瑕疵类的检测模型如:工业部件瑕疵、瓷砖瑕疵、PCB瑕疵、布匹瑕疵等等,在我们之前的博文中已经有过很多相关的开发实践了,这里就不再一一列举了,感兴趣的话可以直接搜索关键字信息博文内容即可一键直达。
因为本文的实验对象选择的是布匹瑕疵,所以下面简单列一下前文做的一些相关性的工作:
《布匹瑕疵检测实践大全,基于yolov5全系列模型[n/s/m/l/x]开发构建布匹瑕疵检测模型,对比分析各个模型性能差异》
《集成注意力机制基于YOLOv5开发构建布匹瑕疵检测识别系统》
《助力工业生产“智造”,基于YOLOv8全系列模型【n/s/m/l/x】开发构建纺织生产场景下布匹瑕疵检测识别系统》
《助力工业生产质检,基于YOLOv7【tiny/l/x】不同系列参数模型开发构建生产制造场景下布匹瑕疵缺陷检测识别分析系统》
《探索工业智能检测,基于轻量级YOLOv8开发构建焊接缺陷检测识别系统》
本文的主要目的倒不是说想要基于某个系列的模型做怎样的开发实践,我们这里的模型选择的也是比较经典或者说是稀疏平常的yolov5系列里面最为轻量级的n系列的模型。主要的工作在于想要对比分析下不同分辨率图像尺度数据下模型的效果,在我们前面的博文中大都是直接使用原始尺寸的数据来开发构建对应的检测模型的,因为瑕疵目标相对整体背景区域来说一般很小,且不同的瑕疵类别的数据分布可能十分不均衡,给模型的检测带来了很大的影响,这也是引导我们重新做本文研究工作的初衷,话不多说首先看下对比效果:
从上述整体的对比结果不难看出来:我们一共进行了三组对比实验,分别是:原始尺寸数据、1280尺寸数据和640尺寸数据,再小的话就失去意义了。
模型文件如下:
# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
# Parameters
nc: 15 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.25 # layer channel multiple
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# YOLOv5 v6.0 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 6, C3, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 3, C3, [1024]],
[-1, 1, SPPF, [1024, 5]], # 9
]
# YOLOv5 v6.0 head
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3, [512, False]], # 13
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3, [256, False]], # 17 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [512, False]], # 20 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, Concat, [1]], # cat head P5
[-1, 3, C3, [1024, False]], # 23 (P5/32-large)
[[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
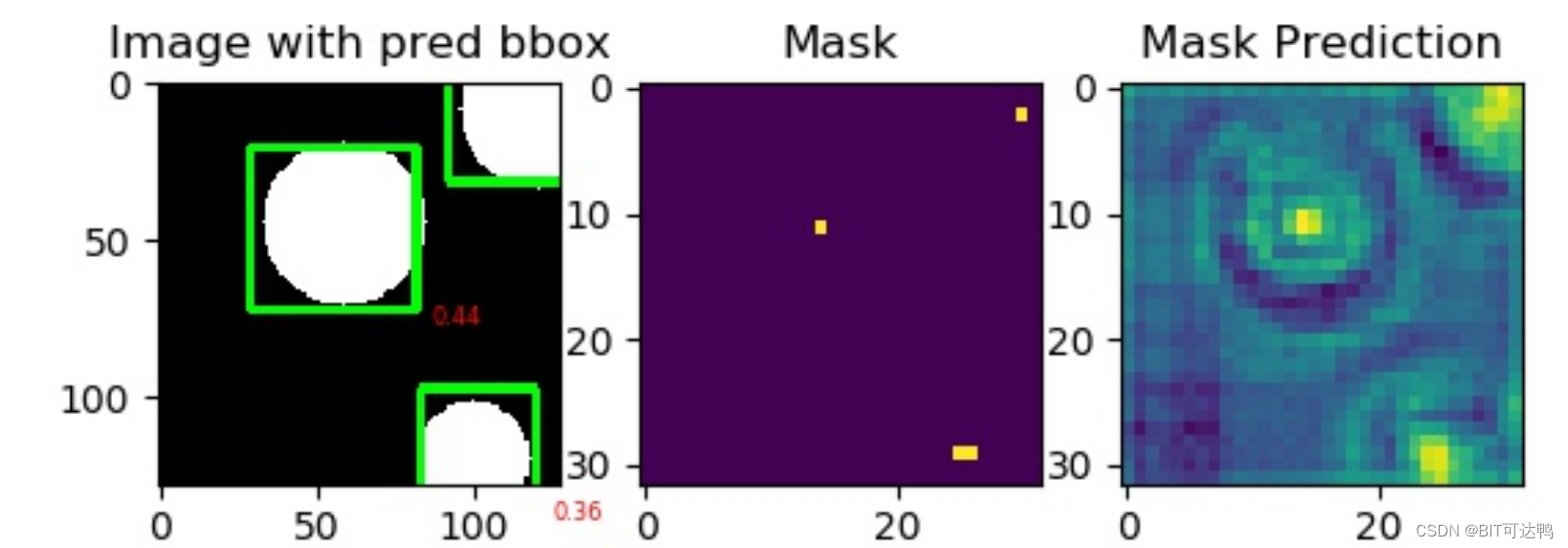
原始尺寸数据实例如下:

1280尺寸数据实例如下:

640尺寸数据实例如下:

实验阶段的话我们保持相同实验设置,等待全部训练完成后我们看下最终的对比效果。这里我们选择了:Precision、Recall、F1、mAP0.5和mAP0.5:0.95这5种主要的评价指标来作为模型的最终评价指标。
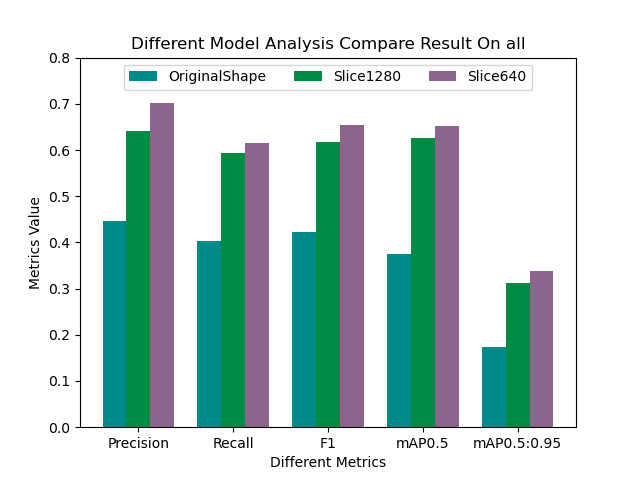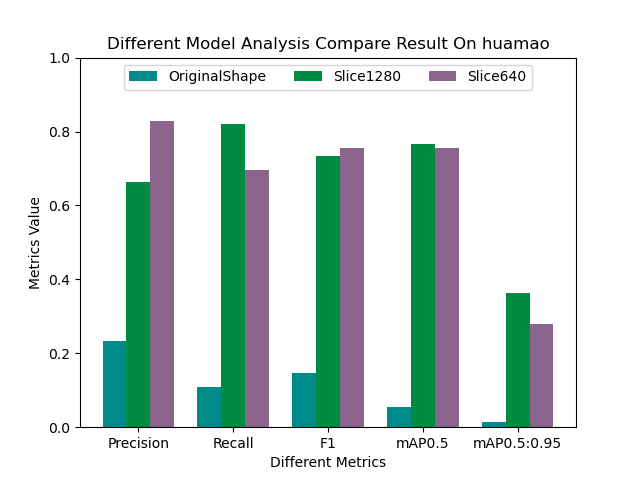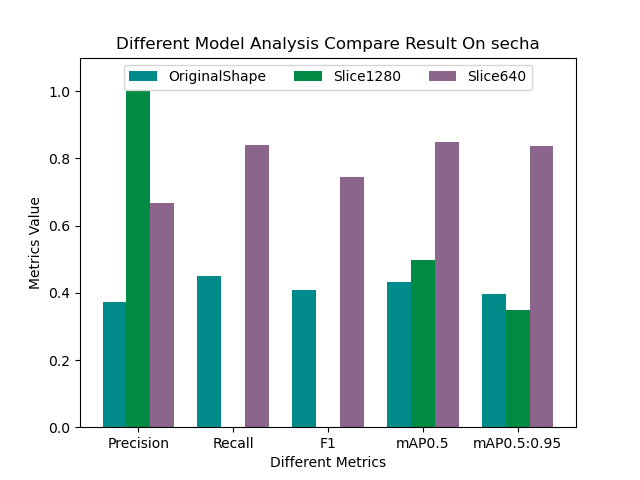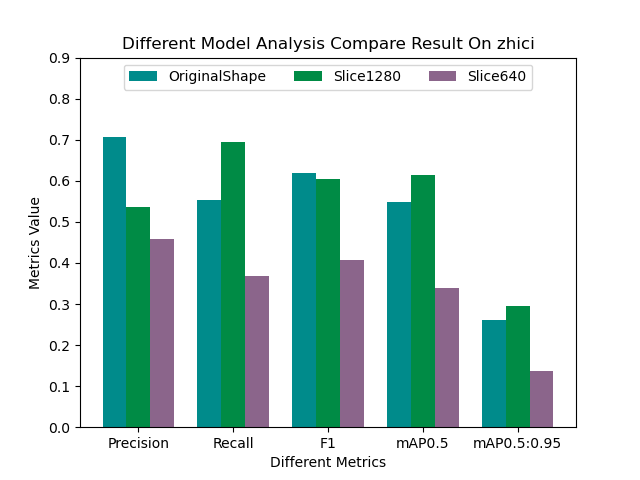
首先看下整体结果:

整体结果来看640尺寸的效果是最好的,而原始尺寸的效果是最差的。
接下来我们随机看下单个类别的效果:
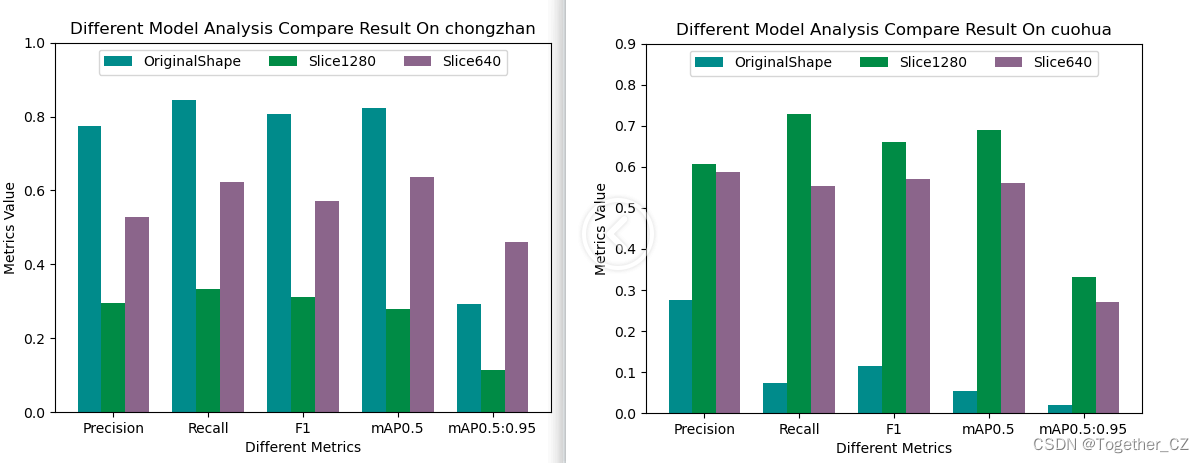
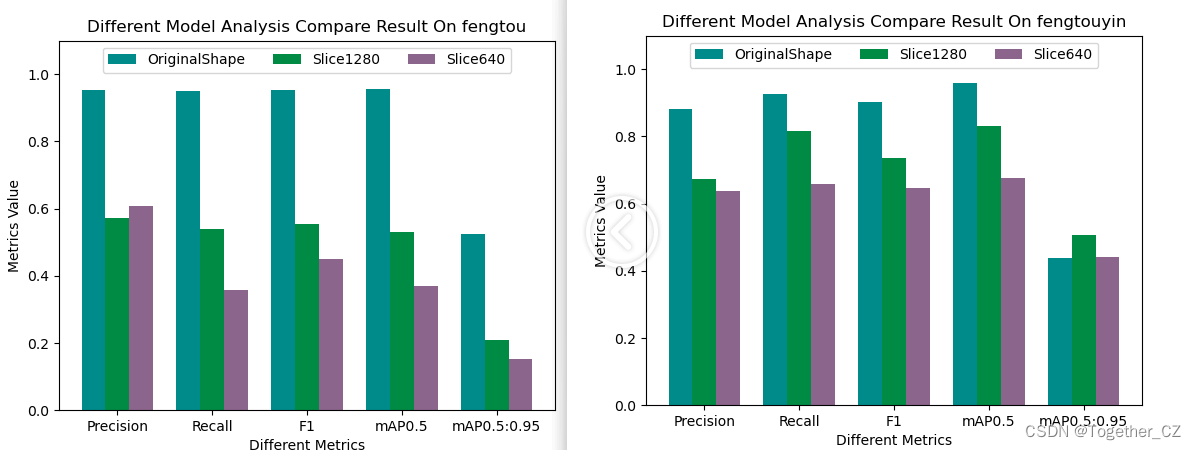
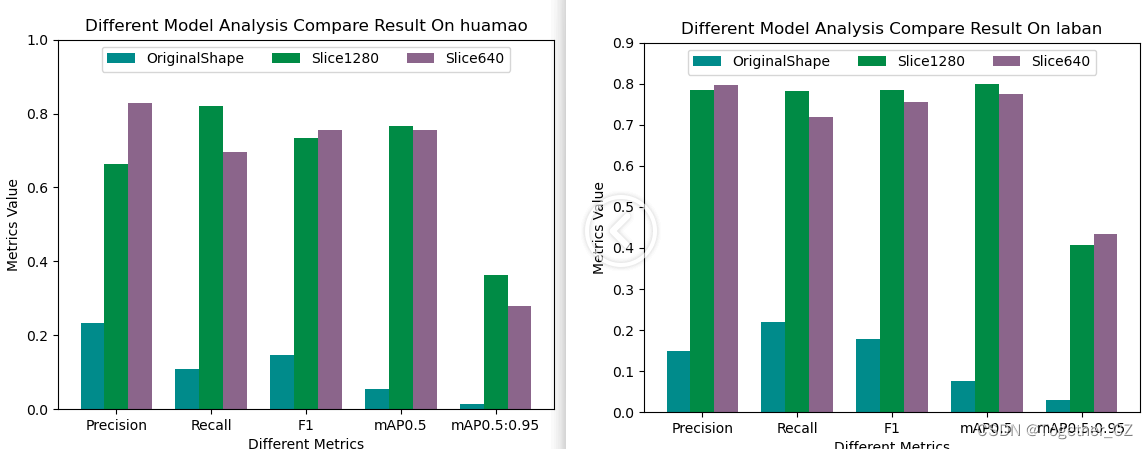
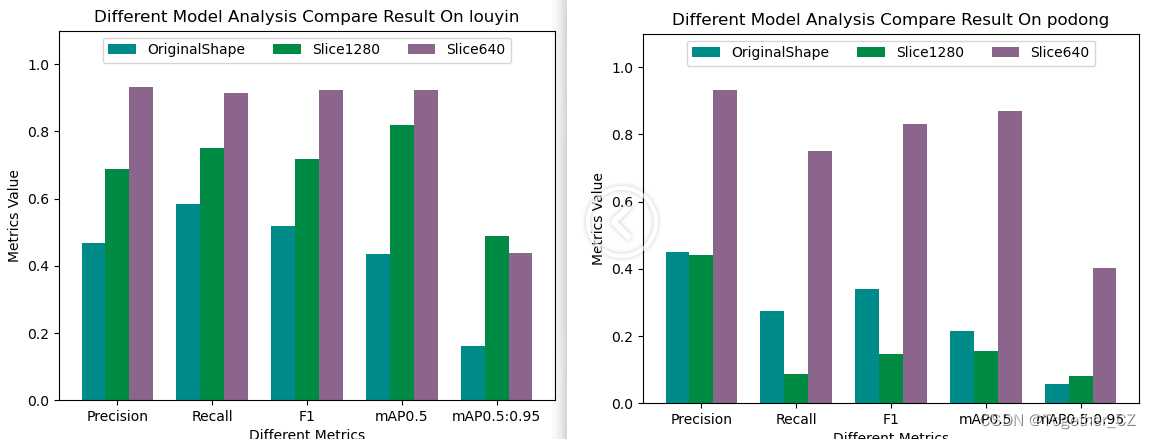
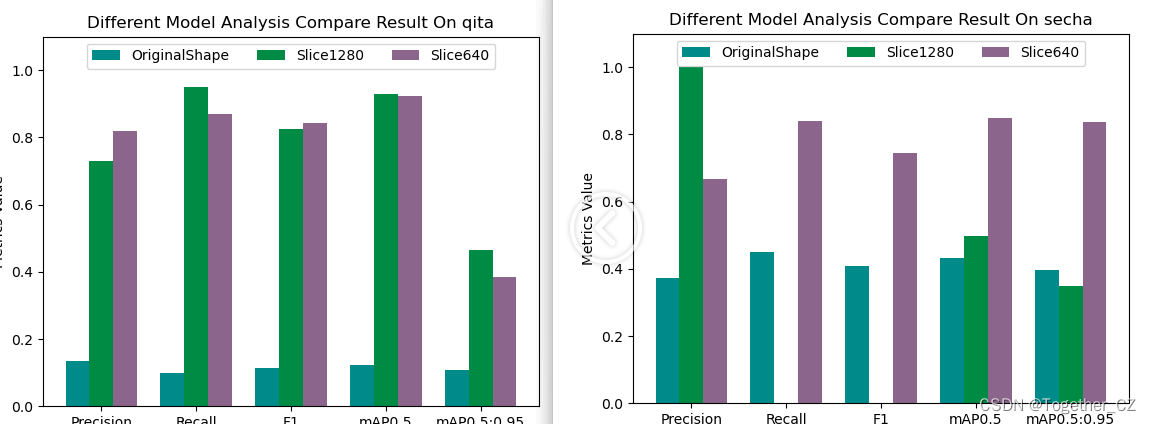
从上述随机查看的单个类别下的对比结果来看并没有呈现出来一边倒的情况,这个可能是由于不同类别下的数据分布是很不均衡的导致的,接下来我们看下数据类别分布情况:
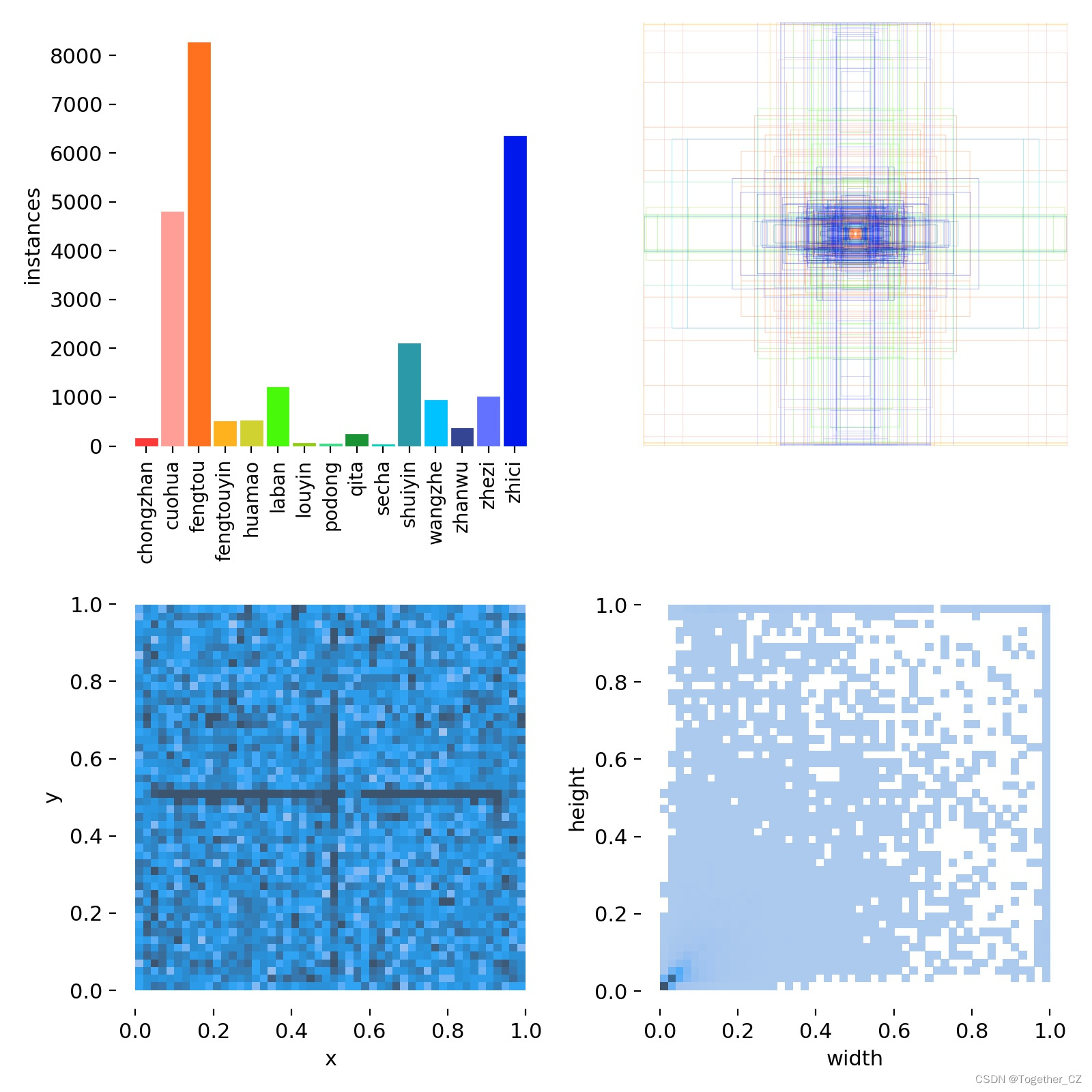
从数据类别分布直方图来看:不同类别目标的数据是很不均衡的,这也能理解前面的效果层面的问题了。
感兴趣的话也可以对照着这种方式在自己的个性化数据集上构建自己的检测模型进行相应的对比实验可能会有不一样的体验吧。

























![Vue element-plus 导航栏 [el-menu]](https://img-blog.csdnimg.cn/direct/4d2a22b9811642d1896f40630f90bd3a.png)



