypdf · PyPI
2. PyMuPDF PyMuPDF · PyPI
3. PDFMiner (有5年没更新了,不建议使用)GitHub - euske/pdfminer: Python PDF Parser (Not actively maintained). Check out pdfminer.six.
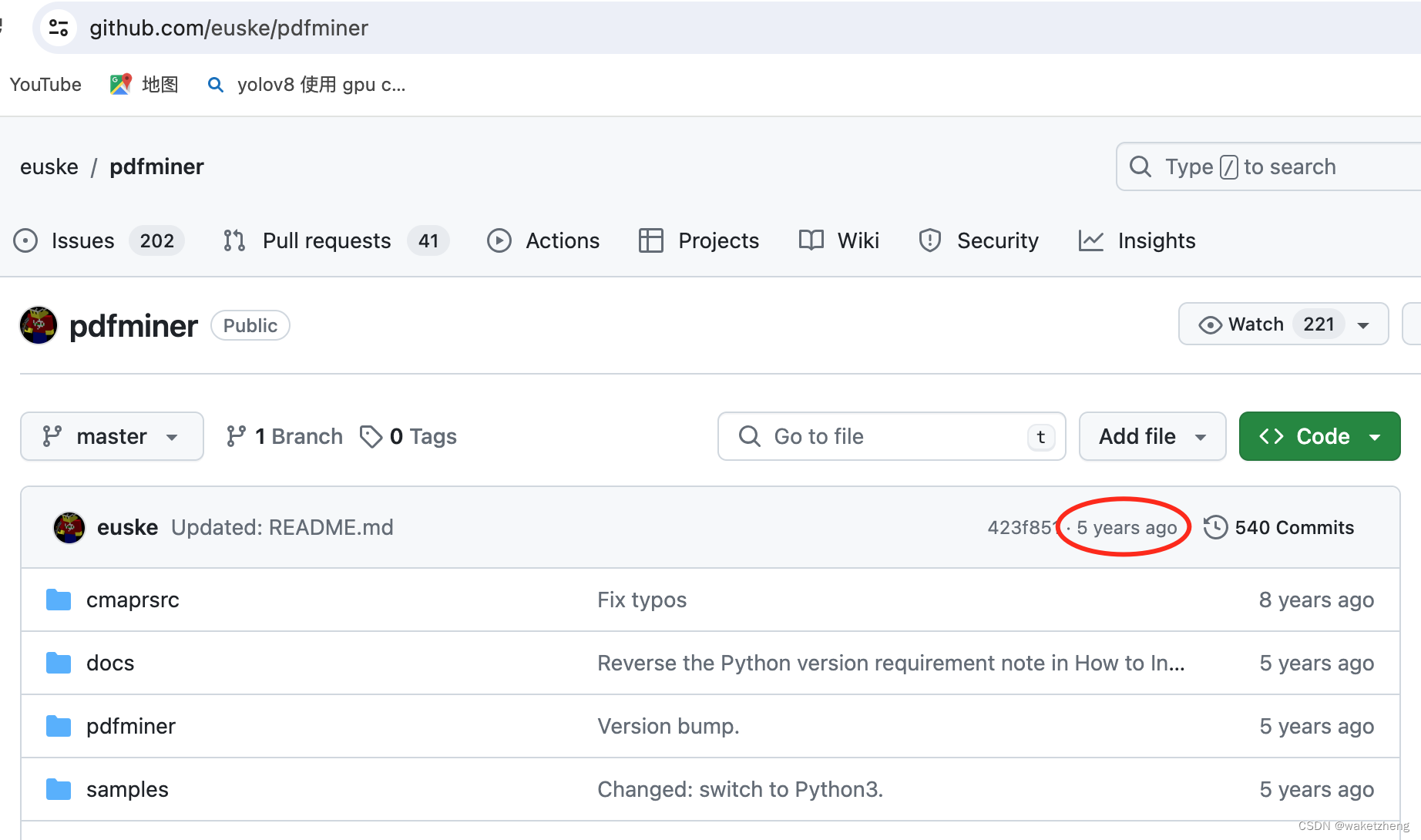
4. pdftotext (Mac系统没安装成功,故未试用) GitHub - jalan/pdftotext: Simple PDF text extraction
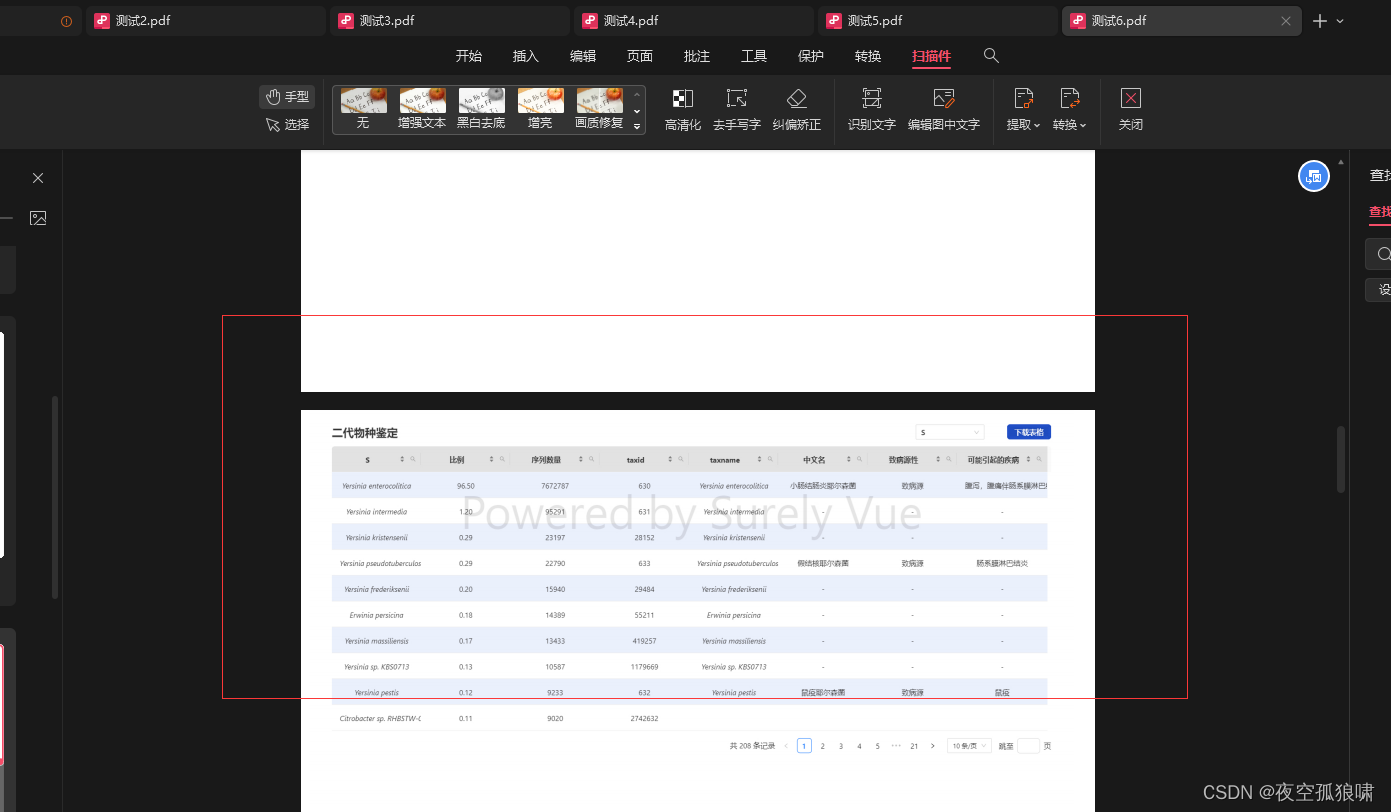
要转txt的PDF有一页内容如下:

其中PyPDF和pdfplumber的代码很相似都用extract_text, PyMuPDF则用get_text:
import pdfplumber
from pypdf import PdfReader
import fitz # PyMuPDF
fname = "26.pdf"
with pdfplumber.open(fname) as pdf:
print(len(pdf.pages))
for page in pdf.pages:
text = page.extract_text()#提取文本
print(text)
with open('1.txt', 'w') as f:
f.write(text)
pdf = PdfReader(fname)
print(len(pdf.pages))
for page in pdf.pages:
text = page.extract_text()
print(text)
with open('2.txt', 'w') as f:
f.write(text)
with fitz.open(fname) as pdf:
text = chr(12).join([page.get_text() for page in pdf])
with open('3.txt', 'w') as f:
f.write(text)执行结果如下(从左到右分别是pdfplumber/PyPDF/PyMuPDF)
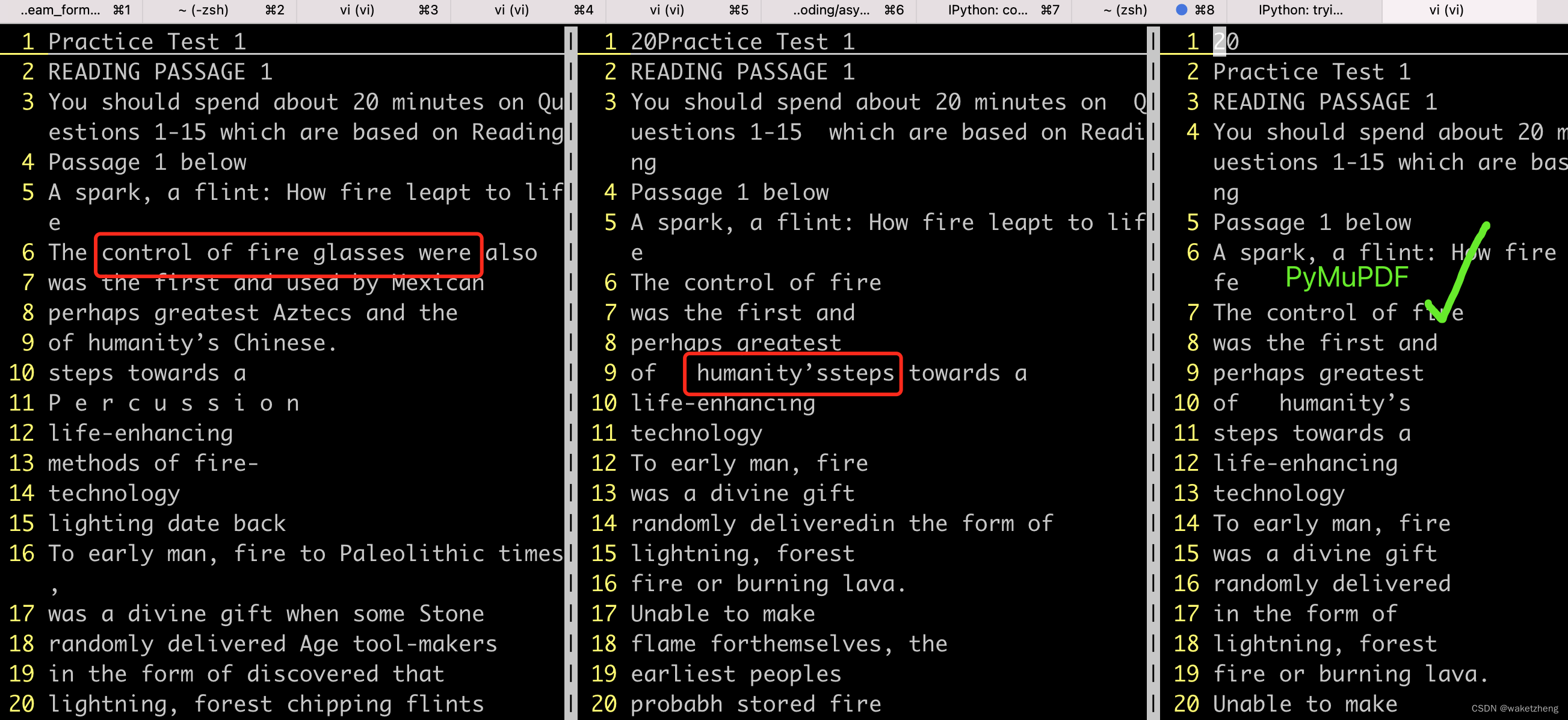
对比发现:
1. pdfplumber未能正确处理分栏
2. PyPDF 未能正确识别换行
综上,选择PyMuPDF用来提取PDF中的文字,做成脚本(pdf2txt.py)内容如下:
#!/usr/bin/env python
"""PDF转txt
Usage::
>>> python pdf2txt.py <pdf>
"""
import os
import sys
from pathlib import Path
# pip install PyMuPDF
import fitz # type:ignore[import-untyped]
def pdf2text(fname: str) -> str:
if "~" in fname:
fname = os.path.expanduser(fname)
with fitz.open(fname) as doc: # open document
text = chr(12).join([page.get_text() for page in doc])
return text
def main() -> None:
if not sys.argv[1:]:
if "PYCHARM_HOSTED" not in os.environ:
print(__doc__)
return
fname = input("请输入PDF文件路径:")
else:
fname = sys.argv[1]
text = pdf2text(fname)
new_name = Path(fname).stem + ".txt"
size = Path(new_name).write_bytes(text.encode())
print(f"Save to {new_name} with {size=}")
if __name__ == "__main__": # pragma: no cover
main()
























![Vue element-plus 导航栏 [el-menu]](https://img-blog.csdnimg.cn/direct/4d2a22b9811642d1896f40630f90bd3a.png)